根据尚硅谷课程整理
目录
当一个程序中出现多个进程共享一个变量时,会出现共享变量的并发问题
以下程序
1.主线程启动睡眠待线程启动完毕
2.VolatileExample线程(线程1)进入while循环
3.主线程修改了flag
public class VolatileExample extends Thread {
// 设置类静态变量,各线程访问这同一共享变量
private static boolean flag = true;
// 无限循环,等待flag变为false时才跳出循环
public void run() {
while (flag) {
}
}
public static void main(String[] args) throws Exception {
new VolatileExample().start();
// sleep的目的是等待线程启动完毕,也就是说进入run的无限循环体了
Thread.sleep(1000);
flag = false;
System.out.println("主线程执行完毕......");
}
}
虽然线程1和主线程共享flag变量,主线程修改了flag变量,但是并不会立即影响到线程1. 这是因为java采用了类似cpu的缓存策略.
在计算机中,处理性能依次为硬盘<内存<cpu, 假如cpu处理任务a需要5s, 内存处理此任务需要6s, 此时cpu就需要等待内存空闲时, 才能将下一个任务的结果交给内存.
为了充分使用cpu的性能, 在cpu和缓存中加入了缓存策略
cpu会优先把处理完的结果交给缓存. 同理, 在java内存模型描述了java类似cpu的处理机制, 所有变量都存在于主内存, 对于不同的线程来说, 同时操作一个共享变量速度太慢, 为了充分利用性能, 每个线程会将该变量复制到线程独有的工作内存中进行操作, 再操作完后, 将结果写回到主内存中.
对于线程1和main线程, main线程将工作内存中的flag副本修改为false, 并写回到主内存, 但是线程1并不知道, 这就是JMM中变量的可见性.
volatile
此关键字特性
1. 可见性
2. 不保证原子性
3. 禁止指令重排
可见性:
当有线程操作完该关键字修饰的变量写会主内存时, 会立即通知其他线程同步主内存的最新值更新回自己的工作内存
public class VolatileExample extends Thread {
// 设置类静态变量,各线程访问这同一共享变量
private static volatile boolean flag = true;
// 无限循环,等待flag变为false时才跳出循环
public void run() {
while (flag) {
// System.out.println("flag为true......");
}
}
public static void main(String[] args) throws Exception {
new VolatileExample().start();
// sleep的目的是等待线程启动完毕,也就是说进入run的无限循环体了
Thread.sleep(1000);
flag = false;
System.out.println("主线程执行完毕......");
}
}
对于可见性这个问题, jvm已经做出了优化(案例为jdk1.8)
当变量对于其他代码产生影响时, 会立即进行同步
while (flag) {
System.out.println("flag为true......");
}
结果为再打印1s后, false修改并对其他线程可见, 程序终止
不保证原子性
当不同线程对同一个变量进行操作时, 每个线程都将自己的结果写会主内存, 此时写操作就会出现并发问题
public class VolatileExample2 extends Thread {
// 设置类静态变量,各线程访问这同一共享变量
private static volatile int i = 0;
private CountDownLatch countDownLatch;
public VolatileExample2(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
public void run() {
for (int j = 0; j <2000; j++) {
i++;
}
countDownLatch.countDown();
}
public static void main(String[] args) throws Exception {
//countdownlatch可以理解为一个计数器,初试为10,
//每个线程都会用countDownLatch.countDown()对计数器-1,
//main线程使用countDownLatch.await(),一直阻塞直到计数器为0
CountDownLatch countDownLatch = new CountDownLatch(10);
for (int i = 0; i <10; i++) {
new VolatileExample2(countDownLatch).start();
}
countDownLatch.await();
//或者使用线程数量判断 因为有gc线程和main自己的线程, 所以线程数量为2
/*while(Thread.activeCount()>2){
Thread.yield();
}*/
System.out.println("主线程执行完毕......i为:"+i);
}
}

10个线程, 每个都对i进行1000次++操作, 正常应该为2w
但是因为线程和线程间同时回写时出现了值覆盖情况
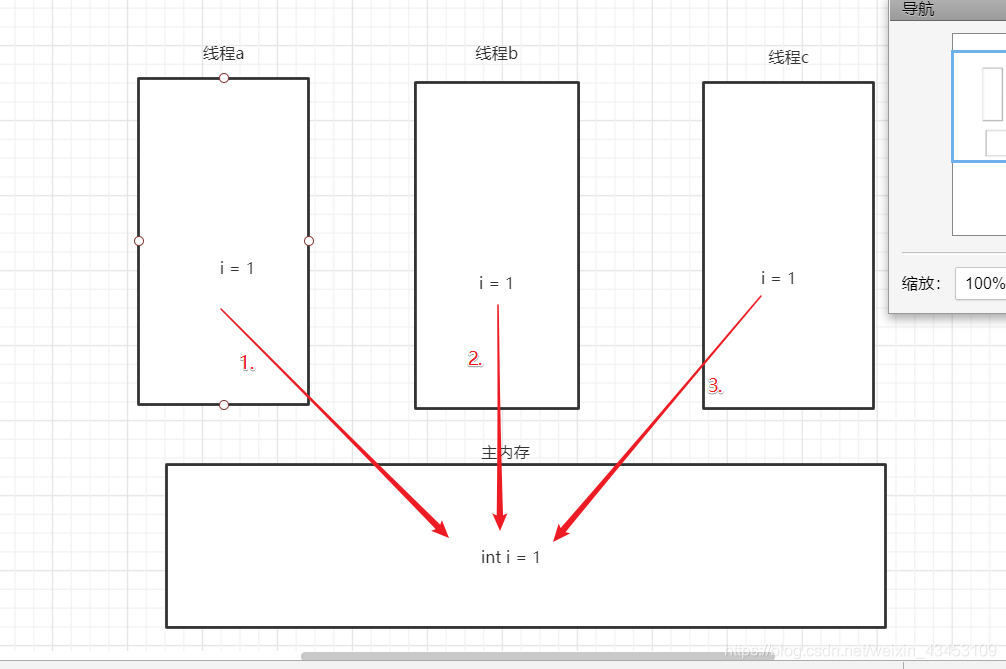
针对下图
1.a线程将i修改为2并立即回写主内存
2. b线程也将i修改为2并立即回写
3. 同理1和2
3个线程回写都是在同一时间发生的
3个线程并没有来的及去同步主内存中新的值, 并回写了, 这就bc线程将a线程的值覆盖了, 本来是3个线程操作完结果为4, 但结果为2, 值丢失了
针对这种并发问题, 可以使用synchronized解决, 但是这样效率低, 同一时刻只有一个线程在运行, 没有充分利用性能, 解决这种并发问题, 一般的处理思想都是通过消耗性能来达到线程安全的效果.
解决方案可以使用原子类
public class VolatileExample2WithAtomic extends Thread {
// 设置类静态变量,各线程访问这同一共享变量
private static volatile AtomicInteger atomic = new AtomicInteger();
private CountDownLatch countDownLatch;
public VolatileExample2WithAtomic(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
public void run() {
for (int j = 0; j <200; j++) {
//获取并增加,默认增加的值为1
atomic.getAndIncrement();
}
countDownLatch.countDown();
}
public static void main(String[] args) throws Exception {
//countdownlatch可以理解为一个计数器,初试为10,
//每个线程都会用countDownLatch.countDown()对计数器-1,
//main线程使用countDownLatch.await(),一直阻塞直到计数器为0
CountDownLatch countDownLatch = new CountDownLatch(100);
for (int i = 0; i <100; i++) {
new VolatileExample2WithAtomic(countDownLatch).start();
}
countDownLatch.await();
//或者使用线程数量判断 因为有gc线程和main自己的线程, 所以线程数量为2
/*while(Thread.activeCount()>2){
Thread.yield();
}*/
System.out.println("主线程执行完毕......atomic为:"+atomic.get());
}
}
aomic为原子类, 内部参考了自旋锁, 对于每个线程的写回时, 都会与主内存中的值进行对比, 与预期结果相同时会进行写回, 不然就读取新的值. 之后会做详细解释.
指令重排
对同一份代码, 编译后的指令是相同的, 但jvm出于充分利用cpu性能考虑, 会对指令执行顺序进行优化
比如
//指令重排
public class InstructionReorder {
public static boolean flag = false;
public static int i = 0;
public static void main(String[] args) {
if(flag){
System.out.println(i);
}
}
class ThreadA extends Thread{
@Override
public void run() {
i = 1;
flag = true;
}
}
}
正常来说打印出的结果为1, 但是因为线程2中进行了指令重排, flag优先变为true, main线程进入判断, 此时输出的i仍为0.
volatile对flag进行修饰, 这段代码就不会进行重排, 这是因为对volatile修饰的变量执行时会产生内存屏障 , 区分对普通变量的读写和volatile变量的读写
疑问: 是否需要对同一个栈中多个变量添加volatitle, 还是添加一个就可以保证整段指令不进行重排
如果两个变量之间有依赖关系, 将不进行重排
a =1;
b =2+a;
b依赖了a的值, 所以不会进行优化导致指令重排, 类似的原则请看这篇
happen - before解释
https://www.jianshu.com/p/7a6118b2d794
CAS
compare and swap 比较并交换
Atomic
在使用atomic解决原子性问题时说过, atomic底层使用了比较并交换的方式
getAndAddInt()每次增加1
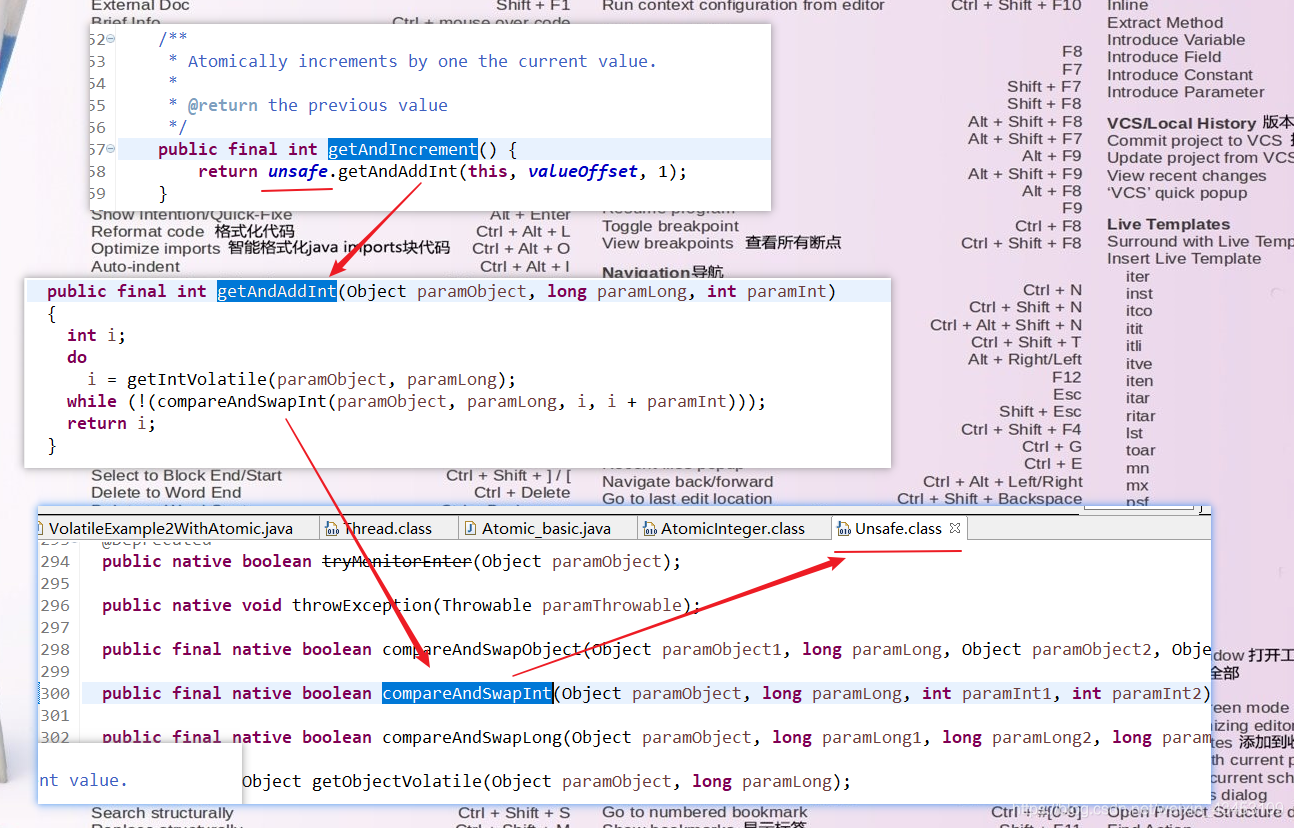
另一个方法compareAndset()
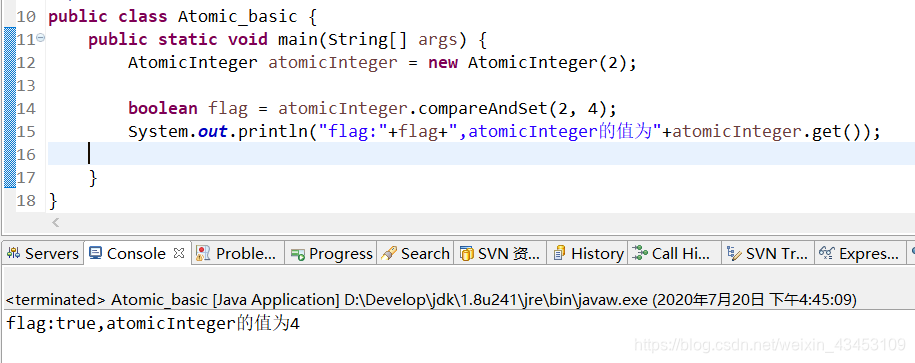
工作内存中atomic的真实值为expect期望值, update为更新值, 期望值与主内存中atomic真实值相同时, 返回true, 将atomic的值改为更新值
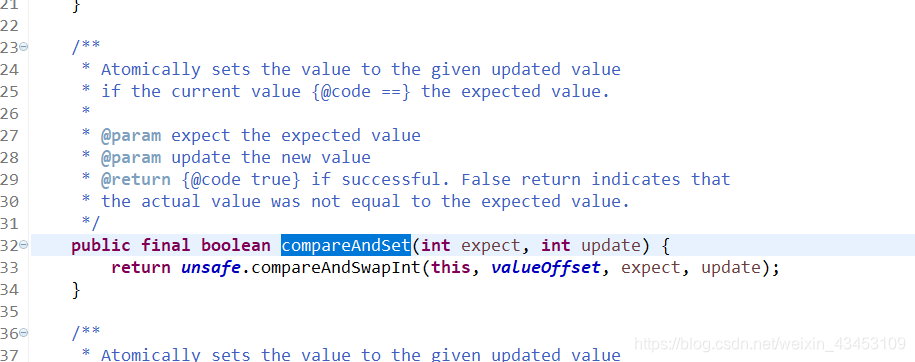
valueoffset
内存偏移量, 通过他指定一个对象的值
compareAndSwapInt()中指定的valueoffset就代表原始值

private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
通过valueoffset找到了对象的真实值

首先do中获取当前主内存中的值i, compareAndSwapInt()如果i 和预期值相同, 就进行swap交换, 如果比较后发现值不相同, 就重新获取一次i ,再进行对比
atomic中没有使用到锁, 就实现了线程安全, 因为底层使用了unsafe类
unsafe
public final native boolean compareAndSwapInt(Object paramObject, long paramLong, int paramInt1, int paramInt2);

unsafe中的native方法是java底层调用c语言的接口, 编译后按照原指令进行执行,相当于汇编指令, 执行过程中无法被打断, 这样就保证了并发时的原子性
unsafe通过valueoffset可以像C语言的指针一样直接操作内存.
CAS的缺点
1.dowhile中可以看到, 如果和主内存中的值一直不相同, 会一直进行比较, 消耗资源
2.仅能支持一个变量
3.aba问题
假如线程a多次获取到执行权, 在线程b阻塞过程中, 对变量i进行两次写操作, 变量i初始值为0, 第一次修改为2, 第二次修改为0, 对线程b来说, 当他获取主内存中的值并进行比较时, 满足条件, 比较并赋值成功, 线程b不知道这个i已经是a操作后的了.
解决aba问题
AtomicReference原子引用类
原子类中引用了对象泛型, 并保存了一个对象, 再对对象进行cas操作
public class AtomicReferenceTest {
public static void main(String[] args) {
AtomicReference<User> atomicReference =new AtomicReference();
User jojo = new User();
jojo.setName("jojo");
User dio = new User();
dio.setName("dio");
atomicReference.set(jojo);
boolean flag = atomicReference.compareAndSet(jojo,dio);
System.out.println("flag:"+flag+",username:"+atomicReference.get().getName());
boolean flag2 = atomicReference.compareAndSet(jojo,dio);
System.out.println("flag2:"+flag2+",username:"+atomicReference.get().getName());
}
}
class User{
private String name;
/**
* @return the name
*/
public String getName() {
return name;
}
/**
* @param name the name to set
*/
public void setName(String name) {
this.name = name;
}
}
AtomicStampedReference原子引用类
原子类中引用了对象泛型, 并保存了一个对象, 并且初试时带有一个版本号, 每次cas操作时, 都对版本号进行操作, 再对对象进行cas操作时, 会比较版本号, 值和版本号均相同时, 代表比较成功, 解决aba问题.
public class AtomicStampedReferenceTest {
private static AtomicStampedReference<Integer> asr = new AtomicStampedReference(1,1);
public static void main(String[] args) {
new Thread(()->{
try {
//等待t2线程通过主内存数据,
TimeUnit.SECONDS.sleep(1);
} catch (Exception e) {
e.printStackTrace();
}
asr.compareAndSet(1, 2, asr.getStamp(),asr.getStamp()+1);
System.out.println(Thread.currentThread().getName()+"t1第1次修改的版本号为:"+asr.getStamp());
asr.compareAndSet(2, 1, asr.getStamp(), asr.getStamp()+1);
System.out.println(Thread.currentThread().getName()+"t1第2次修改的版本号为:"+asr.getStamp());
},"t1").start();
new Thread(()->{
int stamp = asr.getStamp();
try {
//等待线程t1进行aba操作
TimeUnit.SECONDS.sleep(2);
} catch (Exception e) {
e.printStackTrace();
}
boolean flag = asr.compareAndSet(1, 2, stamp,stamp+1);
System.out.println(Thread.currentThread().getName()+"修改结果标示flag:"+flag);
System.out.println("t2的期望版本号为:"+(stamp+1)+";实际asr版本号为:"+asr.getStamp());
},"t2").start();
}
}
集合类不安全
ArrayList
arrayList底层为数组, 扩容时通过复制原数组实现, 扩容因子为0.5, 原长度的一半
arrayList为了保证效率增删改操作都没有加锁
public class ArrayListDemo {
public static List<Integer> a = new ArrayList();
public static void main(String[] args) {
for (int i = 0; i < 30; i++) {
new Thread(()->{
a.add(i);
System.out.println(a);
},String.valueOf(i)).start();
}
}
}
在多线程并发下, 底层迭代器会比较集合当前长度与预期长度, 如果不同就会抛出异常concurrentModificationException

使用vector 或者集合工具类collections 可以保证线程安全, 这两者都是给集合加synchronized锁
public static List<Integer> sycha = Collections.synchronizedList(a);

juc中提供了一个list的实现类CopyOnWriteArrayList
使用CopyOnWriteArrayList可以通过一种轻锁解决这个问题
public static CopyOnWriteArrayList cwaList = new CopyOnWriteArrayList();
集合中维护了一个数组, 通过volatile修饰, 保持了可见性
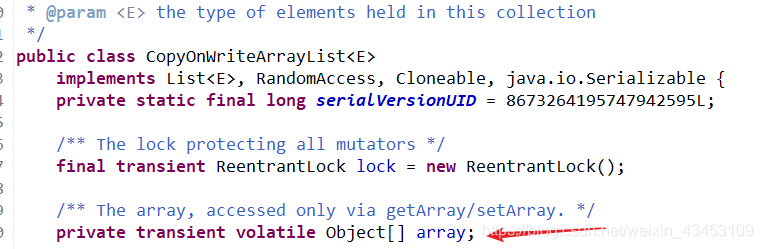
通过重入锁保证安全, 并根据写时复制思想保证效率
首先通过copyof复制出一个新的数组, 当前线程通过对复制出来的新的数组完成写入, 并在写入后替换这个list对象中数组的引用, 指向复制出来的数组.
这样做比直接加synchronized优点是保证写安全的情况下, 允许其他线程读取该对象的数据, 因为写入过程操作的是复制的, 原数组并未更改, 这种方式适合写少读多的情况.
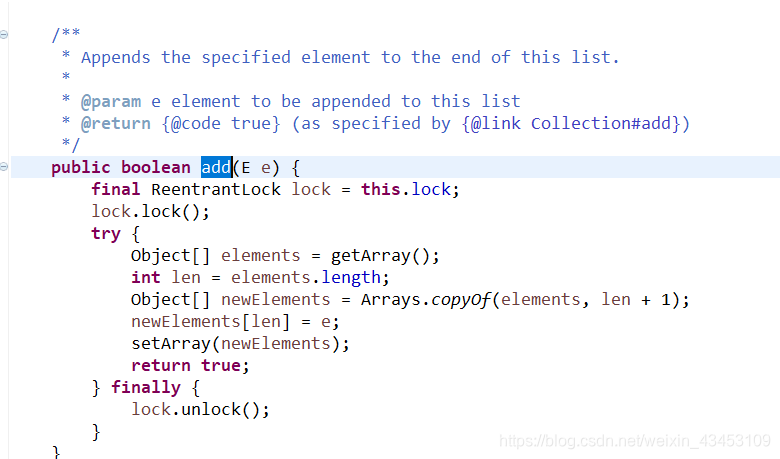
hashSet
hashset是hashmap, value是一个恒定对象
add操作同样会出现并发问题

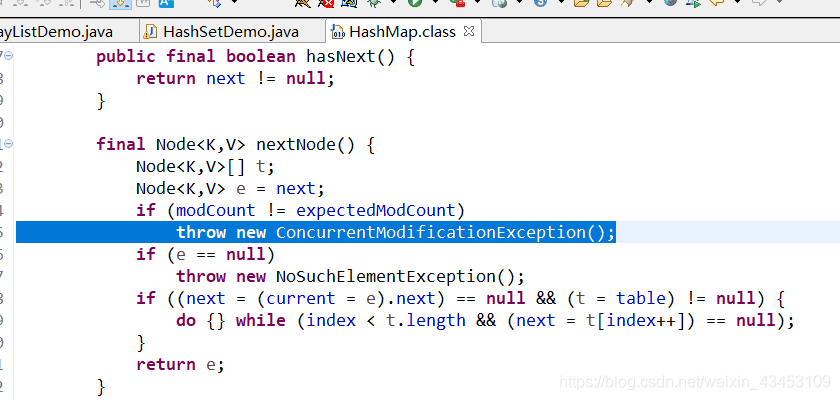
同样juc中提供了实现类

跟hashmap一样, 有copyonwritearraylist创建
不过set的add操作会先进行一次判断, 判断list是否已包含该元素
HashMap
HashMap也是采用了迭代器模式, 底层同样会报并发修改异常
使用juc中的ConcurrentHashMap, 底层采用分段锁, 既保证了效率, 又保证了安全, 但是在jdk1.8中, 在多线程中, 当key的hash值相同时, 会有一个死循环的问题, 在1.9之后修复了,

JDK1.8源码–ConcurrentHashMap锁分段的思考
主要看put的方法操作, 牵扯到hashmap的数据结构问题, hashmap底层使用了Node<k,v>数组, 根据不同情况, 扩容的方式有长度扩容, 节点改为链表, 当满足条件时该节点又会改为红黑树, 所以数组的每个下标位置都会存放大量节点元素, 多线程操作时, 只要将某个下标的元素锁住, 而不是像hashtable一样将整个数组锁住, 同时如果该节点位置为null时, 将通过compareAndSwap不加锁操作, 这种方式是通过对比元素的内存地址, 使用unsafe提供的系统原语操作, 可以保证原子性
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果key或者value为空,抛异常
if (key == null || value == null) throw new NullPointerException();
// 计算hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 初始化Node数组
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// 根据hash值计算数组的下标,并取出该值,判断是否为空
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 利用cas算法直接插入Node结点,不加锁
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果该节点是ForwardingNode结点,
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 利用synchronized锁住tab[i]结点
// tab数组中下标为i的结点,其中包括链表的头节点,红黑树的根节点,单节点
synchronized (f) {
if (tabAt(tab, i) == f) {
// fh>0表示该结点是链表的头节点
if (fh >= 0) {
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果key与hash值与当前结点相同,则修改当前节点的value值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 如果当前结点时链表的尾结点,则创建一个新结点,并将该结点插入到链表的尾部
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果该结点时红黑树的根结点
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 向树中插入新结点
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 如果binCount不为0,说明put操作对数据产生了影响
if (binCount != 0) {
// 如果链表长度达到临界值8,则将链表树化
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 更新元素个数
addCount(1L, binCount);
return null;
}