利用java爬取页面源码,并下载页面的音频文件。这里把一下几个链接作为爬取对象:
https://shimo.im/docs/uakS7kJTtPcQtqtt/
https://shimo.im/docs/OBhADp79JJ4oT5Ig/
https://shimo.im/docs/C8FXpypXN18mcZHa/
页面内有较多音频文件,一个一个下载比较麻烦。页面的部分源码如下:

可以看出
data-name和 data-url这两个是我们可以用到的数据,第一个是作为保存时的文件名,第二个是下载链接。
下面是java代码部分,目录结构如下图:
新建一个HtmlRequest.java,来通过网站域名URL获取该网站的源码
import java.io.ByteArrayOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.URL;
/**
* 通过网站域名URL获取该网站的源码
*
* @author Administrator
*
*/
public class HtmlRequest {
/** */
/**
* 通过网站域名URL获取该网站的源码
*
* @param url
* @return String
* @throws Exception
*/
public String getURLSource(URL url) throws Exception {
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
conn.setRequestMethod("GET");
conn.setConnectTimeout(5 * 1000);
InputStream inStream = conn.getInputStream(); // 通过输入流获取html二进制数据
byte[] data = readInputStream(inStream); // 把二进制数据转化为byte字节数据
String htmlSource = new String(data);
return htmlSource;
}
/** */
/**
* 把二进制流转化为byte字节数组
*
* @param instream
* @return byte[]
* @throws Exception
*/
public byte[] readInputStream(InputStream instream) throws Exception {
ByteArrayOutputStream outStream = new ByteArrayOutputStream();
byte[] buffer = new byte[1204];
int len = 0;
while ((len = instream.read(buffer)) != -1) {
outStream.write(buffer, 0, len);
}
instream.close();
return outStream.toByteArray();
}
}
在主方法Main.java中加入如下代码
import java.io.File;
import java.net.URL;
import java.util.Scanner;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Main {
public static void main(String[] args) throws Exception {
HtmlRequest httpRequest=new HtmlRequest();
Scanner sc = new Scanner(System.in);
String[] strs=sc.next().split(",");
for(int i=0;i<strs.length;i++) {
System.out.println("\n*****************第"+(i+1)+"条链接开始解析下载*****************");
System.out.println("下载链接:"+strs[i]);
URL url = new URL(strs[i]);
String urlsource = httpRequest.getURLSource(url);
// System.out.println(urlsource);//输出页面源码
Pattern p1 = Pattern.compile("data-url=\"(.*).mp3\"");
Pattern p2 = Pattern.compile("data-name=\\\"(.*).mp3\"");
Matcher m1 = p1.matcher(urlsource);
Matcher m2 = p2.matcher(urlsource);
String path = "E:\\英语四级\\单词专项提升\\四级单词Day" + (i+1) + "\\页面音频\\";
File file = new File(path);
if (!file.exists()) {
file.mkdirs();
System.out.println("创建文件夹..");
}
while(m1.find()&m2.find()) {
System.out.println(m1.group(1)+".mp3");
System.out.println(m2.group(1));
DownloadManager downloadManager = new DownloadManager(path+m2.group(1)+".mp3" , 2 , m1.group(1)+".mp3");
downloadManager.action();
}
}
System.out.println("*****************任务全部下载完成*****************");
}
}
下面新建DownloadManager.java实现多线程下载
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
public class DownloadManager implements Runnable {
// 保存路径
private String savePath;
// 总的下载线程数
private int threadNum;
// 下载的链接地址
private String urlFile;
// 是否下载开始
private boolean isStarted;
// 用于监视何时合并文件存放Thread的list
private List<DownloadThread> downloadList = new ArrayList<DownloadThread>();
public DownloadManager(String savePath, int threadNum, String urlFile) {
super();
this.savePath = savePath;
this.threadNum = threadNum;
this.urlFile = urlFile;
}
// 最终调用线程下载。本线程中调用分线程。
public void action() {
new Thread(this).start();
}
public void run() {
long t1 = System.currentTimeMillis();
System.out.println(t1);
// 如果没有下载 , 就开始 , 并且将已经下载的变量值设为true
if (!isStarted) {
startDownload();
isStarted = true;
}
while (true) {
// 初始化认为所有线程下载完成,逐个检查
boolean finish = true;
// 如果有任何一个没完成,说明下载没完成,不能合并文件
for (DownloadThread thread : downloadList) {
if (!thread.isFinish()) {
finish = false;
break;
}
}
// 全部下载完成才为真
if (finish) {
// 合并文件
mergeFiles();
// 跳出循环 , 下载结束
break;
}
// 休息一会 , 减少cpu消耗
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long t2 = System.currentTimeMillis();
System.out.println(t2);
System.out.println("下载用时:" + (t2 -t1));
}
public void startDownload() {
// 得到每个线程开始值 , 下载字节数大小
int[][] posAndLength = getPosAndLength();
// 根据下载信息创建每个下载线程,并且启动他们。
for (int i = 0; i < posAndLength.length; i++) {
int pos = posAndLength[i][0];
int length = posAndLength[i][1];
DownloadThread downloadThread = new DownloadThread(i + 1, length,
pos, savePath, urlFile);
new Thread(downloadThread).start();
downloadList.add(downloadThread);
}
}
/**
* 获得文件大小
*
* @return 文件大小
*/
public long getFileLength() {
System.out.println("获得文件大小 start......");
HttpURLConnection conn = null;
long result = 0;
try {
URL url = new URL(urlFile);
conn = (HttpURLConnection) url.openConnection();
// 使用Content-Length头信息获得文件大小
result = Long.parseLong(conn.getHeaderField("Content-Length"));
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (conn != null) {
conn.disconnect();
}
}
System.out.println("获得文件大小 end......" + result);
return result;
}
// 具体细节求出每个线程的开始位置和文件下载大小
public int[][] getPosAndLength() {
int[][] result = new int[threadNum][2];
int fileLength = (int) getFileLength();
int every = fileLength % threadNum == 0 ? fileLength / threadNum
: fileLength / threadNum + 1;
for (int i = 0; i < result.length; i++) {
int length = 0;
if (i != result.length - 1) {
length = every;
} else {
length = fileLength - i * every;
}
result[i][0] = i * every;
result[i][1] = length;
}
return result;
}
// 合并文件
public void mergeFiles() {
System.out.println("合并文件 start......");
OutputStream out = null;
try {
out = new FileOutputStream(savePath);
for (int i = 1; i <= threadNum; i++) {
InputStream in = new FileInputStream(savePath + i);
byte[] bytes = new byte[2048];
int read = 0;
while ((read = in.read(bytes)) != -1) {
out.write(bytes, 0, read);
out.flush();
}
if (in != null) {
in.close();
new File(savePath + i).delete();
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
System.out.println("合并文件 end......");
}
public String getSavePath() {
return savePath;
}
public void setSavePath(String savePath) {
this.savePath = savePath;
}
public int getThreadNum() {
return threadNum;
}
public void setThreadNum(int threadNum) {
this.threadNum = threadNum;
}
public String getUrlFile() {
return urlFile;
}
public void setUrlFile(String urlFile) {
this.urlFile = urlFile;
}
public boolean isStarted() {
return isStarted;
}
public void setStarted(boolean isStarted) {
this.isStarted = isStarted;
}
public List<DownloadThread> getDownloadList() {
return downloadList;
}
public void setDownloadList(List<DownloadThread> downloadList) {
this.downloadList = downloadList;
}
}
再新建一个DownloadThread.java,代码如下
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.HttpURLConnection;
import java.net.URL;
public class DownloadThread implements Runnable {
// 当前第几个线程 , 用于给下载文件起名 file1 file2 file3 ...
private int whichThread;
// 监听单一线程下载是否完成
private boolean isFinish;
// 本线程要下载的文件字节数
private int length;
// 本线程向服务器发送请求时输入流的首位置
private int startPosition;
// 保存的路径
private String savePath;
// 要下载的文件 , 用于创建连接
private String url;
public void run() {
HttpURLConnection conn = null;
InputStream in = null;
OutputStream out = null;
try {
System.out.println("正在执行的线程:" + whichThread);
URL fileUrl = new URL(url);
// 与服务器创建连接
conn = (HttpURLConnection) fileUrl.openConnection();
// 下载使用get请求
conn.setRequestMethod("GET");
// 告诉服务器 , 我是火狐 , 不要不让我下载。
conn.setRequestProperty(
"User-Agent",
"Firefox Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9.1.3) Gecko/20090824 Firefox/3.5.3");
// 这里是设置文件输入流的首位置
conn.setRequestProperty("Range", "bytes=" + startPosition + "-");
// 与服务器创建连接
conn.connect();
// 获得输入流
in = conn.getInputStream();
// 在硬盘上创建file1 , file2 , ...这样的文件 , 准备往里面写东西
out = new FileOutputStream(savePath + whichThread);
// 用于写入的字节数组
byte[] bytes = new byte[4096];
// 一共下载了多少字节
int count = 0;
// 单次读取的字节数
int read = 0;
while ((read = in.read(bytes)) != -1) {
// 检查一下是不是下载到了本线程需要的长度
if (length - count < bytes.length) {
// 比如说本线程还需要900字节,但是已经读取1000
// 字节,则用要本线程总下载长度减去
// 已经下载的长度
read = length - count;
}
// 将准确的字节写入输出流
out.write(bytes, 0, read);
// 已经下载的字节数加上本次循环字节数
count = count + read;
// 如果下载字节达到本线程所需要字节数,消除循环,
// 停止下载
if (count == length) {
break;
}
}
// 将监视变量设置为true
isFinish = true;
} catch (Exception e) {
e.printStackTrace();
} finally {
// 最后进行输入、输出、连接的关闭
if (in != null) {
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (conn != null) {
conn.disconnect();
}
}
}
public int getStartPosition() {
return startPosition;
}
public void setStartPosition(int startPosition) {
this.startPosition = startPosition;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public int getWhichThread() {
return whichThread;
}
public void setWhichThread(int whichThread) {
this.whichThread = whichThread;
}
public int getLength() {
return length;
}
public void setLength(int length) {
this.length = length;
}
public String getSavePath() {
return savePath;
}
public void setSavePath(String savePath) {
this.savePath = savePath;
}
public DownloadThread(int whichThread, int length, int startPosition,
String savePath, String url) {
super();
this.whichThread = whichThread;
this.length = length;
this.startPosition = startPosition;
this.savePath = savePath;
this.url = url;
}
public DownloadThread() {
super();
}
public boolean isFinish() {
return isFinish;
}
public void setFinish(boolean isFinish) {
this.isFinish = isFinish;
}
}
以上代码通过逗号来分割链接的,所以运行后需在控制台输入链接,下面是三个以逗号分割的链接,可以粘贴到控制到作为测试:
按回车后就可以在main方法里指定的目录看到下载的文件了。
需要下载其他页面的其他文件只需要修改页面链接、正则部分,以及文件格式后缀,正则部分可以根据需要增删,也就是下面圈出来的那部分:
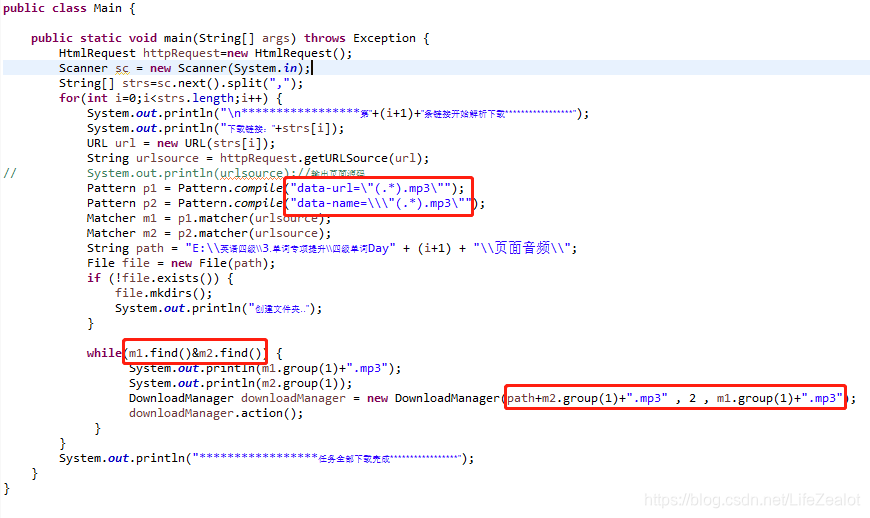
其中DownloadManager的实现参数分别是
1.保存路径,2.线程数,3.下载链接
本文有部分代码来自: