《大话数据结构 》
第八章 查找
一、顺序查找
顺序查找又叫线性查找,是最基本的查找技术,它的查找过程是:从表中第一个(或最后一个)记录开始,逐个记性记录的关键字和给定值比较,若某个记录的关键字和给定值相等,则查找陈宫,找到所查的记录;如果直到最后一个(或第一个)记录,其关键字和给定值比较都不等时,则表中没有所查的记录,查找不成功。 时间复杂度为O(n)。
/*a为数组,n为数组个数,key为要查找的关键字*/
int Sequential_Search(int *a,int n, int key)
{
int i;
for(i=1;i<=n;i++)
{
if(a[i]=key)
return i;
}
return 0;
}
Sequential_Search中每次都要判断下标是否越界, 有稍微好点的方法可以不需要每次都让下标i和n做比较。此处 a[0]=key;可以保证while循环能够退出。a[0]被称为哨兵。当n较大时,你可以看出Sequential_Search大约要执行3n条语句,而Sequential_Search1执行2n条语句,相对来说减少了运行代码量。但是n很大时,查找效率显然低下。
/*优化,设置一个哨兵,不用每次都比较i与n,在查找最后设置一个哨兵*/
int Sequential_Search1(int *a,int n,int key)
{
int i;
a[0]=key;
i=n;
while(a[i]!=key)
{
i--;
}
return i;
}
二、有序表的查找
二分法查找
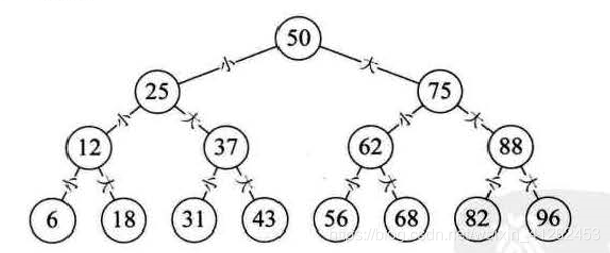
二分查找前提是线性表中数据是有序顺序存储。当有{6,12,18,25,31,37,50,56,62,68,75,82,88,96}有序数组,查找是否存在其中的一个数,对于有序表可以采用二分查找法。
/* 折半查找 */
int Binary_Search(int *a,int n,int key)
{
int low,high,mid;
low=1; /* 定义最低下标为记录首位 */
high=n; /* 定义最高下标为记录末位 */
while(low<=high)
{
mid=(low+high)/2; /* 折半 */
if (key<a[mid]) /* 若查找值比中值小 */
high=mid-1; /* 最高下标调整到中位下标小一位 */
else if (key>a[mid])/* 若查找值比中值大 */
low=mid+1; /* 最低下标调整到中位下标大一位 */
else
{
return mid; /* 若相等则说明mid即为查找到的位置 */
}
}
return 0;
}
插值查找-----改进的二分法查找
二分法中mid =(low+high)/2; 等于low+(high-low)*(1/2),问题是问什么是折半,而不是折四分之一或者更多呢?例如,在英文词典中你要查zoo,你肯定不会从中间开始查起,而是有目的性的往后翻。插值查找是根据要查找的关键字key与查找表中最大最小记录的关键字比较的查找方法,核心是插值的计算公式。
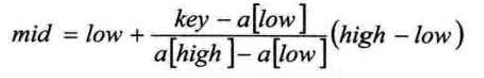
代码实现:
/* 插值查找 */
int Interpolation_Search(int *a,int n,int key)
{
int low,high,mid;
low=1; /* 定义最低下标为记录首位 */
high=n; /* 定义最高下标为记录末位 */
while(low<=high)
{
mid=low+ (high-low)*(key-a[low])/(a[high]-a[low]); /* 插值 */
if (key<a[mid]) /* 若查找值比插值小 */
high=mid-1; /* 最高下标调整到插值下标小一位 */
else if (key>a[mid])/* 若查找值比插值大 */
low=mid+1; /* 最低下标调整到插值下标大一位 */
else
return mid; /* 若相等则说明mid即为查找到的位置 */
}
return 0;
}
三、斐波那契查找
除了插值算插值,也除了二分法中的固定1/2,还有利用斐波那契法的黄金分割比例。斐波那契是二分法的改进版,他跟插值查找类似。不同的是它利用了数学领域的黄金分割法则(也就是0.618法则),它避免死板的二分法则,在概率学领域减少了查找次数。
要使用斐波那契查找算法,1、首先要有一个斐波那契数列。斐波那契数列在下文中用F表示。
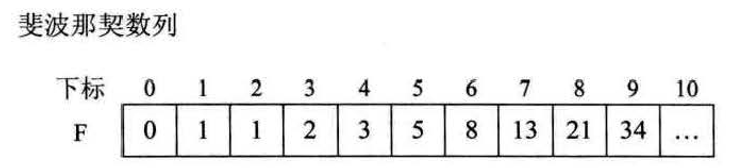
如果我要查找一个数组a{0,1,16,24,35,47,59,62,73,88,99},长度n是10,我要查找的关键字是59,我要查出59是否存在,若存在下标多少。2、需要循环找出a的长度对应斐波那契数列是F(k-1)和F(k)之间的k是多少,可以看出我要查找的数组a长度是10,10在斐波那契数列F中对应的是F(6)和F(7)之间,因此k=7。 3、将原有的数组补齐至长度F[k]-1,因为F(7)是13,而a的长度只有10,循环将a[11]、a[12]都用a[10]补齐。
这样以后,相当于将原来的数组a至少在长度上达到F[k]-1的关系。如下图,这个是待查找数组的结构,我们一定要注意左侧的长度是F[k-1],右侧的长度是F[k-2]-1。而mid位于位于这两段之间,左侧F[k-1]-1长度是大于F[k-2]-1的,所以后面调整k值时,分 k=k-1和k=k-2情形。
4、开始第一次查找,mid = low +F[k-1] - 1;
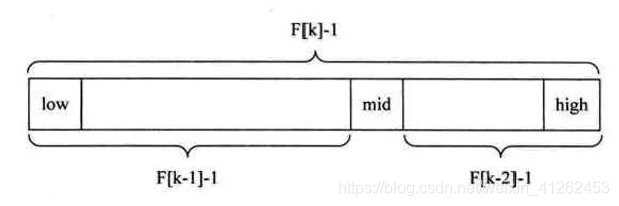
第一次查找,low = 1,k = 7,high = 12,mid = 1+F[6] -1 = 8; 得到a[mid] = a[8] = 73; 接下来a[mid]和key对比,对比看是调整high还是low,key<a[mid],说明要搜索的key在F[k-1]-1侧,则high = mid-1; k = k-1;
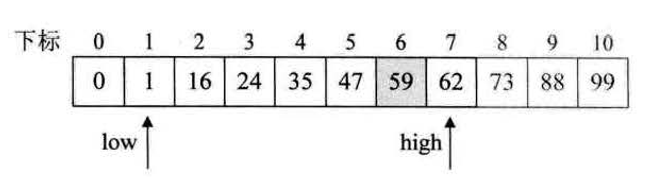
第二次查找,low = 1,high = 9,k =,6,mid = 1+F[5] - 1 = 5;得到a[mid] = a[5] = 47; 发现a[5] = 47<key;说明key在F[k-2]-1这一段中。则low = mid+1; k = k-2;
线性索引查找
稠密索引:稠密索引是指在线性索引中,将数据集中的每个记录对应一个索引项。 稠密索引要应对的可能是成千上万的数据,因此对于稠密索引这个索引表来说,索引项一定是按照关键码有序的排列。
分块索引 :例子:图书馆藏书。 分块有序,是把数据集的记录分成了若干块,将每块对应一个索引项。
分块索引的索引项结构分为三个数据项:
- 最大关键码,存储每一块中的最大关键字;
- 存储了块中的记录个数,以便循环时用;
- 用于指向块首数据元素的指针,便于开始对这一块中记录进行遍历。
倒排索引:网页搜索一般用的就是倒排索引。
二叉排序树
二叉排序树性质:构建二叉排序树的目的是为了提高查找和插入删除关键字的速度。
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结构的值
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结构的值
- 它的左、右子树也分别为二叉排序树
二叉树孩子表示法数据结构:
/* 二叉树的二叉链表结点结构定义 */
typedef struct BiTNode /* 结点结构 */
{
int data; /* 结点数据 */
struct BiTNode *lchild, *rchild; /* 左右孩子指针 */
} BiTNode, *BiTree;
二叉排序树的查找
指针f指向T的双亲,其初始调用值为NULL。注意在二叉树查找中,并不像普通的二叉树查找需要遍历所有结点,通过查找的关键字key和当前的结点T->data进行比较,选择是向左子树查找还是右子树查找,所以若查找成功p是指向查找关键字key。若查找失败返回False,同时查找的得到的结果p是查找路径上访问的最后一个结点,该结点必然也是大小最靠近查找key的位置结点。若树不存在,那么p第一次指向判断就返回FALSE,同时p = f,f调用时是NULL,则*p即NULL。
/* 递归查找二叉排序树T中是否存在key, */
/* 指针f指向T的双亲,其初始调用值为NULL */
/* 若查找成功,则指针p指向该数据元素结点,并返回TRUE */
/* 否则指针p指向查找路径上访问的最后一个结点并返回FALSE */
Status SearchBST(BiTree T, int key, BiTree f, BiTree *p)
{
if (!T) /* 查找不成功 */
{
*p = f;
return FALSE;
}
else if (key==T->data) /* 查找成功 */
{
*p = T;
return TRUE;
}
else if (key<T->data)
return SearchBST(T->lchild, key, T, p); /* 在左子树中继续查找 */
else
return SearchBST(T->rchild, key, T, p); /* 在右子树中继续查找 */
}
二叉排序树的插入
插入前先进行查找判断:
- 若二叉排序树不存在,则*p = f; 而调用时查找函数时,f = NULL,所以p = NULL。 所以插入的值直接当根结点。
- 若二叉树存在,并且查找出需要插入的Key已经存在,查找函数SearchBST会返回该结点的位置,那么不插入。
- 若二叉树存在,并且需要插入的key还没存在,那么根据最后浏览的结点,也是大小最靠近插入key的结点,判断key是作为左子树还是右子树好。
/* 当二叉排序树T中不存在关键字等于key的数据元素时, */
/* 插入key并返回TRUE,否则返回FALSE */
Status InsertBST(BiTree *T, int key)
{
BiTree p,s;
if (!SearchBST(*T, key, NULL, &p)) /* 查找不成功 */
{
s = (BiTree)malloc(sizeof(BiTNode));
s->data = key;
s->lchild = s->rchild = NULL;
if (!p)
*T = s; /* 插入s为新的根结点 */
else if (key<p->data)
p->lchild = s; /* 插入s为左孩子 */
else
p->rchild = s; /* 插入s为右孩子 */
return TRUE;
}
else
return FALSE; /* 树中已有关键字相同的结点,不再插入 */
}
二叉排序树的删除
请神容易送神难,二叉排序树中删除是最难的。
- 当要删除的结点是叶子结点,简直是最幸运的,直接删除,其他结点的结构并不会收到影响。
- 要删除的结点只有左子树或者只有右子树,相对来说也还比较好解决,子承父业!那就是结点删除后,将它的左子树或者右子树整个移动到删除结点的位置即可。
- 若删除的结点既有左子树又有右子树,例如下图中,二叉排序树{29,35,36,37,47,48,49,50,51,56,58,62,73,88,93,99}中要删除结点47,比较好的办法是找到47的前驱或者后继s,用s代替47,再删除s,删除s的同时会判断s是否属于1、2情形。
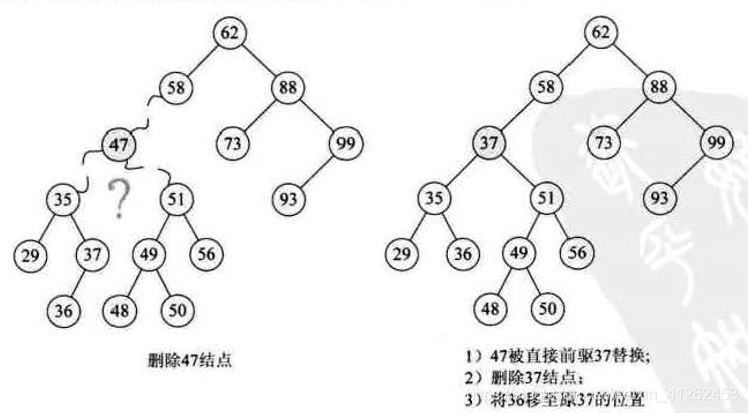
代码实现:
/* 从二叉排序树中删除结点p,并重接它的左或右子树。 */
Status Delete(BiTree *p)
{
BiTree q,s;
if((*p)->rchild==NULL) /* 右子树空则只需重接它的左子树(待删结点是叶子也走此分支) */
{
q=*p; *p=(*p)->lchild; free(q);
}
else if((*p)->lchild==NULL) /* 只需重接它的右子树 */
{
q=*p; *p=(*p)->rchild; free(q);
}
else /* 左右子树均不空 */
{
q=*p; s=(*p)->lchild;
while(s->rchild) /* 转左,然后向右到尽头(找待删结点的前驱) */
{
q=s;
s=s->rchild;
}
(*p)->data=s->data; /* s指向被删结点的直接前驱(将被删结点前驱的值取代被删结点的值) */
if(q!=*p)
q->rchild=s->lchild; /* 重接q的右子树 */
else
q->lchild=s->lchild; /* 重接q的左子树 */
free(s);
}
return TRUE;
}
/* 若二叉排序树T中存在关键字等于key的数据元素时,则删除该数据元素结点, */
/* 并返回TRUE;否则返回FALSE。 */
Status DeleteBST(BiTree *T,int key)
{
if(!*T) /* 不存在关键字等于key的数据元素 */
return FALSE;
else
{
if (key==(*T)->data) /* 找到关键字等于key的数据元素 */
return Delete(T);
else if (key<(*T)->data)
return DeleteBST(&(*T)->lchild,key);
else
return DeleteBST(&(*T)->rchild,key);
}
}
过程解析:1、此段删除只有左子树或者只有右子树的代码是最简单的,只需要将该结点的左孩子或者右孩子替换自己,然后是否该结点内存。
if((*p)->rchild==NULL) /* 右子树空则只需重接它的左子树(待删结点是叶子也走此分支) */
{
q=*p; *p=(*p)->lchild; free(q);
}
else if((*p)->lchild==NULL) /* 只需重接它的右子树 */
{
q=*p; *p=(*p)->rchild; free(q);
}
2、执行 q=*p; s=(*p)->lchild; 将要删除的结点p赋值给q,再将p的左孩子p->lchild赋值给临时的变量s,此时q指向47结点,s指向35结点。
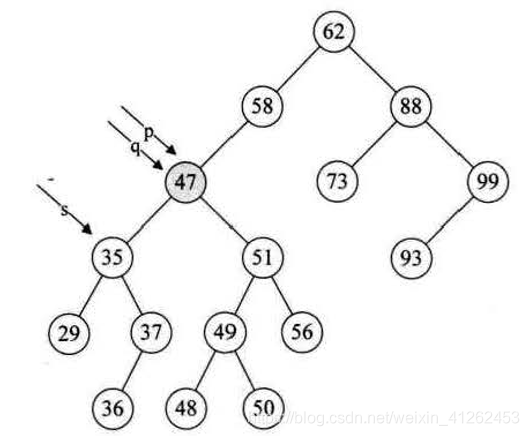
3、执行下面循环,循环找到左子树的右结点,直到右侧尽头s,当前例子,让q执行35,而s指向37这个再没有右子树的结点。这样可以找到47的前驱,37就是47的前驱。
while(s->rchild) /* 转左,然后向右到尽头(找待删结点的前驱) */
{
q=s;
s=s->rchild;
}
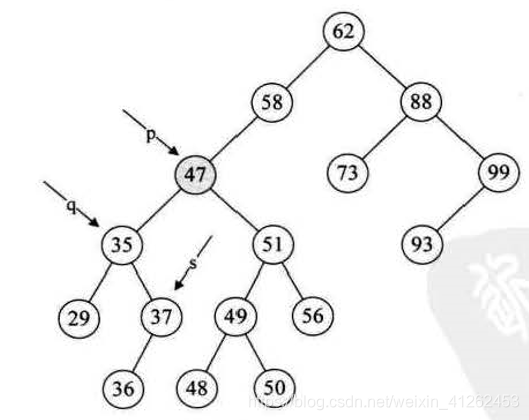
4、执行(*p)->data=s->data;此时让要删除的结点p的位置数值赋值为s->data,即让要删除的结点数值数据赋值为前驱s的值。
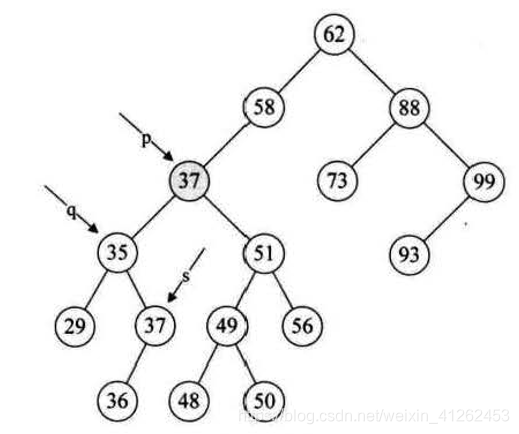
5、执行如果p和q的指向不同,这里显然p和q指向不同的结点,就让s的左结点36赋值给q的右结点。如果要删除的是88结点,那么执行到这一步q和p指向的是相同的结点,那么把原88结点(会被73结点替换)的左子树替换成原73结点的左子树NULL。最后释放s,前驱。
if(q!=*p)
q->rchild=s->lchild; /* 重接q的右子树 */
else
q->lchild=s->lchild; /* 重接q的左子树 */
free(s);
平衡二叉树(AVL树)
平衡二叉树特点:
- 首先是一种二叉排序树
- 二叉树上任一结点的左子树深度减去右子树深度(平衡因子)只能是1、-1、0
平衡因子:二叉树结点的左子树深度减去右子树深度的值。只要二叉树上有一个结点的平衡因子绝对值大于1,那么这个二叉树就是不平衡的。下图中,图1个人感觉应该不是平衡二叉树,58结点的平衡因子为2,应该是书出的有误。图2,不是二叉排序树,所以更不是平衡二叉树。图3的58结点,平衡因子绝对值超过了1,所以不是平衡二叉树。
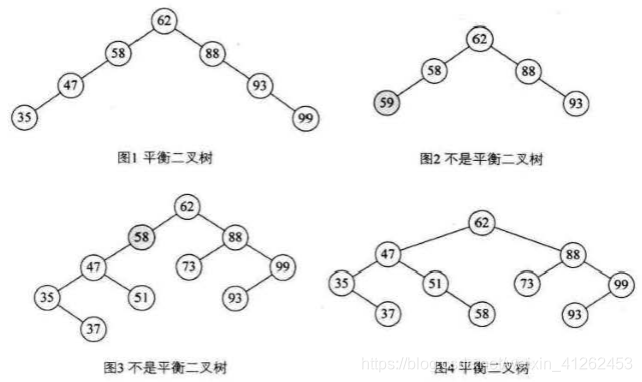
最小不平衡子树:距离插入结点最近的,且平衡因子的绝对值大于1的结点为根的子树。例如,下图的58开始以下的子树
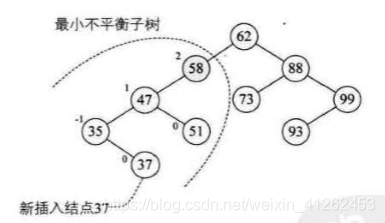
平衡二叉树实现的思想:每插入一个结点时,先检查是否因插入而破坏了树的平衡性,若是,则找出最小不平衡子树。在保持二叉排序树特性的前提下,调整最小不平衡子树之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
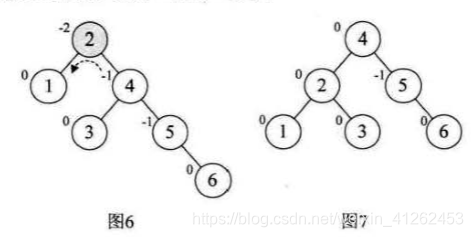
如何进行旋转的例子:若有树1,2,插入3后,3结点的不平衡因子变成了2,树变成了最小不平衡子树,因此要进行调整。因为不平衡因子为正2,所以进行右旋转,得到图2。再插入4,变成图3,图3是平衡子树。
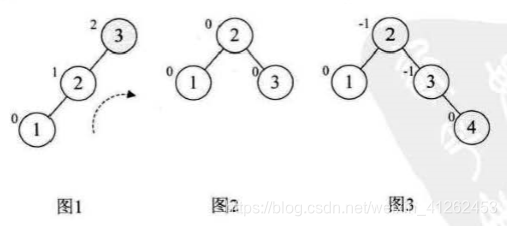
对图4进行再插入5,此时结点3的不平衡因子是-2,由于是负值,所以要对这颗最小不平衡子树进行左旋转,得到图5,此时树又发生了旋转。
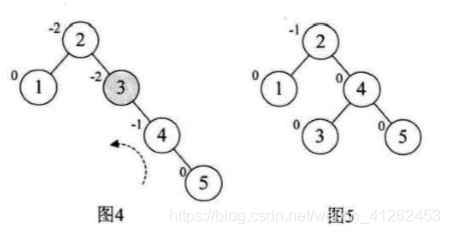
图5增加结点6时,结点2的不平衡因子变成-2,得到图6.所以对根结点进行了左旋,注意本来结点3是4的左孩子,由于旋转后需要满足二叉排序树特性,因此结点3成了结点2的右孩子,此处情况有些复杂。
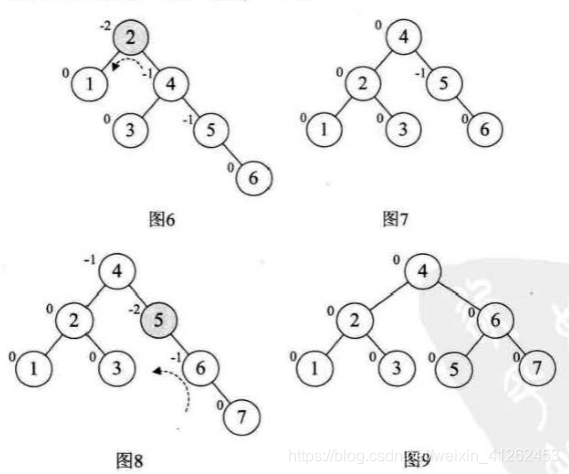
当增加结点10,结构还是平衡的,得到图10。往图10中增加结点9,此时结点7的不平衡因子变成-2,按照之前的理论,我们只需要旋转最小不平衡子树7、9、10即可,但是你发现左旋后,是不满足二叉排序树的要求的,7—>10---->9是不满足从小到大的。此时如何识别出这种情况,根本原因在于结点7的平衡因子是-2,但是结点10的平衡因子是1,符号不统一,而之前的几次旋转最小不平衡子树的根结点与它的子结点符号是相同的,因此解决办法是先将10、9 进行右旋转,再以7为根结点进行左旋转,得到图13。
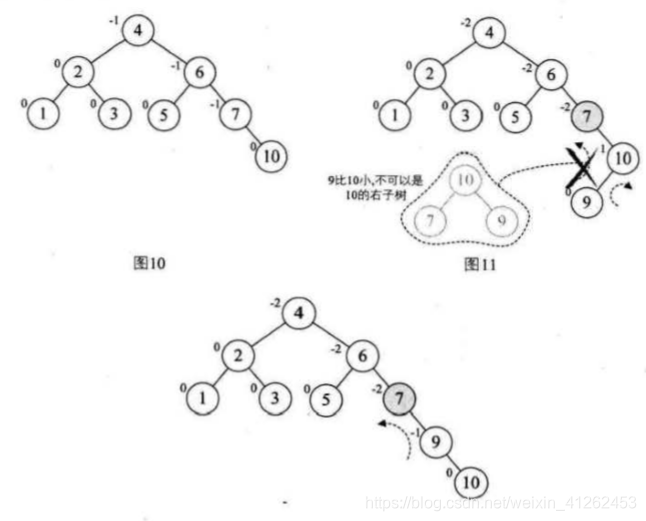
图14中的最小不平衡子树是以6为根结点的,结点6的不平衡度的-2,而它的右孩子9的不平衡度是1,因此要首先以9为根结点进行右旋转,得到图15,再以结点6为根结点进行左旋转,得到图16。
平衡二叉树结点数据结构:
/* 二叉树的二叉链表结点结构定义 */
typedef struct BiTNode /* 结点结构 */
{
int data; /* 结点数据 */
int bf; /* 结点的平衡因子 */
struct BiTNode *lchild, *rchild; /* 左右孩子指针 */
} BiTNode, *BiTree;
平衡二叉树实现算法
右旋转:当传入二叉树P,先将它的左孩子结点定义为L,将L的右子树变成P的左子树,再将P改成L的右子树,最后将L替换P成为根结点。
代码实现:
/* 对以p为根的二叉排序树作右旋处理, */
/* 处理之后p指向新的树根结点,即旋转处理之前的左子树的根结点 */
void R_Rotate(BiTree *P)
{
BiTree L;
L=(*P)->lchild; /* L指向P的左子树根结点 */
(*P)->lchild=L->rchild; /* L的右子树挂接为P的左子树 */
L->rchild=(*P);
*P=L; /* P指向新的根结点 */
}
左旋转:之前的图6到图7就是左旋操作,左旋和右旋原理一样。一开始,2是旋转根结点,左旋完4肯定是根结点,先将4的左子树变成2的右子树,再将2变成4的左子树,4成为根结点。
代码实现:
/* 对以P为根的二叉排序树作左旋处理, */
/* 处理之后P指向新的树根结点,即旋转处理之前的右子树的根结点0 */
void L_Rotate(BiTree *P)
{
BiTree R;
R=(*P)->rchild; /* R指向P的右子树根结点 */
(*P)->rchild=R->lchild; /* R的左子树挂接为P的右子树 */
R->lchild=(*P);
*P=R; /* P指向新的根结点 */
}
左平衡旋转:
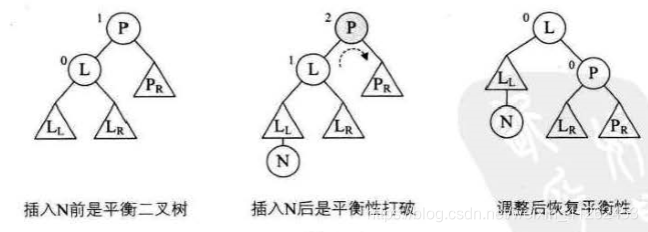
例如下图中,插入N之前是平衡二叉树,插入N后平衡性被打破。注意:此处定义平衡因子LH = 1表示左高。平衡因子EH = 0,表示平衡。平衡因子RH = -1表示右高。
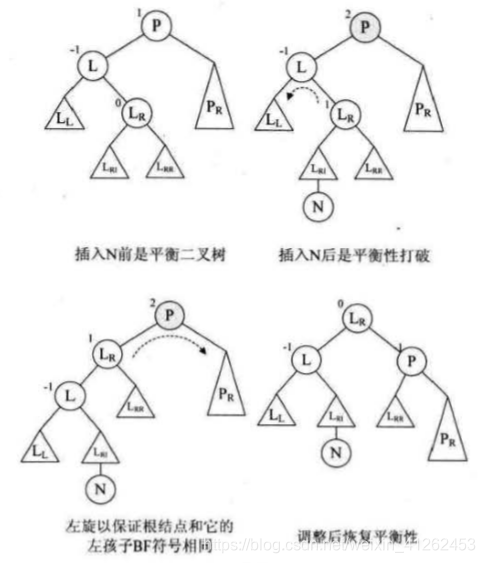
- 函数被调用时,传入插入N被打破的非平衡二叉树T,在调用LeftBalance函数时,其实是已经确认当前子树是左不平衡状态(即T的根结点应该是平衡因子BF的值大于1的数),对根结点的左子树根结点L平衡因子进行判断,此处将T的左孩子赋值给L,对L的平衡因子进行判断。
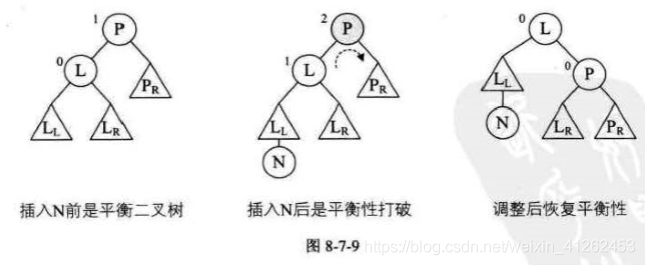
- 当L的平衡因子是正的时候,表明它与根结点的BF值符号相同,因此将它们的BF值都改为0,进行右旋操作即可。例如图8-7-9。
- 然而此时,L的平衡因子是负的,-1,与根结点BF值符号相反,因此此时需要做双旋处理。要先进行左旋,那么要找L的右孩子Lr,对Lr的平衡因子做判断,是LH,先(*T)->bf =EH,注意最终双旋后原来的根结点P会变成平衡。而L->br = RH,L的平衡因子变成RL(最后一幅图明显可以看到左低右高)。最后还要对L结点平衡因子置为0。
#define LH +1 /* 左高 */
#define EH 0 /* 等高 */
#define RH -1 /* 右高 */
/* 对以指针T所指结点为根的二叉树作左平衡旋转处理 */
/* 本算法结束时,指针T指向新的根结点 */
void LeftBalance(BiTree *T)
{
BiTree L,Lr;
L=(*T)->lchild; /* L指向T的左子树根结点 */
switch(L->bf)
{ /* 检查T的左子树的平衡度,并作相应平衡处理 */
case LH: /* 新结点插入在T的左孩子的左子树上,要作单右旋处理 */
(*T)->bf=L->bf=EH;
R_Rotate(T);
break;
case RH: /* 新结点插入在T的左孩子的右子树上,要作双旋处理 */
Lr=L->rchild; /* Lr指向T的左孩子的右子树根 */
switch(Lr->bf)
{ /* 修改T及其左孩子的平衡因子 */
case LH: (*T)->bf=EH;
L->bf=RH;
break;
case EH: (*T)->bf=L->bf=EH;
break;
case RH: (*T)->bf=EH;
L->bf=LH;
break;
}
Lr->bf=EH;
L_Rotate(&(*T)->lchild); /* 对T的左子树作左旋平衡处理 */
R_Rotate(T); /* 对T作右旋平衡处理 */
}
}
右平衡旋转:
/* 对以指针T所指结点为根的二叉树作右平衡旋转处理, */
/* 本算法结束时,指针T指向新的根结点 */
void RightBalance(BiTree *T)
{
BiTree R,Rl;
R=(*T)->rchild; /* R指向T的右子树根结点 */
switch(R->bf)
{ /* 检查T的右子树的平衡度,并作相应平衡处理 */
case RH: /* 新结点插入在T的右孩子的右子树上,要作单左旋处理 */
(*T)->bf=R->bf=EH;
L_Rotate(T);
break;
case LH: /* 新结点插入在T的右孩子的左子树上,要作双旋处理 */
Rl=R->lchild; /* Rl指向T的右孩子的左子树根 */
switch(Rl->bf)
{ /* 修改T及其右孩子的平衡因子 */
case RH: (*T)->bf=EH;
R->bf=LH;
break;
case EH: (*T)->bf=R->bf=EH;
break;
case LH: (*T)->bf=EH;
R->bf=RH;
break;
}
Rl->bf=EH;
R_Rotate(&(*T)->rchild); /* 对T的右子树作右旋平衡处理 */
L_Rotate(T); /* 对T作左旋平衡处理 */
}
}
多路查找树(B树)
多路查找树,其每个结点的孩子数可以多于两个,并且每个结点可以存储多个元素。
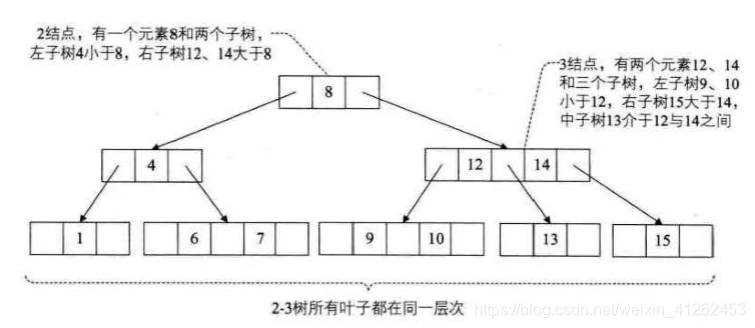
2-3树:2-3树是一棵多路查找树:其中的每一个结点都具有两个孩子(称为2结点)或三个孩子(称为3结点)。 一个2结点包含一个元素和两个孩子(或没有孩子)。 一个3结点包含一小一大两个元素和三个孩子(或没有孩子)。
2-3-4树:2-3-4树是2-3树的扩展,包括了4个结点的使用。一个结点包含小中大三个元素和四个孩子(或没有孩子)。
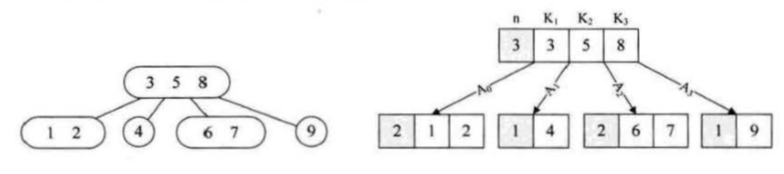
B树:B树是一种平衡的多路查找树,2-3树和2-3-4树都是B树的特例。结点最大的孩子数目称为B树的阶,因此,2-3树是3阶的B树,2-3-4树是4阶的B树。
散列表查找(哈希表)概述
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。查找时,根据这个确定的对应关系找到给定值key的映射f(key),若查找集合中存在这个记录,则必定在f(key)的位置上。 我们把上述的对应关系f称为散列函数,又称为哈希函数。采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表后哈希表。