机器学习概论1
1、机器学习定义
机器学习是一门多领域交叉学科,专门研究计算机怎样模拟或实现人类的学习行为,以获取新知识或技能,重新组织已有的知识结构使之不断改善自身的性能。——from百度百科
机器学习是通过训练数据集来训练模型,在遇到未知数据时,通过训练好的模型来得出结果。
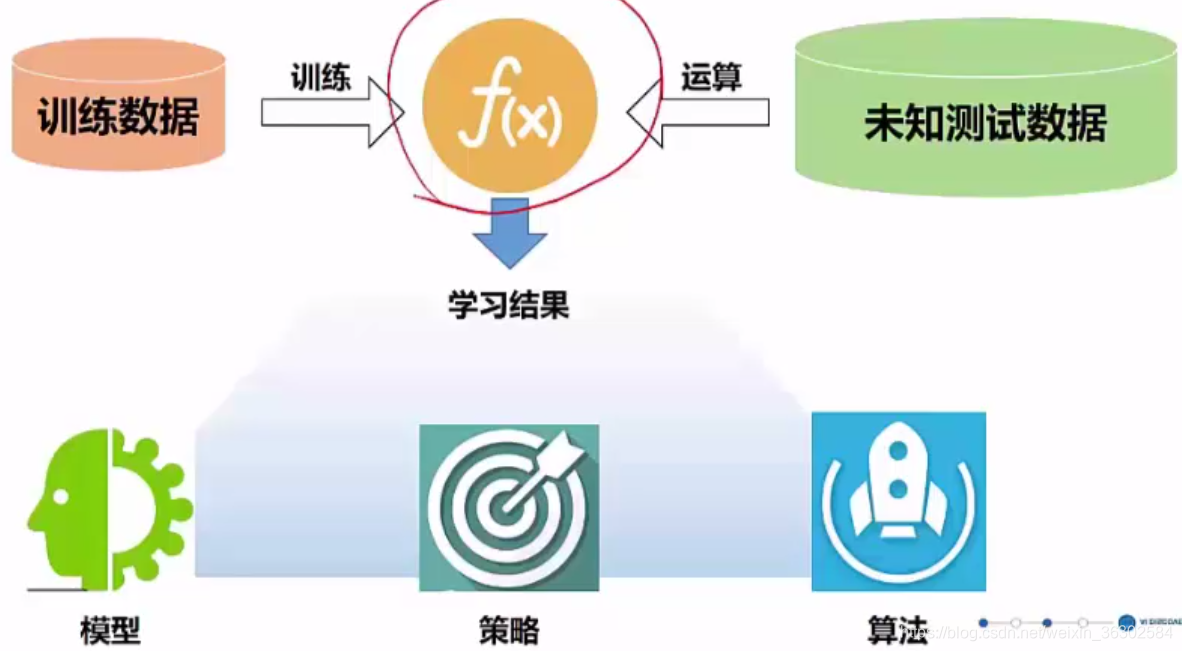 学习的重点在于学习这个模型( 即f(x) ),其由三部分组成
学习的重点在于学习这个模型( 即f(x) ),其由三部分组成
- 模型定义:针对具体问题所作的假设空间,即确定要训练的模型
- 策略:对模型学习结果的评价标准,引导模型的学习方向
- 算法:如何求解模型参数
2、机器学习方法分类
- 有监督学习:从给定的有标签(label)的训练数据集中学习出一个函数(模型参数),当新的数据到来时可以根据这个函数预测结果。常见任务包括分类与回归 ,如鸢尾花分类,房价预测
- 无监督学习:没有标签的训练数据集,需要根据样本间的统计规律对样本集进行分析,常见任务如聚类等。
- 半监督学习:结合(少量的)标签训练数据和(大量的)无标签数据来进行数据的分类学习

- 增强学习:外部环境对输出只给出评价信息而非正确答案,学习机通过强化受奖励的动作来改善自身的性能 。类似于小孩子走路,成功走一步后将会获得奖励,以此来告诉他这个动作的正确性。如:游戏AI

- 多任务学习:把多个相关的任务放在一起同时学习。如:将猫狗分类和猫羊分类两个任务作为一个任务来学习,这样习得的模型具有更好的泛化效果
3、机器学习面临的难题和挑战
- 数据稀疏性:训练模型需要大量(标注)数据,但往往数据比较稀疏,难以训练一个比较准确的模型
- 高数量和高质量标注数据需求:获取标注数据需要耗费大量资源
- 冷启动问题:对于新产品而言,需要面临数据不足的冷启动问题
- 泛化问题:训练数据不能全面、均衡地代表真实数据
- 模型抽象困难(模型):总结归纳实际问题中的数学表示非常困难
- 模型评估问题(策略):实际问题中,很难形式化地、定量地评估一个模型的结果好坏
- 寻找最优解困难(算法):要解决的问题复杂,将其形式化后的目标函数也复杂,往往不能找到一个有效算法来得到目标函数的最优值
- 可扩展性、可伸缩性(scalability):将模型训练时间通过分布式计算构架缩短
- 速度:模型实际使用时得出结果的速度应该在用户可接受范围
- 在线学习:能及时学习互联网中产生的新数据,从而更新模型
4、机器学习流程
 ________________________________________________________________________________
________________________________________________________________________________
4.1 数据预处理
4.1.1 数据清洗
对各种脏数据进行对应方式的处理,得到标准、干净、连续的数据,保证数据的完整性、数据的合法性、数据的一致性、数据的唯一性、数据的权威性,然后提供给数据统计、数据挖掘等使用。
- 数据的完整性
解释:保证数据中特征值的完整,如通过人类年龄和性别预测身高时,不能缺少年龄或性别这些数据。可以通过信息补全
方法:信息补全、剔除数据 - 数据的合法性
解释:即数据应与常识相符合,如年龄不能小于0岁
方法:设置字段内容格式(不满足格式的数据不存)、类型的合法规则(不满足格式的数据不取) - 数据的一致性
解释:保证来自不同来源的不同指标的数据,其实际含义是一致的,如170cm和1.7m的含义是一样的
方法:建立数据体系,包含但不限于指标体系、维度、单位、频度等(通俗来讲就是用同一个标准来描述数据,如长度均以厘米cm为单位) - 数据的唯一性(可选)
解释:保证数据不重复
方法:按主键去重(用sql或excel)、按规则去重(如不同渠道来的客户数据,可以通过相同的关键信息进行匹配,合并去重) - 数据的权威性
解释:多个来源的数据,如果发生冲突,优先选择权威的数据
方法:为不同渠道设置权威级别
4.1.2 数据采样
不正确的采样方法容易造成数据不平衡
- 数据不平衡
解释:数据集的类别分布不均,比如在二分类问题中,有99个正类样本和1个负类样本,这造成数据不平衡,这对模型训练是无益的
解决方法:过采样(增加少数类样本)、欠采样(减少多数类样本)
4.1.3 数据集拆分
机器学习中通常将数据划分为3份
训练数据集(train dataset):用来构建机器学习模型
验证数据集(validation dataset):辅助构建模型,用于在构建过程中评估模型,提供无偏估计,进而调整模型参数
测试数据集(test dataset):用来评估训练好的最终模型的性能

- 常用划分方法
留出法(hold-out):直接将数据集划分为互斥的集合,如通常选择70%数据作为训练集,30%数据作为测试集。应保持划分后集合数据分布的一致性,避免在划分过程中引入额外的偏差而对最终结果产生影响。这可能会导致测试集中数据有关键信息没学习到,影响模型精度,所以有k-折交叉验证法
K-折交叉验证法:将数据集划分为K个大小相似的互斥子集,从而获取k组训练-测试集,进行k次训练和测试,这样能够充分使用和学习数据
4.2 特征工程
4.2.1 特征编码
将数据转换为数值形式进行编码,便于计算机处理。通俗来讲就是将人看得懂而计算机看不懂的信息转换为计算机看得懂的信息
- 两种编码方法
one-hot编码:采用N位状态寄存器来对N各状态进行编码,如假设年龄段有四个类别:少年,青年,中年,老年。可用0001表示少年,0010表示青年,0100表示中年,1000表示中年
语义编码:one-hot编码无法体现数据间的语义关系,对于这一类信息通常采用词嵌入(word embedding)的方式,这样可以编码语义信息,生成特征语义表示,如google的word2vec方法
4.2.2 特征选择
选择有用的特征,如在通过性别和年龄预测身高时,不需要选择名字、出生日期等对结果无关的属性特征
- 三种特征选择方法

4.2.3 特征降维
定义:特征选择完成后,可能由于特征矩阵过大,导致计算量大、训练时间长,因此需要降低特征矩阵维度
扫描二维码关注公众号,回复:
11472141 查看本文章

- 两种特征降维方法

4.2.4 规范化
不同属性具有不同量级,即不同属性间的标准不同,会导致:数量级的差异将导致量级较大的属性占据主导地位、数量级的差异将导致迭代收敛速度减慢、依赖于样本距离的算法对于数据的数量级非常敏感。因此需要进行规范化
- 三种规范化方法
