如果我们通过 Raft 算法实现了 KV存储,虽然领导者模型简化了算法实现和共识协商,但写请求只能限制在领导者节点上处理,导致了集群的接入性能约等于单机,那么随着业务发展,集群的性能可能就扛不住了,会造成系统过载和服务不可用。这时我们就要通过分集群,突破单集群的性能限制了。
常用的哈希算法是通过求模取余的方法,获得存储位置。但哈希算法存在明显的缺点:当需要变更集群数时(比如从 2 个集群扩展为 3 个集群),这时大部分的数据都需要迁移,重新映射,数据的迁移成本是非常高的。
一致哈希实现哈希寻址
一致哈希算法也用了取模运算,但与哈希算法不同的是,哈希算法是对节点的数量进行取模运算,而一致哈希算法是对 2^32 进行取模运算。你可以想象下,一致哈希算法,将整个哈希值空间组织成一个虚拟的圆环,也就是哈希环。哈希环的空间是按顺时针方向组织的,圆环的正上方的点代表 0,0点右侧的第一个点代表 1,以此类推,2、3、4、5、6……直到 2^32-1,也就是说 0 点左侧的第一个点代表 2^32-1。在一致哈希中,你可以通过执行哈希算法(为了演示方便,假设哈希算法函数为“c-hash()”),将节点映射到哈希环上,比如选择节点的主机名作为参数执行 c-hash(),那么每个节点就能确定其在哈希环上的位置了:当需要对指定 key 的值进行读写的时候,首先,将 key 作为参数执行 c-hash() 计算哈希值,并确定此 key 在环上的位置;然后,从这个位置沿着哈希环顺时针“行走”,遇到的第一节点就是 key 对应的节点。
避免大量数据移动
假设,现在有一个节点故障了(比如节点 C):
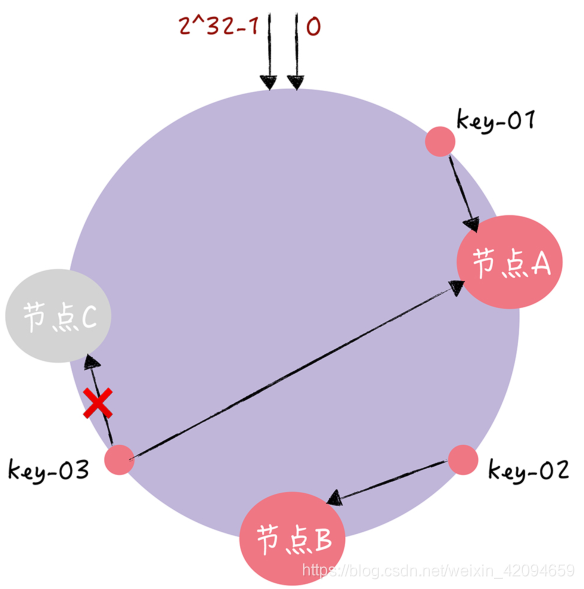
此时,key-01 和 key-02 不会受到影响,只有 key-03 的寻址被重定位到 A。一般来说,在一致哈希算法中,如果某个节点宕机不可用了,那么受影响的数据仅仅是,会寻址到此节点和前一节点之间的数据。总的来说,使用了一致哈希算法后,扩容或缩容的时候,都只需要重定位环空间中的一小部分数据。也就是说,一致哈希算法具有较好的容错性和可扩展性。
如何使数据均匀分布式各个服务器上
通过虚拟节点
虚拟节点:就是对每一个服务器节点计算多个哈希值,在每个计算结果位置上,都放置一个虚拟节点,并将虚拟节点映射到实际节点。当节点数越多的时候,使用哈希算法时,需要迁移的数据就越多,使用一致哈希时,需要迁移的数据就越少