1.Hive概述
(1)数据仓库
Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双
射关系,以方便使用 HQL 去管理查询。
(2)用于数据分析、清洗
Hive 适用于离线的数据分析和清洗,延迟较高。
(3)基于 HDFS、MapReduce
Hive 存储的数据依旧在 DataNode 上,编写的 HQL 语句终将是转换为
MapReduce 代码执行。
2.HBase概述
(1)数据库
是一种面向列存储的非关系型数据库。
(2)用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN 等操作。
(3)基于 HDFS
数据持久化存储的体现形式是 HFile,存放于 DataNode 中,被 ResionServer
以 Region 的形式进行管理。
(4)延迟较低,接入在线业务使用
面对大量的企业数据,HBase 可以直线单表大量数据的存储,同时提供了高
效的数据访问速度。
3. 区别
Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
总的来说:
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
4.关系
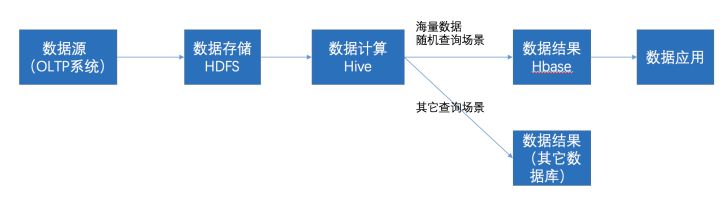
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
总结: 不管 HBase 表是否存在,在 Hive 中都要使用 external 表来与 HBase 表进行关联,如果关联的 HBase 表不存在,Hive 会自动创建 HBase 表。
5.集成使用的好处
HBase 虽然可以存储数亿或数十亿行数据,但是对于数据分析来说,不太友好,只提供了简单的基于 Key 值的快速查询能力,没法进行大量的条件查询。
不过,Hive 与 HBase 的整合可以实现我们的这个目标。不仅如此,还能通过 Hive 将数据批量地导入到 HBase 中。Hive 与 HBase 整合的实现是利用两者本身对外的 API 接口互相通信来完成的,其具体工作交由 Hive 的 lib 目录中的 hive-hbase-handler-xxx.jar 工具类来实现对 HBase 数据的读取。
分布实现HBase 与 Hive 集成使用
(1)在 Hive 中创建表同时关联 HBase
注意: Hive 中只支持 select 和 insert,不支持 HBase 中的版本控制
//在 hive 中创建外部表,指定与hbase某个表作为关联
//hive表名最好与hbase表名一致
create external table customer(
name string, //对应hbase的rowkey
order_numb string, //对应hbase的列簇名order 和列名numb 用_表示:
order_date string, //对应hbase的列簇名order 和列名date 用_表示:
addr_city string, //对应hbase的列簇名addr 和列名city 用_表示:
addr_state string //对应hbase的列簇名addr 和列名state 用_表示:
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties
//hbase中的列簇要和hive数据对应,根据顺序一一对应,不是根据名字
// :key表示hbase中的行键,与hive表第一列对应
// order:numb表示hbase中的列簇和列,与hive表第二列对应
// order:date表示hbase中的列簇和列,与hive表第三列对应
// addr:city表示hbase中的列簇和列,与hive表第四列对应
// addr:state表示hbase中的列簇和列,与hive表第五列对应
("hbase.columns.mapping"=":key,order:numb,order:date,addr:city,addr:state")
//指定hbase中的表作为关联
tblproperties("hbase.table.name" = "Hbase中的表名"); (2)在 HBase 中创建表和列簇
create 'customer','order','addr'(3)向 hive 表中插入数据,在 hive 中执行如下语句。
insert into table customer values ('James','1121','2018-05-31','toronto','ON');
(4)在 HBase Shell 中查看表中的记录。
scan '表名'
(5)在 HBase 中插入数据
put 'customer','3','order:numb','1800'
put 'customer','3','order:date','2018-06-14'
put 'customer','3','addr:city','beijing'
put 'customer','3','addr:state','YES'
(6)在 Hive 表中查看更新的数据。
select * from 表名;建表时的参数:
- hbase.columns.mapping 是必须的,这将会和 HBase 表的列族进行验证。
- hbase.table.name 属性是可选的,默认指定 HBase 表名与 Hive 表名一致。
当将 hive_table 表删除,对应的 hbase_table 表不受影响,里面依旧有数据。当删除 hbase_table 表后,再查询 hive_table 表数据,会报错:
Error: java.io.IOException:
org.apache.hadoop.hbase.TableNotFoundException:
hbase_table (state=,code=0)
注意!注意!注意:
在上述示例中,我们使用的 insert 命令向 Hive 表中插入数据。对于批量数据的插入,还是建议使用 load 命令,但对于 Hive 外部表来说,不支持 load 命令。
可以先创建一个 Hive 内部表,将数据 load 到该表中,最后将查询内部表的所有数据都插入到与 HBase 关联的 Hive 外部表中,就可以了,相当于中转一下。
这样在hbase中新增的数据在hive就就能查看到,也同样在hive中新增的数据在hbase能查看到,就可以集成使用了!
总结:
- 使用 hive-hbase-handler-xxx.jar 包实现 Hive 与 HBase 关联。
- Hive 读取的是 HBase 表最新的数据。
- 通过 Hive 创建的 HBase 表的值默认只有一个 VERSION ,可之后再修改 HBase 表值的最大 VERSION 数。
- Hive 只显示与 HBase 对应的列值,而那些没有对应的 HBase 列在 Hive 表中不显示。
- Hive 表与 HBase 表关联后,数据可以在 Hive 端插入,也可在 HBase 中插入。
- 创建 Hive 外部表与 HBase 的关联,可实现将 Hive 数据导入到 HBase 中。该方式是利用两者本身对外的 API 接口互相通信来完成的,在数据量不大(4T以下)的情况下可以选择该方式导入数据。