文章只是整理了自己后台开发中经常使用的命令和一些参数,遇到问题可以快速的定位到需要使用的命令,再根据自己的应用情况man 命令查询具体参数的意思。
基本命令和快捷键
- 基本命令
| 命令 | 简单说明 |
|---|---|
| cd | 1、cd 具体目录,如cd /tmp 2、cd - 返回之前进入的目录 |
| pwd | 打印当前目录 |
| ls | 查看当前目录的文件信息,如ls -hl |
| touch | touch 文件名,如touch test.txt,如果test.txt文件不存在则创建,存在则将文件的修改时间改为当前时间(针对读取实时文件的程序会使用) |
| cp | 拷贝文件,如cp test.txt test2.txt ,拷贝test.txt到test2.txt |
| rm | 删除文件,如rm test2.txt ,删除文件test2.txt |
| mv | 重命名文件或将文件拷贝到某一目录,如mv test.txt test2.txt ,将文件test.txt重命名为test2.txt |
| cat | 查看文件,如cat test2.txt,查看文件test2.txt |
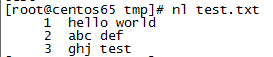
| nl | 显示文件行号,如nl test2.txt,显示文件test2.txt 的行号 |
| diff | 比较文件差异,如diff test.txt test2.txt,显示文件test.txt与test2.txt 的差异 |
| mkdir | -p 递归创建目录(父目录不存在则创建),如mkdir -p a/b/c,会创建a目录再创建b目录再创建c目录 |
| basename | 返回去除目录的文件名,如basename /tmp/test.txt ,会返回去除/tmp后的test.txt |
| dirname | 返回文件目录,如dirname /tmp/test.txt,会返回/tmp目录 |
| head | 查看文件前几行内容,如head -n 1 test.txt,查看文件test.txt前一行内容 |
| tail | 查看文件后几行内容,如tail -n 1 test.txt,会返回文件test.txt最后一行的内容,此外tail一般都是通过-f查询实时日志 |
| 命令首字母+tab | 命令补全 |
| 命令首字母+tab+tab | 显示所有命令 |
| history | 查询历史命令,通过!历史命令编号,可以执行历史命令 |
| find | 文件查找,find 查找目录 -name 文件名称,如find /tmp -name ‘test.txt’ -ls,查找/tmp目录下的test.txt文件 |
| echo | 输出变量,如TEST=“ABC” echo ${TEST} |
| ln | ln -s test.txt testlink,为test.txt建立快捷方式testlink |
| wc | 统计文件行数,如wc -l test.txt ,统计test.txt的行数 |
| stat | 查看文件属性,如stat test.txt ,查看test.txt的属性 |
| scp | 远程拷贝XXX.XXX.XXX.XXX的/tmp/test.csv文件到本地/home/test.csv:scp -P 端口 [email protected]:/tmp/test.csv /home/test.csv |
- 常用快捷键
| 快捷键 | 简单说明 |
|---|---|
| Ctrl+A | 命令行移动光标至行头 |
| Ctrl+E | 命令行移动光标至行尾 |
| Ctrl+U | 删除此处至开始所有内容 |
| Ctrl+K | 删除此处至末尾所有内容 |
| Ctrl+C | 终止当前进程 |
文件相关
- grep
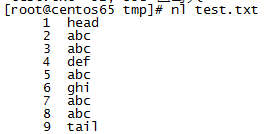
以文件test.txt做示例,文件内容如下:
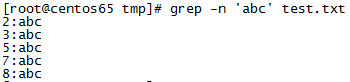
1、查询包含"abc"的所有行并显示行号(-n 表示显示行号):grep -n ‘abc’ test.txt
2、查询包含"abc"的前2行并显示行号:grep -n ‘abc’ test.txt|head -n 2

3、查询包含"abc"的后2行并显示行号:grep -n ‘abc’ test.txt|tail -n 2

4、查询不包含"abc"的行并显示行号(-v 表示未匹配):grep -n -v ‘abc’ test.txt

5、查询包含"def"当前行的后2行并显示行号(-A 表示后几行):grep -n ‘def’ -A 2 test.txt

6、查询包含"def"当前行的前2行并显示行号(-B 表示前几行):grep -n ‘def’ -B 2 test.txt

- sed
命令格式:sed [-ni] [动作]
动作格式:行号+操作
常用操作:
(1)新增:a
(2)插入:i
(3)取代:c
(4)打印:p
(5)替换:s
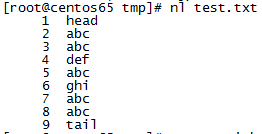
还是以grep命令使用的文件为例
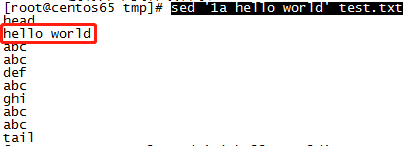
1、在第一行后插入"hello world"(1a表示第一行后):sed ‘1a hello world’ test.txt
2、在第一行前插入"hello world"(1i表示第一行前):sed ‘1i hello world’ test.txt
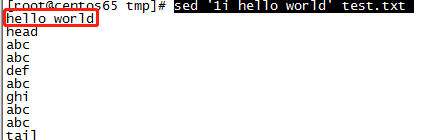
如果引用变量要用双引号"1i ${HELLOWORLD}":sed “1i ${HELLOWORLD}” test.txt
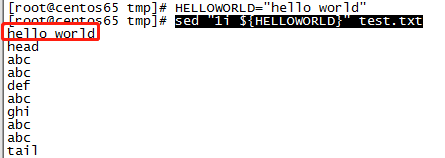
3、取代第一行的数据为"hello world"(1c表示取代第一行):sed ‘1c hello world’ test.txt
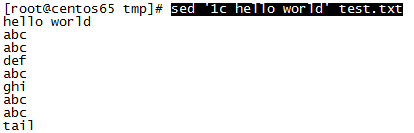
4、每行行首添加"hello world" (^表示行首,s表示替换):sed ‘s/^/hello world /g’ test.txt
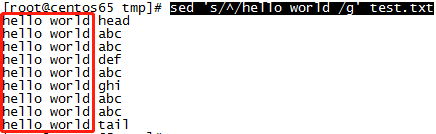
5、每行行尾添加"hello world" ($表示行尾,s表示替换):sed ‘s/$/hello world /g’ test.txt
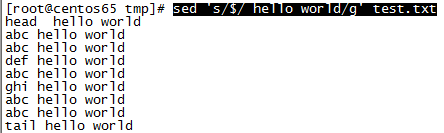
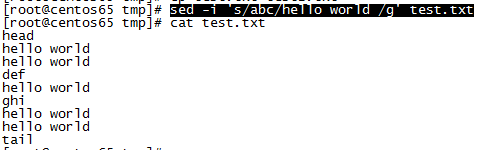
6、替换每行所有的"abc"为"hello world" :sed ‘s/abc/hello world /g’ test.txt
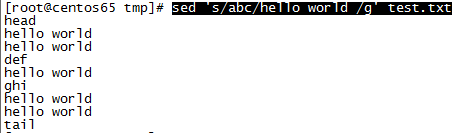
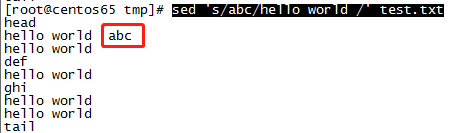
关于”g“的说明:加g替换每行所有匹配的字符,不加则替换每行第一个匹配的字符,如第二行有两个abc则只替换一个abc,如修改文件test.txt第二行为两个abc
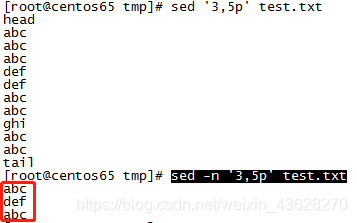
7、提取文件的某几行(3,5p表示打印3~5行,注意加-n才会将sed处理的行列出来,否则都显示) :sed -n ‘3,5p’ test.txt
8、替换每行所有的"abc"为"hello world"并且直接修改文件(-i表示直接修改文件) :sed -i’s/abc/hello world /g’ test.txt
- awk
主要功能:把文件逐行读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理
命令格式:awk [-F field-separator] ‘commands’ input-file(s)
写个简单例子,以下面文件为例
1、打印第一列($i,i表示分隔符分开后的列序号,0表示所有列):awk ‘{print $1}’ test.txt
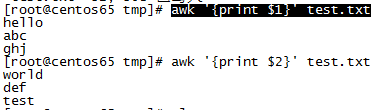
2、提取第一列为’hello’的行:cat test.txt |awk ‘$1==“hello” {print $0}’|nl

- iconv
文件编码格式转换:将gbk.csv转为utf8.csv
iconv -f gbk -t utf-8 gbk.csv -o utf8.csv - tar
将test目录打包(-c创建): tar -cvf test.tar test/
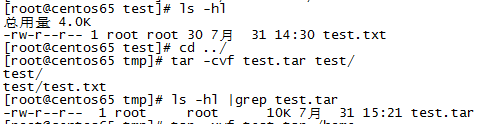
将test.tar解包(-x解压,-C指定目录):tar -xvf test.tar -C /home

或者进入某一目录后解压tar -xvf test.tar
系统相关
| 命令 | 简单说明 |
|---|---|
| top | 查看当前系统的进程运行情况 |
| free | 查看内存使用情况,如free -g,-g以G为单位显示内存 |
| df | 查看磁盘使用情况,如df -hl |
| du | 查看当前目录磁盘使用情况,如du -sh ./ |
| crontab | 查看系统的定时任务,如crontab -l |
| uname | uname -m,查看系统64或32位 |
| cat /etc/issue | 查看操作系统版本 |
进程相关
| 命令 | 简单说明 |
|---|---|
| ps | 查询进程ps -aux |
| netstat | 查看进程占用端口,netstat -nap |
| nohup | 后台运行进程(终端关闭也不挂起),如nohup ./test>/dev/null & |
| kill | kill -s 9 进程id,强制结束进程 |
进程崩溃定位(后面写makefile文件时会写示例)
(1)通过产生的core文件定位,gdb 进程文件名 core文件
bt或where定位到行
(2)addr2line,通过/var/log/messages
XXXXX[8751]: segfault at 40 ip0000000000499262sp 00007f670318db90 error 4 in
其中的ip后面的地址是程序出错处的地址
addr2line -e 进程文件名 0000000000499262 -f
网络相关
-
tcpdump(用于抓包)&wireshark(用于分析包)
- tcpdump抓包示例
tcpdump -c 20 -i eth2 tcp port 8080 and host 10.244.153.136 -w ./test.pcap
(1)-c表示抓包个数
(2)-i 表示指定网卡
(3)port表示指定TCP端口
(4)host表示指定主机
注意事项:
使用tcpdump进行抓包,然后用wireshark进行分析的时候,出现了”Packet size limited
during capture”
原因:
在Linux下进行抓包的时候没有设定截取包的长度,于是tcpdump默认采用了长度为68或96字节来进行抓包,导致一些数据稍多的包内容显示不全面。
解决方法:在tcpdump命令后加上-s0参数,则可以抓取任意长度的数据包
tcpdump -s0 -i eth4 tcp -w ./test.pcap - wireshark的一些常用过滤规则:
1、过滤目的地址为192.168.130.120端口为6088:ip.dst == 192.168.130.120 and tcp.port == 6088
2、http and ip.src == 10.201.172.164
3、url过滤:http.request.uri contains “getResult”
4、过滤POST请求http.request.method==POST
- tcpdump抓包示例
-
curl&Fiddler
- 传递普通参数
curl “http://127.0.0.1:6000/getResult?dateTime=201507&type=month”
web接口地址注意引号否则传递参数会出错
1、?连接作用
2、&不同参数的间隔符
3、如果参数存在空格,可以用+或者%20代替 - 传递JSON参数
curl -H “Content-Type: application/json” -X POST --data ‘{“dateTime”:“201507”,“type”:0}’ http://127.0.0.1:6000/updateResult - 传递xml参数(一般用于测试webservices)
curl -H “Content-Type: application/x-www-form-urlencoded;charset=UTF-8” --data @test.xml http://127.0.0.1:6000/test?wsdl
–data @test.xml表示输入的xml文件
- 传递普通参数