流式表达式流式表达式是jdk8带来的java的新特性详情: https://www.cnblogs.com/aiqiqi/p/11004208.htmlhttps://blog.csdn.net/weixin_37948888/article/details/96995312
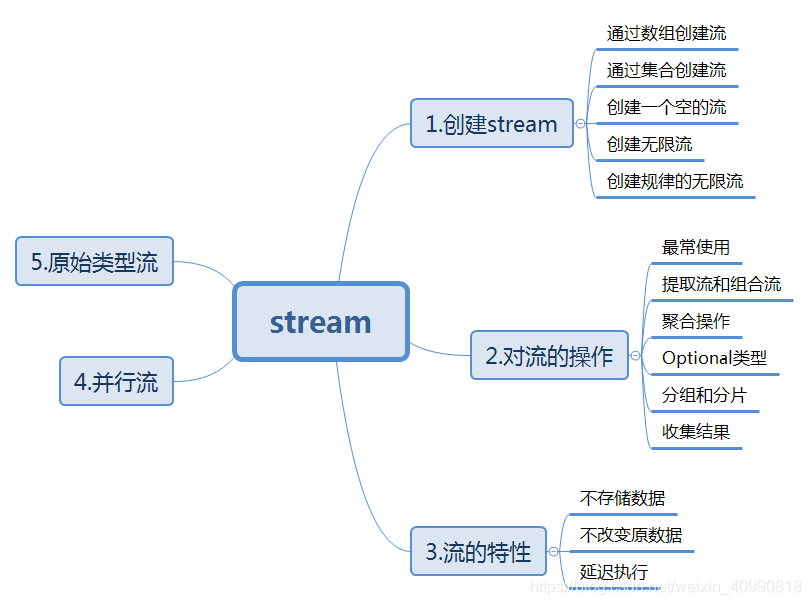
流式表达式的常见使用的场景
//1列出班上超过85分的学生姓名,并按照分数降序输出用户名字@Test
public void test1() {
List<String> studentList = stuList.stream()
.filter(x->x.getScore()>85)
.sorted(Comparator.comparing(Student::getScore).reversed())
.map(Student::getName)
.collect(Collectors.toList());
System.out.println(studentList);
}
创建流的方式
* 通过数组创建
* 通过集合创建
* 创建空的流
* 创建无限流(通过limit可以实现限制大小)
* 创建规律的无限流
普通流和并行流
并行流 就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流(其背后是Fork/Join框架)
Stream API可以声明性地通过parallel()与sequential()在并行流与顺序流之间进行切换。
List<String> strs = Arrays.asList("11212","dfd","2323","dfhgf");
//创建普通流
Stream<String> stream = strs.stream();
//创建并行流(即多个线程处理)
Stream<String> stream1 = strs.parallelStream();
在项目中经常使用的场景
//解决key值一对多的问题
Map<String, String> mmapCodeDeptName = mapAllDeptNameCode.stream().collect(Collectors.toMap( AllDeptNameCodePojo::getDeptCode,AllDeptNameCodePojo::getDeptName,(k,v)->v));
//解决 value可能为空的情况
Map<String, String> mmapCodeParentId = mapAllDeptNameCode.stream().collect(Collector.of(HashMap::new, (m, per)->m.put(per.getDeptCode(),per.getParentId()), (k, v)->v, Collector.Characteristics.IDENTITY_FINISH));
//截取(场景:分批次处理集合 相当于 List.subList())
add.stream().skip(i * 1000).limit(1000).collect(Collectors.toList())