写在前面:我是「云祁」,一枚热爱技术、会写诗的大数据开发猿。昵称来源于王安石诗中一句
[ 云之祁祁,或雨于渊 ],甚是喜欢。
写博客一方面是对自己学习的一点点总结及记录,另一方面则是希望能够帮助更多对大数据感兴趣的朋友。如果你也对数据中台、数据建模、数据分析以及 Flink/Spark/Hadoop/数仓开发感兴趣,可以关注我 https://blog.csdn.net/BeiisBei ,让我们一起挖掘数据的价值~
每天都要进步一点点,生命不是要超越别人,而是要超越自己! (ง •_•)ง
文章目录
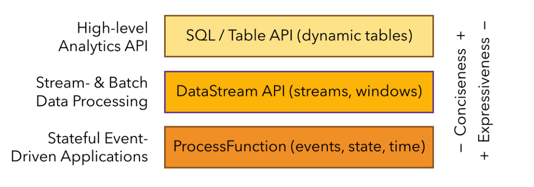
一、Table API 和 Flink SQL 是什么
- Flink 对批处理和流处理,提供了统一的上层API
- Table API 是一套内嵌在Java和Scala语言中的查询API,它允许以非常直观的方式组合来自一些关系运算符的查询
- Flink的SQL支持基于实现了SQL标准的Apache Calcite
二、基本程序结构
Table API 和 SQL 的程序结构,与流式处理的程序结构十分类似
val tableEnv = ... // 创建表的执行环境
// 创建一张表,用于读取数据
tableEnv.connect(...).createTemporaryTable("inputTable")
// 创建一张表,用于把计算结构输出
tableEnv.connect(...).createTemporaryTable("outputTable")
// 通过 Table API 查询算子,得到一张结果表
val result = tableEnv.from("inputTable").select(...)
// 通过 SQL 查询语句,得到一张结果表
val sqlResult = tableEnv.sqlQuery("SELECT ... FROM inputTable ...")
// 将结果表写入输出表中
result.insertInto("outputTable")
三、创建 TableEnvironment
- 创建表的执行环境,需要将flink流处理的执行环境传入
val tableEnv = StreamTableEnvironment.create(env)
-
TableEnvironment 是 flink 中集成Table API 和 SQL 的核心概念,所有对表的操作都基于 TableEnvironment
- 注册 Catalog
- 在 Catalog 中注册表
- 执行 SQL 查询
- 注册用户自定义函数(UDF)
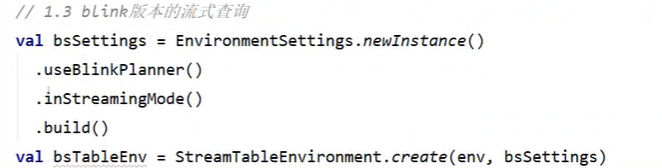
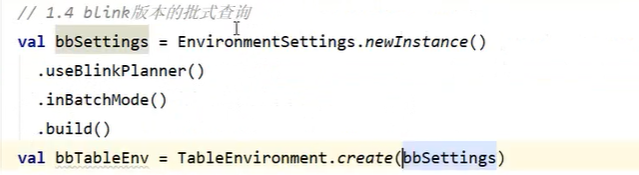
不同处理环境的定义:


四、表(Table)
- TableEnvironment 可以注册目录 Catalog,并可以基于 Catalog 注册表
- 表(Table)是由一个“标识符”(identifier)来指定的,由3部分组成:Catalog 名、数据库(database)名和对象名
- 表可以是常规的,也可以是虚拟的(视图,view)
- 常规表(Table)一般可以用来描述外部数据,比如文件、数据库或消息队列的数据,也可以直接从 DataStream 转换而来
- 视图(View)可以从现有的表中创建,通常是 table API 或者 SQL 查询的一个结果集
五、读取文件创建表
TableEnvironment 可以调用.connect() 方法,连接外部系统,并调用.createTemporaryTable() 方法,在 Catalog 中注册表
tableEnv
.connect(...) // 定义表的数据来源,和外部系统建立连接
.withFormat(...) // 定义数据格式化方法
.withSchema(...) // 定义表结构
.createTemporaryTable("MyTable") // 创建临时表
可以创建Table来描述文件数据,它可以从文件中读取,或者将数据写入文件


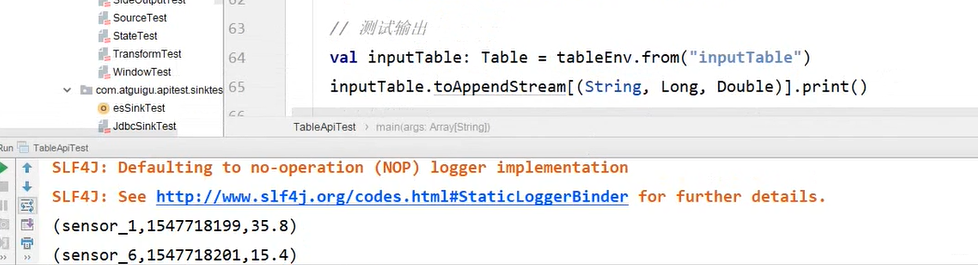
可以看到,我们从txt文件中读出六条数据,并以三元组的形式进行输出。
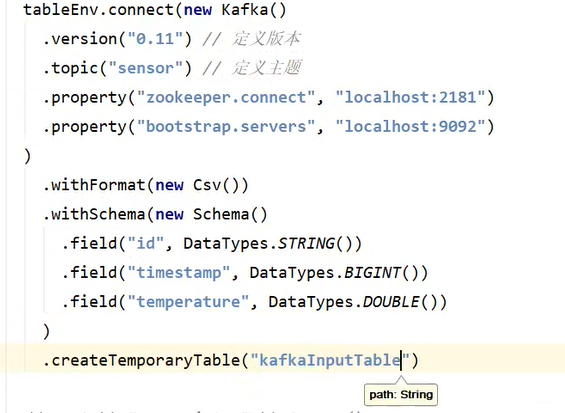
六、读取Kafka数据创建表
消费Kafka数据
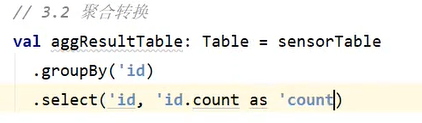
七、表的查询 - Table API & SQL
- Table API 是集成在 Scala 和 Java 语言内的查询API
- Table API 基于代表“表”的Table类,并提供一整套操作处理的方法API;这些方法会返回一个新的Table对象,表示对输入表应用转换操作的结果
- 有些关系型转换操作,可以由多个方法调用组成,构成链式调用结构
val sensorTable:Table = tableEnv.form("inputTable")
val resultTable:Table = sensorTable
.select("id,temperature")
.filter("id = 'sensor_1'")


测试结果如下:

true / false —> 表示数据是否是新增 or 撤回回收 。
SQL 查询示例:

八、表和流的相互转换
将 DataStream 转换成表
- 对于一个DataStream,可以直接转换成Table,进而方便地调用 Table API 做转换操作
val dataStream:DataStream[SensorReading] = ...
val sensorTable:Table = tableEnv.fromDataStream(dataStream)
- 默认转换后的 Table schema 和 DataStream 中的字段定义一一对应,也可以单独指定出来
val dataStream:DataStream[SensorReading] = ...
val sensorTable = tableEnv.fromDataStream(dataStream,
'id,'timestamp,'temperature)
数据类型与Schema的对应
- DataStream 中的数据类型,与表的 Schema 之间的对应关系,可以有两种:基于字段名称,或者基于字段位置
- 基于名称(name-based)
val sensorTable = tableEnv.formDataStream(
'timestamp as 'ts,'id as 'myId,'temperature)
- 基于位置(position-based)
val sensorTable = tableEnv.from
创建临时视图(Temporary View)
- 基于 DataStream 创建临时视图
tableEnv.createTemporaryView("sensorView",dataStream)
tableEnv.create