-
字典插入一个元素存在就不操作,不存在给他一个默认值.
使用get方法根据key获取value,如果key不存在会使用默认值,如果没有设置默认值,会返回None
print(person.get(‘addr’, ‘shanghai’)) # shanghai扩展:
# 1. clear 用来清空字典
# 2. pop 用来删除指定的数据
# 3. popitem 用来删除最后一个键值对数据
# 4. 使用del运算符来删除指定的数据 -
中间件的使用和作用
在view调用之前:
process_request(self,request)
process_view(self,request,view_func,view_args,view_kwargs)
在view调用后
process_template_response(self,request,response)
process_exception(self,request,exception)
process_response(self,request,response) -
git删除分支切换分支命令,
删除
git branch -d + 本地分支名
git push origin --delete + 本地分支名
切换
git checkout +分支名 -
linux查找一个文件的命令
whereis -
列表删除的4个方法
str=[=4,5,2,6]
①str.remove(6)
②str.pop(1)
③del str[1] 或者 del str[2:4]
④str.clear() -
flask蓝图的作用
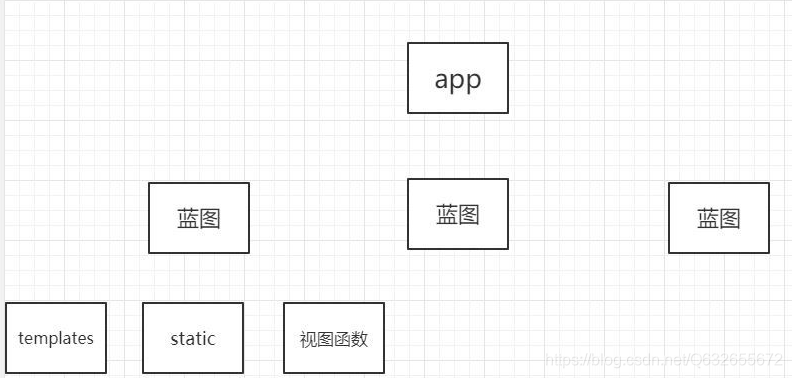
蓝图也是一种规划,主要用来规划urls(路由),把views和manager.py连接上 -
python多线程,
进程>线程>协程
from threading import Thread
#target参数表示需要执行的行为,它是一个函数
#name可以给线程起名字
def test():
t1 = Thread(target=test, name=‘线程1’)#需要调用线程的start方法,启动线程
t1.start()线程锁
lock = threading.Lock()#先要获取锁:
lock.acquire()#放心地改吧:
lock.release() -
进程
# target:表示进程需要执行的函数
# args: 表示调用函数时的参数
# name: 进程的名字
import multiprocessing
p1 = multiprocessing.Process(target=demo, args=(100,) , name=‘进程’) -
python模块,几个常见库,
标准库:os,sys,re math urllib.request datetime zlib timeit unittest
模块:random,hashlib,md5 string模块 urllib -
TCP
TCP通信需要经过创建连接、数据传送、终止连接三个步骤
优点:可靠,稳定适合传输大量数据
缺点:传输速度慢 、占用系统资源高UDP 网络程序发送数据不需要建立连接
优点:快。比TCP稍安全
缺点:不可靠,不稳定。因为UDP没有TCP那些可靠的机制,在数据传递时,如果网络质量不好,就会很容易丢包。引用:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接2、TCP需要连接 传输速度慢,UDP不需要连接 传输速度快 3、TCP不支持发广播,UDP支持发广播 4、TCP对系统资源要求较多,UDP对系统资源要求较少 5、TCP提供可靠的数据传输,UDP不保证可靠的数据传输,易出现丢包情况 6、 TCP适合发送大量数据,UDP适合发送少量数据 7、TCP有流量控制,UDP没有流量控制
————————————————
版权声明:本文为CSDN博主「Weiai_520」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Weiai_520/article/details/103846680
11. 列表生成式、生成器、迭代器
在 Python 中,使用了 yield 的函数被称为生成器(generator)。
跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
列表生成式:
L1 = [x * x for x in range(1, 11) if x % 2 == 0]
print(L1)
[4, 16, 36, 64, 100]
列表生成器:相比列表表达式,只不过将[]换成了(),更加省内存。
L11 = (x * x for x in range(1, 11))
print(L11) #生成器对象
print(next(L11)) #用next取出第一个数
print(next(L11)) #用next取出第二个数
...... #用next取出第n个数
迭代器:
① list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
print (next(it))
②list=[1,2,3,4]
it = iter(list) # 创建迭代器对象
for x in it:
print (x, end=" ")
- 装饰器的使用
封装一个函数,修改其函数的功能,有助于让我们的代码更简短,可以让你的代码更简洁
MODIFY_PERMISSION = 16 # 10000
DELETE_PERMISSION = 8 # 01000
READ_PERMISSION = 4 # 00100
WRITE_PERMISSION = 2 # 00010
EXECUTE_PERMISSION = 1 # 00001
x=input('用户权限值是')
def ver_login(base_permission,user_permission):
def handle_action(fn):
def action():
fn()
return fn
return action
return handle_action
@ver_login(READ_PERMISSION,x)
def read():
print('我是read函数')
-
scrapy工作流程原理,几个模块
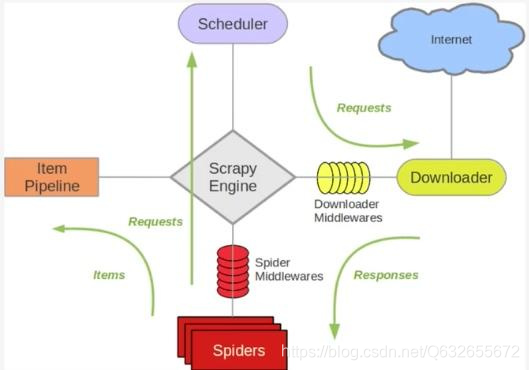
scrapy的概念:Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架爬虫中起始的url构造成request对象–>爬虫中间件–>引擎–>调度器
调度器把request–>引擎–>下载中间件—>下载器
下载器发送请求,获取response响应---->下载中间件---->引擎—>爬虫中间件—>爬虫
爬虫提取url地址,组装成request对象---->爬虫中间件—>引擎—>调度器,重复步骤2
爬虫提取数据—>引擎—>管道处理和保存数据
1、爬虫引擎获得初始请求开始抓取。2、爬虫引擎开始请求调度程序,并准备对下一次的请求进行抓取。
3、爬虫调度器返回下一个请求给爬虫引擎。
4、引擎请求发送到下载器,通过下载中间件下载网络数据。
5、一旦下载器完成页面下载,将下载结果返回给爬虫引擎。
6、引擎将下载器的响应通过中间件返回给爬虫进行处理。
7、爬虫处理响应,并通过中间件返回处理后的items,以及新的请求给引擎。
8、引擎发送处理后的items到项目管道,然后把处理结果返回给调度器,调度器计划处理下一个请求抓取。
9、重复该过程(继续步骤1),直到爬取完所有的url请求。
-
selenium如何处理动态页面
from selenium import webdriver
import time
from lxml import etree
driver_path = r"G:\Crawler and Data\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path)
driver.get('https://www.baidu.com/')
#使用 xpath 方式获取 效率高 如果只是解析页面就使用这种
tree = etree.HTML(driver.page_source)
li_lists = tree.xpath('xxxxxxxxxx')
#通过id 的方式获取 如果对元素进行操作时, # 比如要发送字符串, 点击按钮, 下拉操作 就使用这种方法
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
time.sleep(3)
driver.close() # 关闭页面
# driver.quit() # 关闭整个浏览器
- 如何定义一个迭代器
定义迭代器就是定义__iter__ ,next 方法