scala不推荐写;作为一句代码的结束,能省就省
Scala的基本语法
Scala的变量定义
//定义变量用val或者var,区别,val相当于final修饰的,var是可变的,val地址值不能变
val valarg=12
var valargv=13
//scala里具有类型推断,所以可以不用写变量类型
// val 是线程安全的 , 在使用的时候效率更高
//完整定义变量
var valarga:Int=15Scala的类型
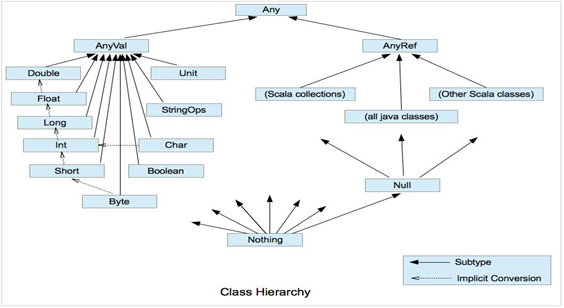
常用的类型同java一样,但是scala的类型都是包装类型,没有基本类型
所有的类都有一个共同的父类Any类型,都有一个共同的子类Nothing类型
类型可以分为AnyVal和AnyRef类型,Null类型是所有AnyVal的子类型
Unit是void在scala中的对应,只有一个实例()
scala的操作符
scala中的操作符和java类似,但是没有++,--等,只有+=,-=操作符
scala中的表达式都是方法,也就是说存在+(),-(),*()的方法,可以在Int类中看到
但是scala为了书写方便,使用了特定领域语言
所以在使用的时候可以是a + b这种常用的形式,也可以是a.+(b)这种调用方法的风格
val i: Int = valarg + 13
scala的条件表达式IF...ELSE
val a=if (valarg>10) true else false
//将自动返回分支的最后一句作为a的引用
val b=if (valarga<10) 100 else 0
//支持类型推断
val c=if (b==100)100 else "haha"
//支持混合类型
val d=if (a) "true"
//如果缺少分支,满足条件的时候直接返回():Unit类型,与下面一致
val f=if (!a) "false" else ()
scala的循环
println("-----")
for (i <- 1 to 10 ){print(i+" ")}//不指定步长,默认步长是1
println("--------")
for (i<-1 to 10 by 2){print(i+" ")}//指定步长,by关键字
println("--------")
//循环的时候筛选
for (i<- 1 until(100) if (i%20==0)){println(i)}
//1.until是不包括尾部的,类似于java中的循环控制
println("--------")
//循环数组
val arr=Array("z","v","b","n","y","t")
for (i<-arr){print(,i+" ")}//直接指定循环的对象
多层for
for (i<-1 to 10 by 2;j <1 to 10)多层for循环直接在
scala倒序遍历循环
//倒序,by为步长,reverse是反向
for (z<-(1 to 9).reverse){print(z+" ")}
println("")
for (j<-9 to 1 by -1){print(j+" ")}scala循环
for循环
//设置步长
for (i<- 10 to 90 by 10){
print(i)
}
//倒序,by为步长,reverse是反向
for (z<-(1 to 9).reverse){print(z+" ")}
println("")
for (j<-9 to 1 by -1){print(j+" ")}
println("")
val strings = Array("a","b","c","v","h")
for (v<-strings){
print(v)
}
println("_------")
val strgs = for (o<- strings.reverse) yield {o+"aha";o+" ";o}
for(msg<-strgs){println(msg)}
println("_------")
val ints = for (a<- 1 to 9) yield {a*10;a*1.1;print(a);a}
for (u<-ints){println(u)+ " "}yield关键字后面可以跟括号,但是要保证最后一句是收集的变量,上面的例子中去掉最后的a,就会为空
while循环
while循环和java语言基本一致
var n = 10
while(n<20){
println(n)
n+=1
}
var n = 10
do{
println("I first do")
n-=1
}while(n<10 && n>0)
Scala的方法和函数
在scala中函数和方法是不同的东西,方法是类似于java中的方法,函数是FunctionN的实例
scala方法定义的六种方式
//有参有返回值,类型*为可变参数
def method(arg:Double,arg2:Double):Double={arg2+arg}
//有参无返回值
def method2(arg:Double,arg2:Double):Unit={
print(arg+arg2)
}
//简写形式,如果逻辑很简单,那么{}可以省略
def method2b(a:Double,b:Double){}
def method2c(a:Double,b:Double)={}
//无参有返回值
method2c(12.13d,14.98)
def method3():Double={
1.22d
}
method3()
//简写形式,()无参可以省略,调用的时候也不能加
def m4 {print("a")}
m4//直接名字调用方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归方法,必须指定返回类型
scala定义函数的四种方式
val func1:(Double,Double)=>Double=(ar1:Double,arg2:Double)=>{ar1*arg2}
//原始方式
// 接收变量 名:函数签名=参数列表=>方法体
//变形
val func2:(Double,Double)=>Double=(arg1,arg2)=>{arg1+arg2}
//因为具有类型推断,而且前面已经声明了参数的类型,所以可以变形
//再简化
val func3=(ar1:Double,ar2:Double)=>{ar1-ar2}
//直接省略方法类型,自行推断,如同变量一样,直接赋值
//FunctionN定义
val fun4=new Function2[Double,Double,Double] {
override def apply(v1: Double, v2: Double): Double = v1/v2
}
//上面这种方式没有使用scala的语法糖,是最原始的写法,使用语法糖之后变成下面的形式
val fun5=new ((Double, Double) => Double) {
override def apply(v1: Double, v2: Double): Double = v1/v2
}嵌套的方法必须指定返回值类型 ,递归调用方法必须声明方法的返回值类型
Scala函数方法互相调用
因为上面提到的函数的第四种定义方法,可以看出,函数实际上是一个引用类型的变量,所以,函数是可以作为参数来回传递的,而且函数是有类型的
方法调用可以直接用方法名.apply的形式调用
比如上面的fun5.apply(12.5)也是调用方法
Scala函数作为方法的参数,及作为函数参数
// 定义一个函数
val function1:(Int,Int)=>Int=(a:Int,b:Int)=>{
a*b
}
//定义一个方法
def method1(arg1:Int):Int={
arg1*10
}
def method2(agr:Int)={
method1(agr)//方法里面调用方法
function1(agr,agr*2)//方法里面调用函数
}
val function2=(d:Int)=>{
function1(d,10)//函数调用函数
method2(d)//函数调用方法
}
//定义一个方法,参数类型中包括一个函数类型
def method(arg:Double,f1:Double=>Double):Double={f1(arg)}
val res= method(38.98, m => m * m)
//将函数作为参数传入方法中
//定义一个接收函数类型的函数
val re2=(ag:Double,af:Double,f:(Double,Double)=>Double)=>{
f(ag,af)
}
val d = re2(12.32,34.23,(a,b)=>a/b)Scala中方法作为方法参数及作为函数参数传递
//首先定义一个方法
def method2(arg:Double,arg2:Double):Double={
arg+arg2
}
//将方法转换成函数
val f=method2 _ //注意中间有空格
//将方法转换成函数
//定义一个方法(),三个参数,前两个作为输入,调用第三个函数参数
val functiont=(a:Double,b:Double,f:(Double,Double)=>Double)=>{
f(a,b)
}
//这里使用方法名也可以,默认会加上 _,可以简化
val d = functiont(12.32,123.54,method2)
println(d)方法也可以通过参数传递,也可以通过类名点的方式调用
方法可以通过方法名_的形式转换成函数
所谓的方法转换函数,其实是new FunctionN的形式,创建了一个函数实例,再通过函数实例调用了这个方法,通过CallByName的形式进行传递
方法作为方法和函数的返回值.......留坑
集合
scala中的集合类型分为两种:
1.可变集合
import scala.collection.mutable
2.不可变集合
import scala.collection.immutable
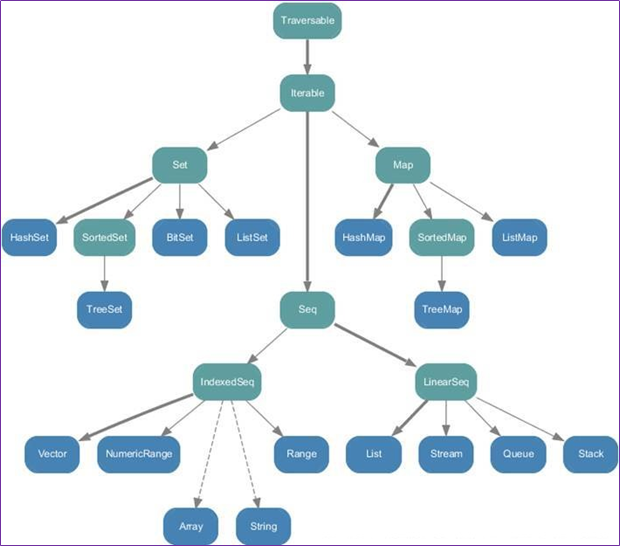
一,序列
数组
序列就是有顺序的集合,例如Array,String,List
不可变数组Array,不可变数组的长度不可变,但是数组内的值是可变的
import scala.collection.mutable
import scala.collection.immutable
//数组定义
val array: Array[Any] = Array("hshs",21.3,22,'d',true)
//通过静态初始化
val ints: Array[Int] = Array[Int](12,23,54,65)
//指明实例类型
//数组中的特有的方法
ints.min
ints.max
val i = ints.apply(1)//获取第n个数组元素
println(i)
val head = ints.head//头元素
println("head"+head)
val tail = ints.tail//尾部
println("tail"+tail.toBuffer)//tail是尾部,除了第一个是头,后面都是tail的范围
val last = ints.last//最后一个
println("last"+last)
val list = ints.toList//转换为list
println(list.toBuffer)
//排序
val sorted = ints.sorted
val intss = ints.:+(12)
println(intss.toBuffer)
val buffer: mutable.Seq[Int] = ints.toBuffer//直接tobuffer就转化为可变数组了可变数组ArrayBuffer
可变数组的长度和值都是可变的
//导入可变数组的依赖
import scala.collection.mutable.ArrayBuffer
val arrays =ArrayBuffer[Int](12,32,43,54,65,23)
arrays +=12//添加元素
arrays -= 12 //删除元素
arrays :+ 110//尾部添加
888 +: arrays //尾部添加
val array2 = ArrayBuffer(12,234,45345,56463,34534,1234)
arrays ++=array2 //两个数组拼接
println(arrays.toBuffer)List
不可变List,长度不可变,内容不可变
list数据长度可以添加,但是是添加到新的集合中,原来的list中的长度和数据不发生改变
val listarr = List(12,23,43,54,23,5)
listarr :+ 12
//list数据长度可以添加,但是是添加到新的集合中,原来的list中的长度和数据不发生改变可变ListBuffer
长度可变,数据可以变化
import scala.collection.mutable.ListBuffer
val listints = ListBuffer(12,342,4536,56,234,1,23)
val functionToInts = listints.sortBy(x=>x)
val unit = listints.insert(3,23,123,4323)
//内容可以修改,长度可以改变
println(listints.toBuffer)
println(functionToInts.toString())拼接两个list用++=,
取两个list的差集用--=
二.Set
set集合可以实现去重,Set无序,不能保证维持插入顺序
三,Map
Map实际上就是对偶元组的list
map的定义
val userMap = Map[String,Int](("zhangsan",12),("lisi",13),("wangwu",15),("zhaoliu",16))
val userinfo = Map[String,Double]("zhangsan"->14.23,"wangwu"->14.32,"lisi"->213.43,"zhaoliu"->90.21)
scala的map的五种遍历方式
for (elem <- userMap) {println(elem._2 + elem._1 + "") }
for (elem <- userMap.keys) {println(elem+userMap.get(elem))}
for (elem <- userMap.values) {println(elem)}
//map转成list或者转成Array遍历
for (elem <- userMap.toList) {println(elem)}
for (elem <- userMap.toArray) {println(elem)}元组
元组的特点:1,长度和内容一但确定不可变 2._通过下划线加序号的方式获取,元组的序号从一开始,3.最多只能存22个
对偶元组:类似于key:value的形式
//定义一个元组
val tp = new Tuple3(1,3,4)
val tuple = new Tuple4[String,Int,String,Double]("age",12,"hight",177.23)
val value = tuple._1//获取元组第一个元素 (_1: T1, _2: T2, _3: T3, _4: T4) 可以看到这是变量名
//定义对偶元组
val tupleDuiOu=(("age",12),("hight",177.23),("name","zhangsna"))
val swap = tupleDuiOu._1.swap
println(swap)
下面的方法是有层次和继承关系的

scala常用的集合方法
具有Iterable特质的集合类的方法(包括Set,Map,Seq)等

scala常用方法使用
/**
* 可迭代集合(包括seq,list,set,map等)方法,集合框架的第二特质
* 特质,也就是具有特殊的性质,类似于java中的接口
* 这里主要是用的Array,Array集合长度不能变,集合内的值可以变,所有操作这些方法的时候就会生成新的array
* 原因是这里使用的是不可变集合,以下的方法在可变集合中同样存在
* 每行都会附上执行结果
*
*/
/**
* 可迭代集合(包括seq,list,set,map等)方法,集合框架的第二特质
* 特质,也就是具有特殊的性质,类似于java中的接口
* 这里主要是用的Array,Array集合长度不能变,集合内的值可以变,所有操作这些方法的时候就会生成新的array
* 原因是这里使用的是不可变集合,以下的方法在可变集合中同样存在
* 每行都会附上执行结果
*
*/
object CollectionMethodDemo {
def main(args: Array[String]): Unit = {
// 解释:_ 代表的是集合中的当前映射元素,例如foreach中_ 就代表每一个被循环对象的元素,和java中的this理念一样,但是this指的是对象,这里_ 代表的是元素
// 注意 _ 后面要跟空格
//forall方法,如果所有元素满足就返回true,否则返回false
val arr = Array(1,2,3,4,5,6,6,7,8,9)
println(arr.forall(_< 10))//结果为true
//foreach,循环遍历所有元素
arr.foreach(println(_))
//groupby,根据某种规则分组,这里是奇偶分组
val re =Nil
val unit = arr.groupBy(_%2).toArray
for (elem <- unit) {
println(elem._2.toBuffer)
//ArrayBuffer(1, 3, 5, 7, 9)
//ArrayBuffer(2, 4, 6, 6, 8)
}
//hasDefiniteSize,测试集合是否有限,对Stream和iterator,返回false
println(arr.hasDefiniteSize)//true
//head,返回第一个元素
println(arr.head)//1
//last
println(arr.last)//返回最后一个元素
//headOption
println(arr.headOption)//如果存在返回some,不存在返回None
//init,返回集合中除去最后一个元素的其他所有元素
println(arr.init.toBuffer)//ArrayBuffer(1, 2, 3, 4, 5, 6, 6, 7, 8)
//新定义一个array
val aray = Array(1,2,6,7,8,9)
//intersect,求两个集合的交集
println(arr.intersect(aray).toBuffer)
//isEmpty,判断集合是否为空
println(arr.isEmpty)//Some(1)
//lastOption,存在最后一个元素返回some,不存在返回None
println(arr.lastOption)//Some(9)
//map,将元素根据某种规则收集到新的集合中
val doubles = arr.map(_*2).map(_*1.1)
println(doubles.toBuffer)//ArrayBuffer(2.2, 4.4, 6.6000000000000005, 8.8, 11.0, 13.200000000000001, 13.200000000000001, 15.400000000000002, 17.6, 19.8)
//max,最大值
println(arr.max)//9
//min最小值
println(arr.min)//1
//判断是否不为空
println(arr.nonEmpty)//true
//par,返回一个集合的并行实现
println(arr.par)//ParArray(1, 2, 3, 4, 5, 6, 6, 7, 8, 9)
//根据谓词条件,将集合分成几份
val tuple = arr.partition(_>5)
println(tuple._2.toBuffer+""+tuple._1.toBuffer)//ArrayBuffer(1, 2, 3, 4, 5)ArrayBuffer(6, 6, 7, 8, 9)
//product,返回集合中所有的元素乘积
println(arr.product)//2177280
//reduce,聚合操作
println(arr.reduce(_ * _))//2177280
//reduceLeft,从左往右,叠加操作
println(arr.reduceLeft(_ - _))//-49
//reduceRight,从右往前
println(arr.reduceRight(_ - _))//-5
//这里可以看出,两个数字不一样,主要是因为叠加的顺序不一样,
//用一个少一点的集合说明一下
val litArr = Array(1,2,3,4)
println(litArr.reduceRight(_ - _))//-2====((4-3)-2)-1
println(litArr.reduce(_ - _))//-8默认是reduceLeft
println(litArr.reduceLeft(_ - _))//-8//1-2-3-4=-8
//reverse,返回反转后的集合
println(arr.reverse.toBuffer)//ArrayBuffer(9, 8, 7, 6, 6, 5, 4, 3, 2, 1)
//size,返回集合的长度
println(arr.size)//10
//slice,返回集合中固定位置的元素
println(arr.slice(2, 7).toBuffer)//ArrayBuffer(3, 4, 5, 6, 6)
//sortWith,返回通过boolean表达式的比较
println(arr.sortWith((a, b) => a > b).toBuffer)//(9, 8, 7, 6, 6, 5, 4, 3, 2, 1)
//span,返回两个集合,一个是现有的,一个是删除的
val ardrop = arr.drop(3).span(_%2==0)
println(ardrop._1.toBuffer + "" + ardrop._2.toBuffer)//ArrayBuffer(4)ArrayBuffer(5, 6, 6, 7, 8, 9)
//splitat,从指定位置切分出一个集合
val tuple2: (Array[Int], Array[Int]) = arr.splitAt(5)
println(tuple2._1.toBuffer + " " + tuple2._2.toBuffer)//ArrayBuffer(1, 2, 3, 4, 5) ArrayBuffer(6, 6, 7, 8, 9)
//sum
println(arr.sum)
//tail,返回除了第一个元素(head)之外的其他元素
println(arr.tail.toBuffer)//ArrayBuffer(2, 3, 4, 5, 6, 6, 7, 8, 9)
//take,返回前n个
println(arr.take(6).toBuffer)//ArrayBuffer(1, 2, 3, 4, 5, 6)
//takeWhile,返回符合boolean的
println(arr.takeWhile(_ < 8).toBuffer)//ArrayBuffer(1, 2, 3, 4, 5, 6, 6, 7)
//union,返回两个集合的并集
println(arr.union(aray).toBuffer)//ArrayBuffer(1, 2, 3, 4, 5, 6, 6, 7, 8, 9, 1, 2, 6, 7, 8, 9)
//unzip,留坑
//zip,留坑
//view,返回一个集合的视图
println(arr.view.toBuffer)
//zipWithIndex,返回集合的元组,(元素,索引)
println(arr.zipWithIndex.toBuffer)//((1,0), (2,1), (3,2), (4,3), (5,4), (6,5), (6,6), (7,7), (8,8), (9,9))
val list = List(1,23,4,5,6,653,23,14)
//将集合中的拼接转换成String
println(list.mkString)
//scan
//遍历每个元素,将执行(初始值)(逻辑)的方法
println(list.scan(11111)(_ + _).toBuffer)
}
}
Iterable特质的操作符

scala集合框架操作符方法
def main(args: Array[String]): Unit = {
//定义两个集合
val arr = Array(1,2,3,4,5,6,6,7,8,9)
val aray = Array(1,2,6,7,8,9)
//collect,涉及偏函数,留坑
//count,返回集合中满足谓词的计数
println(arr.count(_ > 5))//5
//diff,两个集合中的不同元素
println(arr.diff(aray).toBuffer)//(3, 4, 5, 6)
//drop返回集合中去除前n个的集合
println(arr.drop(3).toBuffer)
//drop while,这个方法是从前往后删除,知道不满足条件就不删除了
val re1: Array[Int] = arr.dropWhile(_<4)//(4, 5, 6, 6, 7, 8, 9)
println(re1.toBuffer)
//exists,只有所有的元素都满足条件的饿时候才返回true
println(arr.exists(_ < 120))//true
//filter,返回满足谓词判断的所有元素
println(arr.filter(_ % 2 == 0).toBuffer)//(2, 4, 6, 6, 8)
//filterNot,返回谓词判断为false的元素
println(arr.filterNot(_ > 5).toBuffer)//(1, 2, 3, 4, 5)
//find,找一个符合谓词匹配的
println(arr.find(_ % 2 == 0).toBuffer)//(2)
//flatten,压缩,将两层变成一层,注意只能解开一层
val array = Array(arr)
println(array(0).toBuffer)//ArrayBuffer(1, 2, 3, 4, 5, 6, 6, 7, 8, 9)
println(array.flatten.toBuffer)//(1, 2, 3, 4, 5, 6, 6, 7, 8, 9)
//flatMap,先map,然后再拍平
val arrayarray = Array(Array(1,2,3,4,5),Array(9,8,7,6))
println("")
for (elem <- arrayarray) {print(elem.toBuffer+"----")}//ArrayBuffer(1, 2, 3, 4, 5)----ArrayBuffer(9, 8, 7, 6)----
println("")
println(arrayarray.flatMap(_.filter(_ % 2 == 1)).toBuffer)//ArrayBuffer(1, 3, 5, 9, 7),过滤出来每个arr中的偶数,然后将两个arr拍平
//foldLeft,柯里化方法,前面0,是初始值,后面是前后相加,默认是左叠加操作,从左开始
println(arr.fold(0)((a: Int, b: Int) => a - b))
println(arr.foldLeft(0)((a: Int, b: Int) => a - b))
println(arr.foldRight(0)((a: Int, b: Int) => a - b))//从右开始
}可变集合的操作符

def main(args: Array[String]): Unit = {
import scala.collection.mutable.ArrayBuffer
//默认是不可变集合,所以导入可变集合
val arr = ArrayBuffer(1,3,4,5,6,2,7,8,9)
val arr2 = ArrayBuffer(7,8,9)
//将元素添加到集合中
arr += 0
println(arr.toBuffer)
arr.+=(12,22,43,10)//添加多个
println(arr.toBuffer)
//将集合中的元素添加到该集合中
arr.++=(arr2)
println(arr)
//将集合中的元素删除,如果有重复的删除第一个
arr -= 8
println(arr)
arr.-=(7,8,9)
println(arr)
//去除集合a中与集合b相同的值
arr --=arr2
println(arr)
arr++=arr2
println(arr)
//赋值给第n个元素
arr(5)=666
println(arr)
arr.remove(2,2)
println(arr)//包头不包尾
arr.clear()
println(arr)
}不可变集合的操作符

def main(args: Array[String]): Unit = {
//其他的方法和可迭代集合中的方法一致
val list = List(1,23,4,5,6,653,23,14)
val lis2 = List(1,223,45,6,653,2314)
list :+ 7 //将7添加到list尾部中
println(list)
8 +: list //将8添加到list的头部
println(list)
val addints = list ++ lis2//将lis2和list进行合并后形成新的集合
println(addints)
}scala中可变Map和不可变Map的常用方法

集合之间相互转换的方法
- toArray 将其他类型的集合转换成数组
- toList 将其他类型的集合转转成list
- toSet 将其他类型的集合转换成Set
- toSeq 将其他类型的集合转换成Seq序列
- toMap 将对偶类型的集合转换成Map
- toString 将其他类型转换成字符串
map方法是映射集合,例如Array.map可以通过map里的函数参数进行映射产生一个新集合,
注意函数中的_其实是x=>x*10的简单写法,当有多个的时候也可以使用_自动映射参数,但是复杂的函数不推荐
val intsarr = Array(12,32,343,543,5,23)
val ints = intsarr.map(_*10)
for (a<-ints){
print(a +" ") //120 320 3430 5430 50 230
}
scala实现wordCount
def main(args: Array[String]): Unit = {
//定义资源数组
//思路总结,将list中的数据拆分成单个的单词(通过转化为map后,用flatten将其压缩成list),然后将数据通过map方法封装为对偶元组,然后将对偶元组进行分组,
// 得到一个map(word,(元组)):Map[String, Array[(String, Int)]]
//这时候直接将word作为key,array数组的长度(单词出现的元组)作为value
//得到word和次数
//最后直接排序(根据第二个字段)
val strings = Array("spark hadoop flink scala java","spark flink scala ","spark flink java","hadoop scala java")
val stringses: Array[Array[String]] = strings.map(_.split(" "))//得到三个数组,每个里面都是多个单词
val flatten: Array[String] = stringses.flatten//将其压缩
val wordAndOnetuples: Array[(String, Int)] = flatten.map((_,1))//得到的是(spark,1),这种形式的对偶元组
val wordToOne: Map[String, Array[(String, Int)]] = wordAndOnetuples.groupBy(_._1)//得到的是一个map
val wordCountInt: Map[String, Int] = wordToOne.map(x=>(x._1,x._1.length))//将key和list的长度写入新的map中
val converlist= wordCountInt.toList//转换成list
val reverse = converlist.sortBy(_._2).reverse
println(reverse.toBuffer)
}面向对象
Class
private[demo1] class Person(var name: String,private val age:Int,money:Double) {
private[this] var sex="公公"
println(sex)
def this( name: String, age:Int,money:Double,sex:String){
this(name,age,money:Double)
this.sex=sex
}
}
object Person{
def main(args: Array[String]): Unit = {
val zhangsan = new Person("zhangsan",18,1232.23)
println(zhangsan.age)
val zhangsan2 = new Person("zhangsan",18,1232.23)
println(zhangsan2.name)
}
}
- 其中Person后面的括号是主构造器,用val和var修饰的变量会被定义为成员变量,val自动加上get方法,var加上getset方法了
- private[demo1]控制了Person的作用范围和可见性,在demo包下可见
- private修饰的变量在class和object中可以使用,money是不能访问的,因为不是成员变量,也没有提供相应的方法
- 其中的 private[this]是和实例绑定在一块的,伴生对象object也不可以访问
- 在person中,{}代表的是构造器,每次创建对象都会调用里面的内容
- 主构造函数不满足的情况下,可以使用辅助构造器,辅助构造器必须第一句调用主构造其或者辅助构造器
Object
object是scala用来替代static关键字
- object中定义的变量,方法自动编程static修饰的
- object是单例的
- object相当于静态代码块
- 如果和同名的class在一个文件中,也叫做伴生对象,可以相互访问private修饰的变量,但是private[this]修饰的不可访问
继承
继承用的还是关键字extends,with实现特质,每个特质用with相互连接
特质trait,功能类似java8的接口,能够定义接口,也写具体的方法(),如果多个特质的方法名字相同怎么办?
编译不会报错,但是运行会直接报错,需要指明调用的是那个特质中的方法
抽象类,抽象类用abstract修饰,可以定义抽象方法和实现方法其他的与java一致
java中的所有接口都可以作为scala中的特质使用
Apply方法
在object中定义apply方法的时候,会在object名(参数...)的时候直接调用该方法
详情在前面的博客已经进行了演示
模式匹配
scala中没有switchcase这种语法,取而代之的是模式匹配
字符串匹配
def main(args: Array[String]): Unit = {
val array = Array(12.3,"2","1","3","4","tttt",true,TestTrait)
val unit = array(3)
unit match {
case 12.3=> println("第一个数")
case "2"=> println("字符串2")
case "1"=>println("字符串1")
case "3"=>println("3")
case "4"=>println("4")
case "tttt"=>println("tttt")
case true =>println("真")
case _ =>println("其他")
}
}匹配类型
def main(args: Array[String]): Unit = {
val array = Array(12.3,"2","1","3","4","tttt",true,TestTrait)
val unit = array(7)
unit match {
case z:Double=> println("第一个数")
case y:String if(y.startsWith("2"))=> println("字符串2")
case y:String if(y.startsWith("3"))=>println("字符串1")
case y:String if(y.startsWith("4"))=>println("3")
case y:String if(y.startsWith("tt"))=>println("4")
case x:Boolean if(x==true) =>println("真")
case x:Boolean if(x==false) =>println("假")
case _ =>println("其他")
}
}Scala可以编写shell脚本
正则匹配
def main(args: Array[String]): Unit = {
val source: BufferedSource = Source.fromFile(new File("K:\\word.txt"),"UTF-8")
// source.getLines().foreach(f=>println(f))
val fileSr: String = source.mkString
val str="""h*""".r
val iterator: Regex.MatchIterator = str.findAllIn(fileSr)
iterator.foreach(t=> println(t))
}正则匹配组
def main(args: Array[String]): Unit = {
val numPattion="([0-9]+) ([a-z]+)".r
var numPattion(num,item)="12 assdf"
for (elem <- numPattion.findAllIn("12 assdf,13 asssdf")) {
println(elem)}
}