** grep:文本过滤工具 正则表达式引擎**
基于用户指定的“模式”,对目标文件逐行进行匹配检查,打印匹配到的行,默认打印到终端窗口
模式:正则表达式元字符编写出来的过滤条件
**正则表达式:**由一类特殊的字符以及文本字符所编写的模式,并不代表字面含义,表达控制或者通配的功能
元字符: [[:space:]]
grep [OPTIONS] PATTERN [FILE…]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE…]
--color=auto:高亮显示匹配到的文本
-i:忽略字符大小写
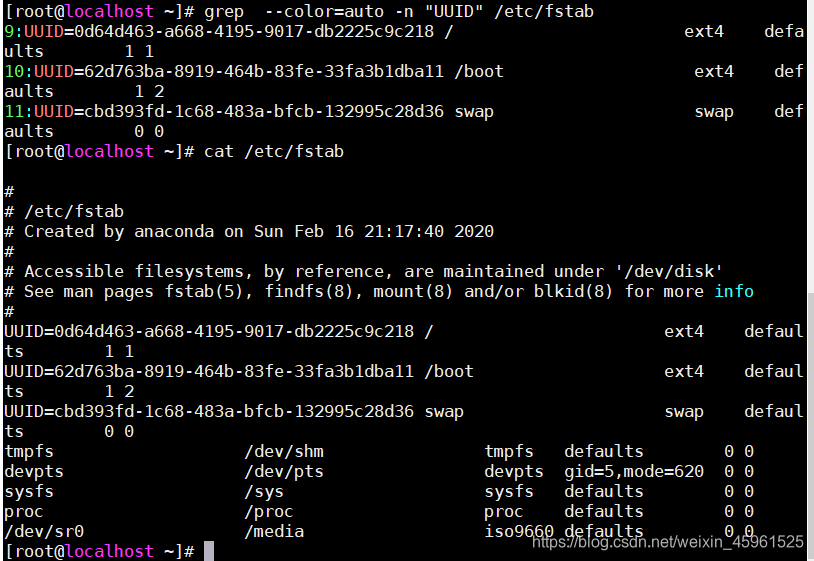
-n:显示行号
-E:支持使用扩展正则表达式
-o:打印匹配到的行
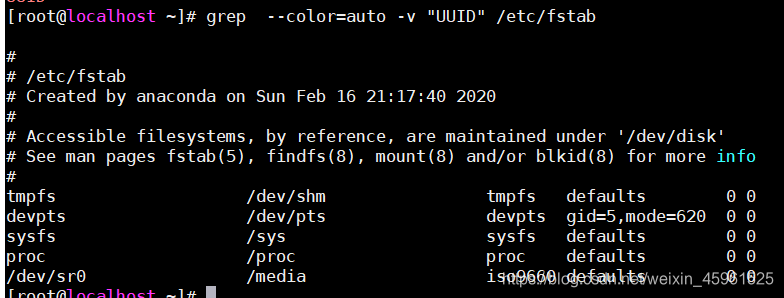
-v:显示不能被匹配到的行
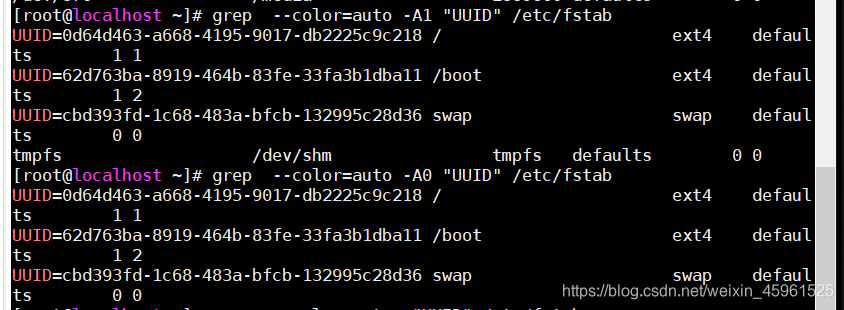
-A #:后几行
-B #:前几行
-C #:前后各几行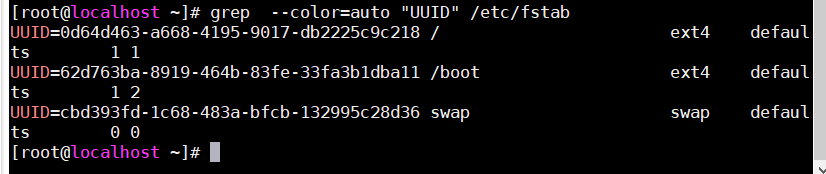

 元字符:
元字符:
字符匹配
.:匹配任意单个字符
[]:范围内任意
[^]:范围外
[a-z],[A-Z],[0-9],[a-z0-9]
[[:upper:]]:所有的大写字母
[[:lower:]]:所有的小写字母
[[:alpha:]]:匹配所有的字母
[[:digit:]]:所有的数字
[[:alnum:]]:字母和数字
[[:space:]]:空白字符
[[:punct:]]:标点符号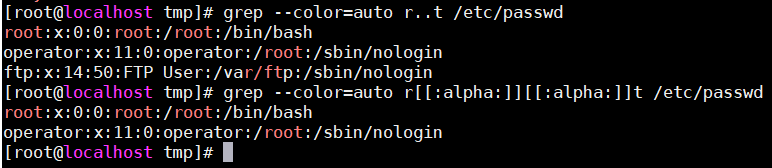
匹配次数
用在要指定出现的次数的字符的后面,用来限制其前面字符出现的次数
:匹配其前面的字符任意次。0次,1次或者多次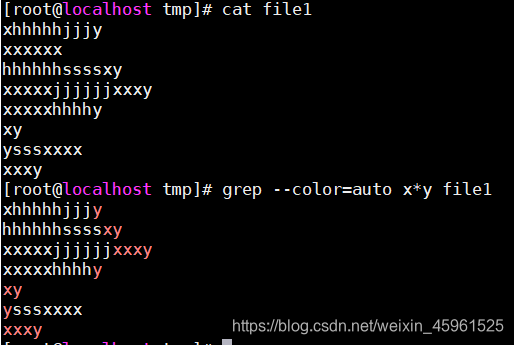
.:匹配任意长度的任意字符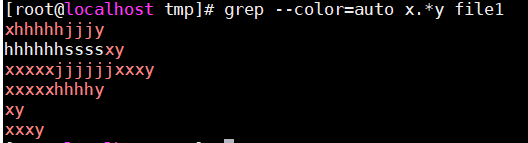
?:匹配其掐面的字符0次或者1次,最多一次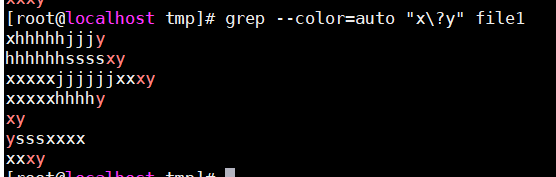
+:匹配其前面的字符1次或者多次,至少一次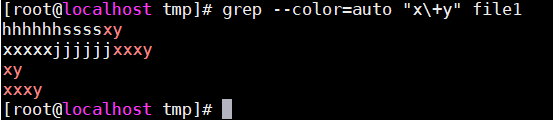
{m}:匹配其前面的字符m次 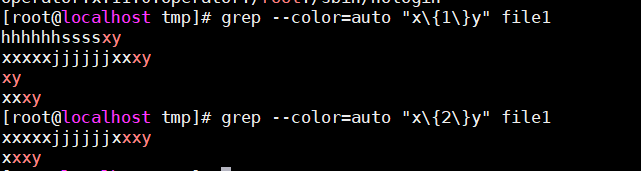
{m,n}:匹配其前面的字符至少m次,至多n次
{0,n}:至多n次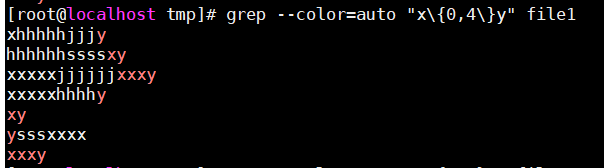
{m,}:至少m次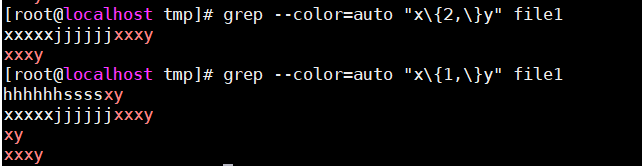
位置锚定
^:行首锚定,用于模式的最左侧
KaTeX parse error: Expected group after '^' at position 26: …的最右侧 ^̲:空白行
1*$
^pattern$:用pattern来匹配整行
<或者\b:词首锚定,用于单词的左侧
>或者\b:词尾锚定,用于单词的右侧
<pattern>
1、显示/etc/passwd文件中不以/bin/bash结尾的行;
2、显示/etc/passwd中的两位数或者三位数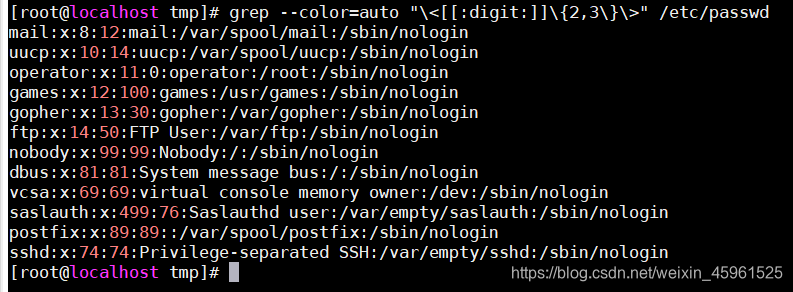
3、找出 netstat -tan 命令结果中以LISTEN后跟一个或者多个空白字符结尾的行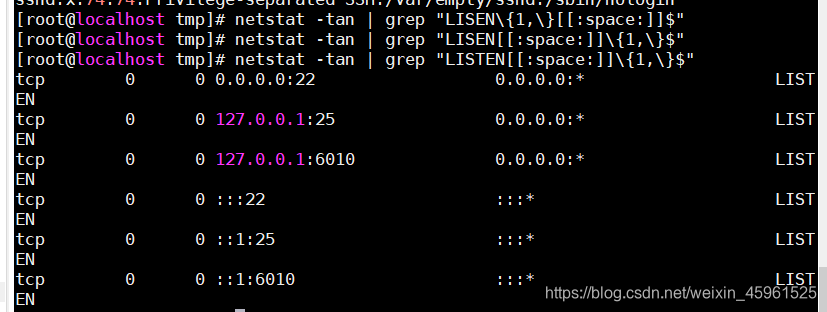 分组和引用
分组和引用
分组
():分组,将一个或者多个字符捆绑在一起当作一个整体处理
(xy)(mn)(zq)*ab
xyab xyxyab ab xyxyxyxyxyab
引用
分组括号内匹配的模式,会被正则表达式引擎记录在内部变量中,通过变量进行应用
\1:模式从左侧起,第一个左括号与之匹配的右括号之间模式所匹配到的字符
\2: 模式从左侧起,第二个左括号与之匹配的右括号之间模式所匹配到的字符
\3
\4
…
He loves his lover.
He likes his lover.
She likes her liker.
She loves her liker.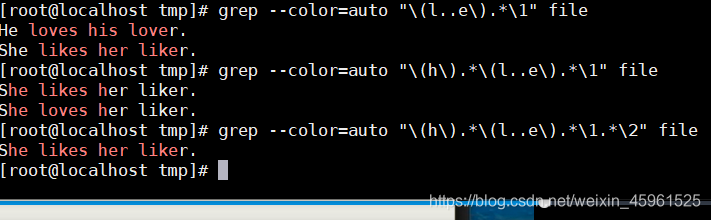
或者:
| a|b 在|两边a和b是独立的
A|apple 表示:A或者apple 不是 Apple或者apple
(A|a)pple
正则表达式匹配中,工作在贪婪模式:尽可能多的去匹配
\
[:space:] ↩︎