本专栏总结王利涛《C语言嵌入式Linux高级编程》第三期课程
文章目录
一、编译输入输出
- (1) 输入:C程序源文件;
- (2)输出:汇编文件,目标文件;
- (3)编译过程主要做了什么?
- 从高级语言到低级语言的转变
- 程序语句:函数 ---->代码段;
- 变量、常数----->数据段、BSS段、rodata段;
- 各种辅助信息----->符号表、重定位表。
- 从高级语言到低级语言的转变
二、编译过程
- 基本过程:
词法分析;
语法分析;
词义分析;
中间代码生成;
汇编代码生成;
目标代码生成。
三、编译第一阶段
1)语法分析
- 从左到右,一个字符一个字符读入源程序;
- 对源程序的字符流进行扫描,分解成一系列记号:token;
- 常见记号:
关键字、标识符(函数名、变量名、标号等)
字面量(数字、字符串等)
分界符(分号、逗号等) - 将标识符存到符号表,将数字、字符串存放到字符串表。
- 词法扫描器
①该阶段主要由词法扫描器完成,比如lex词法扫描器;
②采用有限状态机去解析并识别这些token、分界符、结束符;
③词法错误:遇到中文字符、圆角/半角字符会出错。 - 举例:
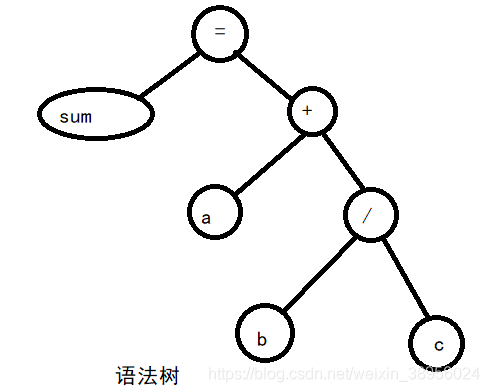
语句:sum = a+b/c;
包含8个记号:“sun”、“=”、“a”、“+”、“b”、“/”、“c”、“;”
四、编译第二阶段
1)语法分析
- 前一阶段产生的token序列进行语法分析,看是否构成一个语法上正确的程序,分解成语法短语(程序、语句、表达式等);
- 语法短语用语法树表示,是一种树形结构,不再是线性序列;
2)语法分析器
- 专门的语法分析工具:yacc,对输入序列进行分析,构建出语法树;
- 对于不同的编程语言,编译器开发者只需改变语法规则,而无需为每个编译器写一个语法分析器;
- 语法错误:syntax error
五、编译第三阶段
1)语义分析
- 检查语法分析输出的语句、程序、表达式有没有错误;
- 仅仅完成了语法层分析,对程序、语句的真正意义并不了解;
- 静态语义:在编译期间能确定的语义
函数实参形参类型匹配及转换;
不允许使用一个未声明的变量。 - 动态语义:在运行期间才能确定的语义
比如:除数为0,
2)语义分析器
- 经过语义分析后,整个语法树的表达式都被标示了类型;
- 如果源代码语义上没有问题,就会接下来进入下一个阶段;
3)常见的语言错误(警告)
- 使用一个未声明的变量或函数;
- 函数的形参实参、返回类型不匹配、不兼容(默认类型转换后);
- continue 语句不能出现循环语句之外;
- break 不能出现在循环或switch语句之外。
六、编译器第四阶段
1)生成中间代码
- 将语法树转换成中间代码;
2)现代编译器构造
- 前端:词法分析、语法分析、语义分析;
- 优化端:对中间代码进行优化;
- 后端:指令选择,寄存器分配。
3)中间代码
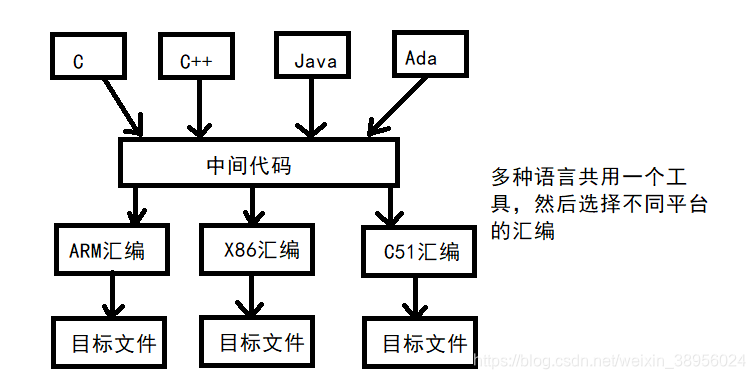
- 将源代码变成一种内部表示形式,这种形式称为中间代码;
- 中间代码是一种记号系统,常见的有:三地址码。
- 语法树是二维树结构,而中间代码可以看作一堆线性序列;
- 特点:
非常间接目标代码,类似于伪代码;
容易生成,容易将其翻译成目标代码。
4)为什么要使用中间代码?
5)三地址码
$arn-linux-gnuebigcc -fdump-tree-gimple main.c
int main()
{
int sum = 0;
int a = 2;
int b = 1;
int c = 1;
sum = a+b/c;
return 0;
}
三地址码↓↓
main()
{
int D.4226; //定义了一些临时变量,最终被翻译成寄存器
int D.4227;
{
int sum;
int a;
int c;
sum = 0;
a = 2;
b = 1;
c = 1;
D.4226 = b/c;
sum = D.4226+a;
D.4227 = 0;
return D.4427;
}
}
七、编译第五阶段
1)生成汇编
- 指令选择: 将中间代码翻译成汇编文件;
2)过程
- 中间代码——》控制流、数据流分析、寄存器分配——》汇编语言;
- 汇编语言——》汇编器——》目标文件。