朋友们,如需转载请标明出处:http://blog.csdn.net/jiangjunshow
注意力模型
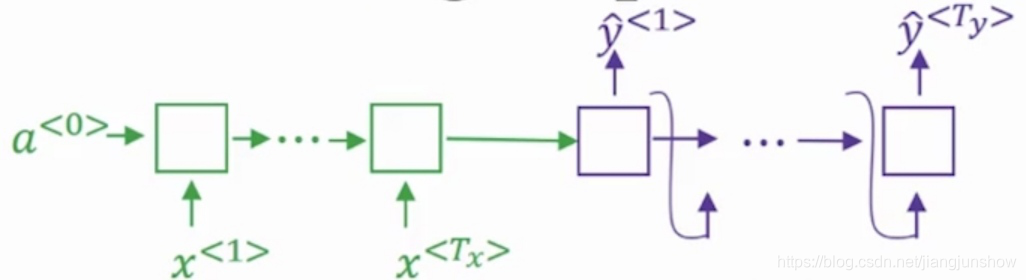
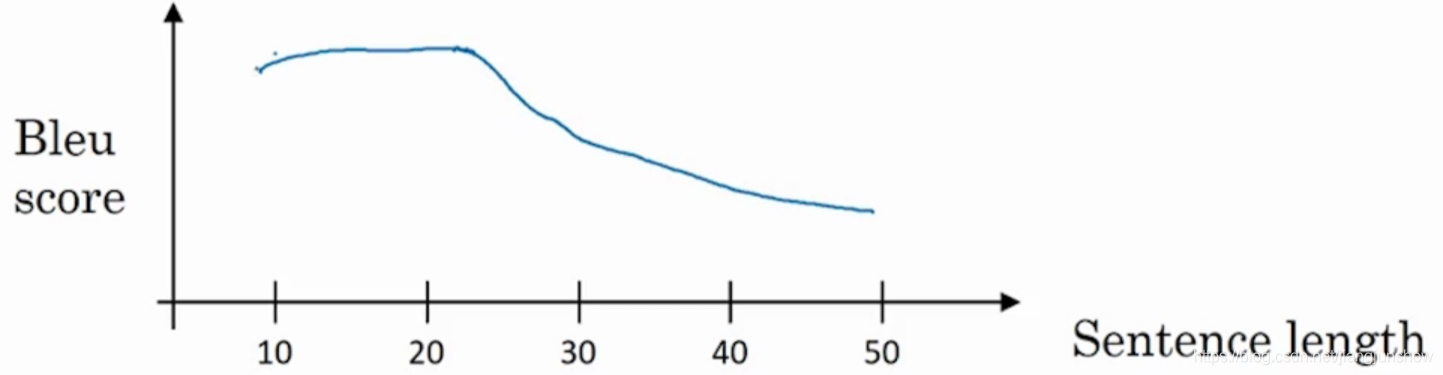
通过对教程中前面一些文章的学习,我们知道可以用上面的神经网络来实现机器翻译。假设要将一段法语句子翻译成英文句子。那么首先要将法语句子中的每一个单词都输入到绿色的编码网络中,然后紫色的解码网络才能开始输出英语单词。如果法语句子比较短,那么效果还是不错的,但是如果法语句子非常长,那么效果就越来越差。大概句子长度超过20个单词,翻译效果就越来越差了。例如下图中反映出了随着句子越来越长,Bleu score就越来越低了。
其实我们人类翻译时并不是读完整个句子后才翻译的。通常我们是读了一部分句子后,就可以翻译出一些内容了。打比方说英语句子“I love you”,当我们读到“I”这个单词时,就可以直接翻译出“我”这个单词了,因为信息已经足够,“I”翻译成“我”肯定没错。但是读到“love”时,不能直接在“我”后面加一个“爱”。因为有可能整个句子是“I love you too”。如果是这种情况,那么在“我”后面接着的应该是“也”字。“我也爱你”。也就是说,我们人类在翻译时,我们的注意力只需要集中在某一部分单词上就可以了。例如对于“我”这个词的翻译,只需要把注意力集中在“I”这个单词上就可以了。下面我们要介绍的注意力模型,就是对文章开头的模型的改良版本,这个改良后的注意力模型在翻译时就会像人类一样只关注部分输入单词。从而对较长的句子也能有很好的翻译效果。
注意力模型的第1个重要部分通常是一个双向的RNN,其实这个部分也就是一个编码网络,用来采集法语句子的特征信息。
然后用另一个RNN来生成英语单词,也就相当于解码网络。
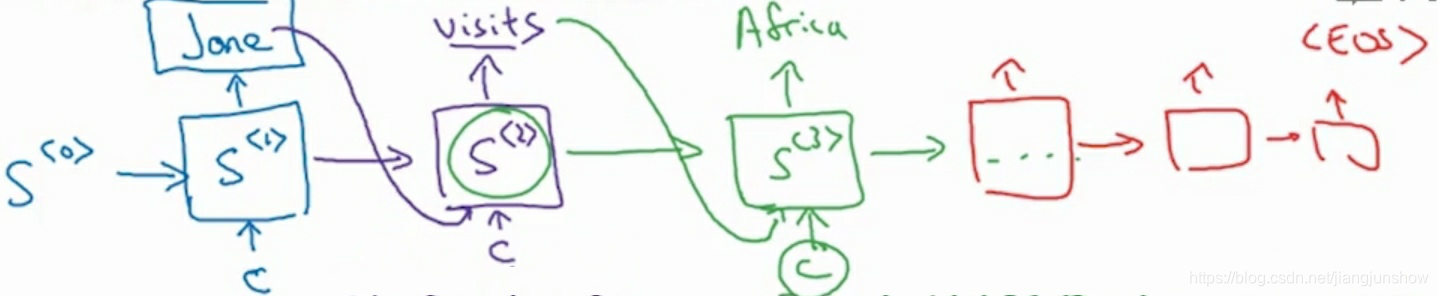
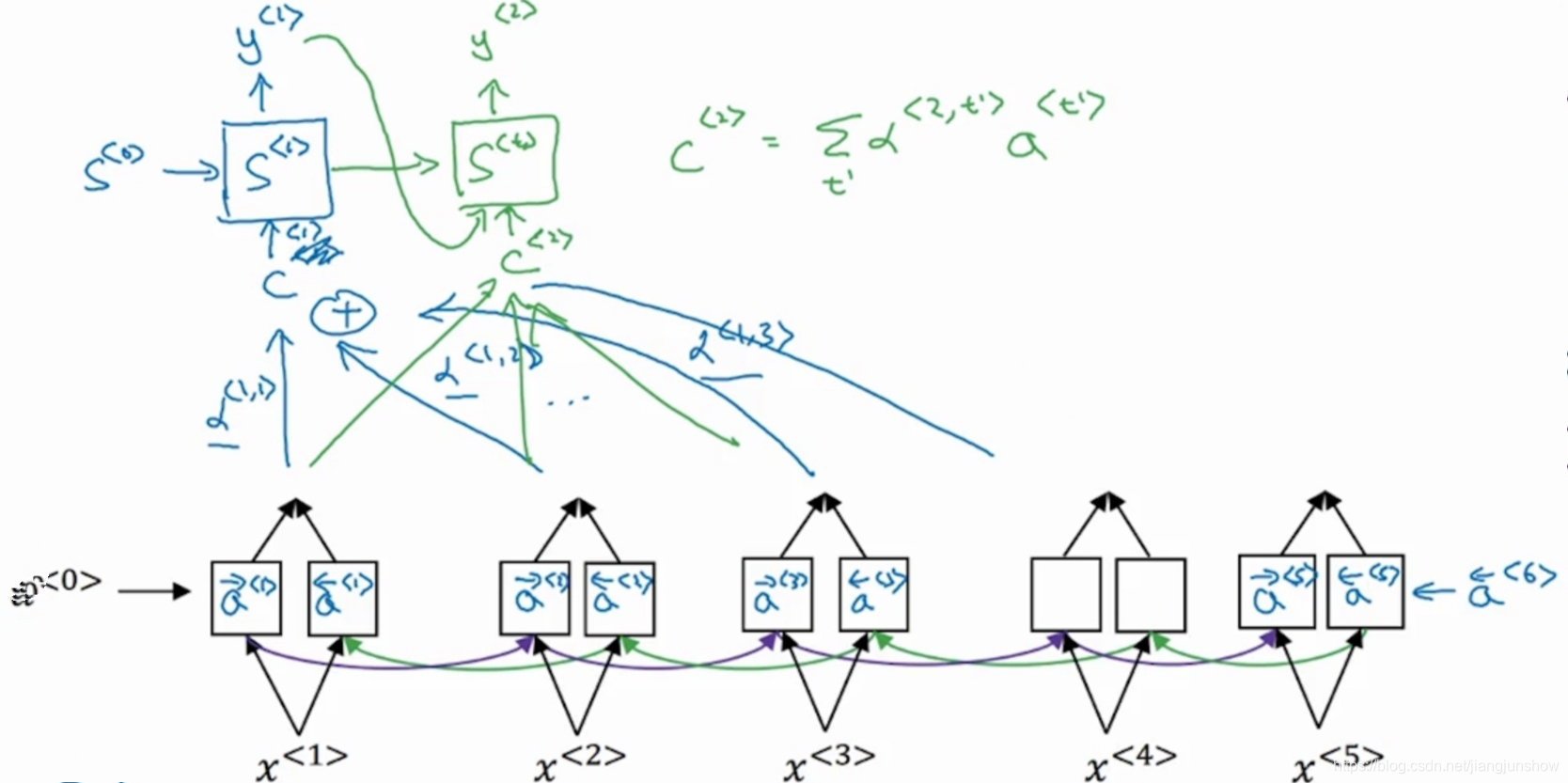
在这个解码网络中,我们使用s来代表激活值,在编码网络中,我们使用a来代表激活值。大家可能注意到了,解码网络中,除了有s作为输入之外,还有另外一个输入c。这个c就来自于编码网络。这个c是基于编码网络中某些时间步的激活值a得来的,就像我们人类在翻译时只需要基于部分法语单词就可以给出相应翻译了。打比方说,为了翻译出第1个单词Jane,有可能基于了前面2个时间步的激活值。
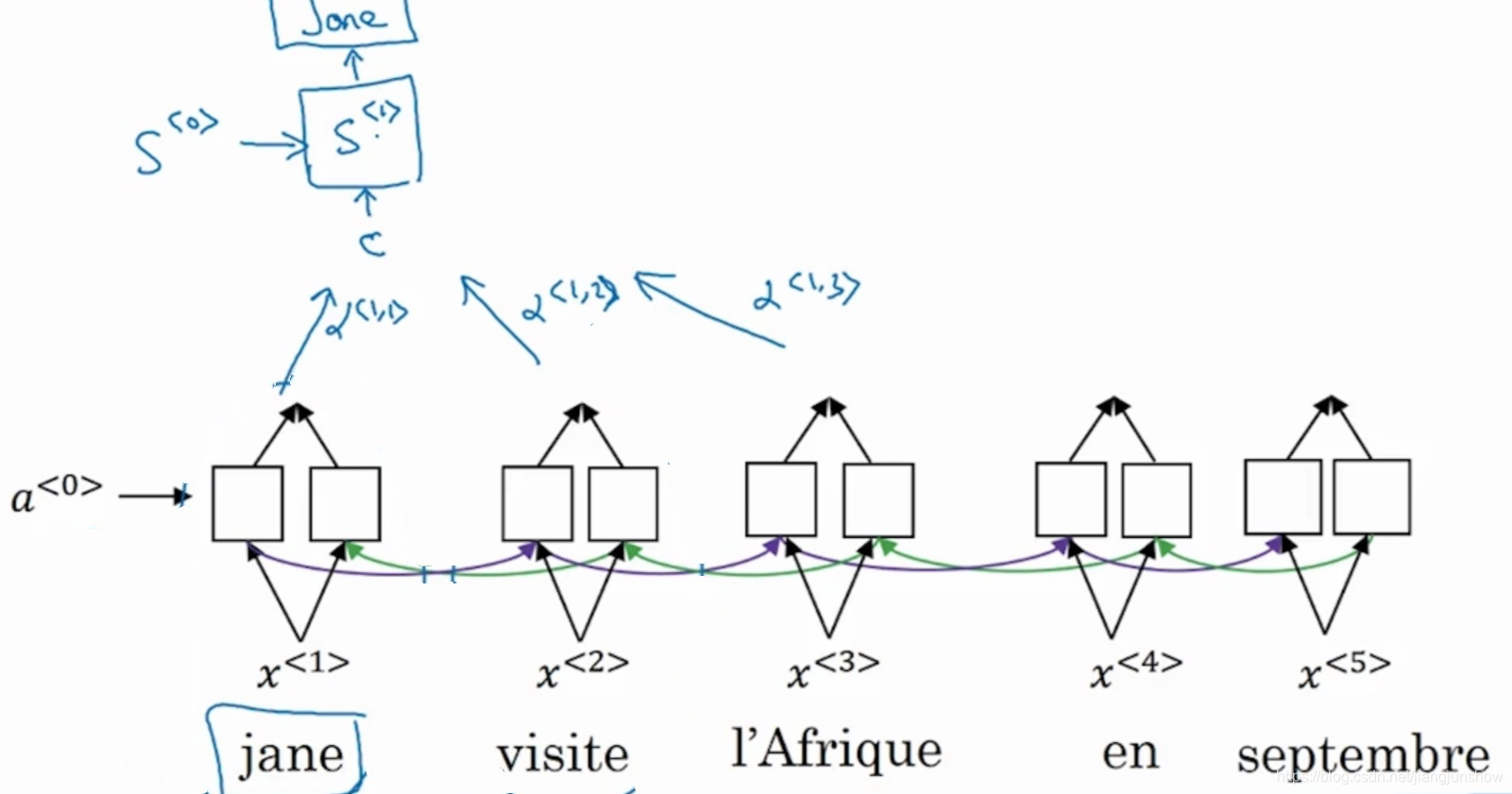
具体基于哪些时间步的激活值,是由一组新的的参数来决定的,也就是图中镜头旁边的α(阿尔法alpha)。这里千万要注意呀,α(alpha)与我们的激活值的英文字母a很相似,但他们是两个不同的东西。而且图中只画出了三个时间步的α参数,但其实每一个时间步都有对应的参数α。这些参数决定了编码网络中各时间步的激活值在组成输入c时的占比,可能有些激活值的占比为0,例如在生成英语单词jane时,可能除了α<1,1>外α<1,2>外其它α参数都为0,因为只需要第1和第2个法语单词就可以确定第1个英语单词是jane了。同理,第2个英语单词可能基于另外一些法语单词。

本篇文章就先说到这里,下一篇文章我们再继续深入学习注意力模型。
注意力模型详述
上篇文章中我们简单地介绍了一下注意力模型,这种模型主要原理是通过一组新的参数α(阿尔法alpha)来决定应该基于编码网络中的哪些时间步的激活值来生成解码网络中的翻译结果。原理与模型的名字很匹配——将注意力集中在编码网络的某些时间步上,将注意力集中在输入句子的某些单词上。本篇文章我们继续学习注意力模型的一些细节。
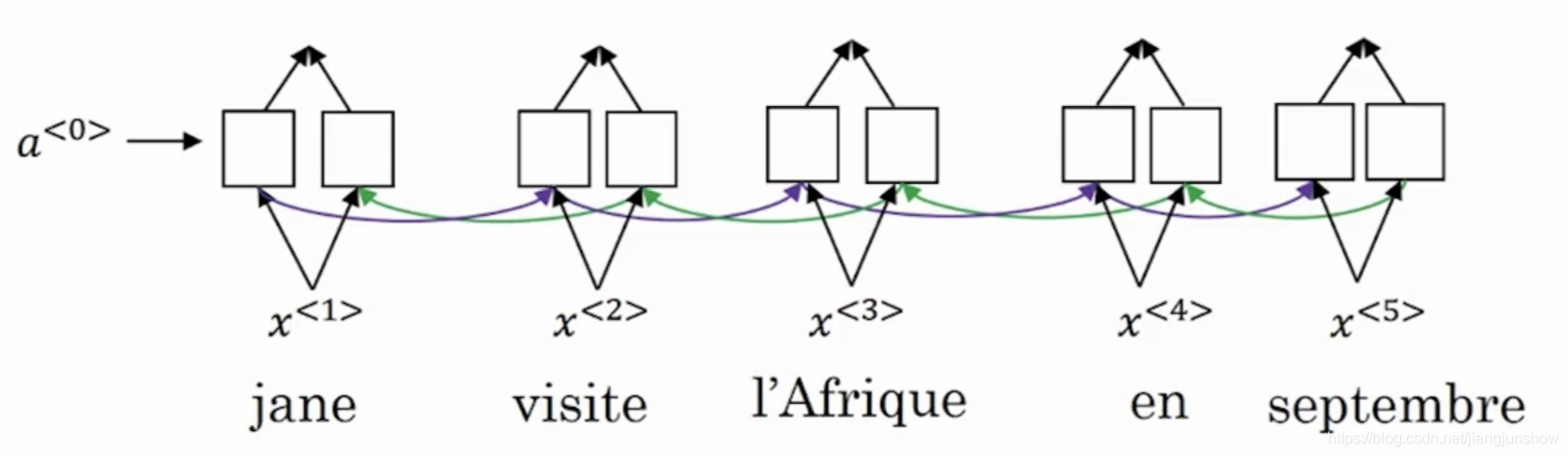
编码网络通常使用双向GRU或双向LSTM(后者用得更多些)。因为是双向的,所以每一个时间步都有两个激活值。如下图所示,每一个时间步都有两个激活值,一个是往右传播时计算得出的,一个是往左传播时计算得出的。
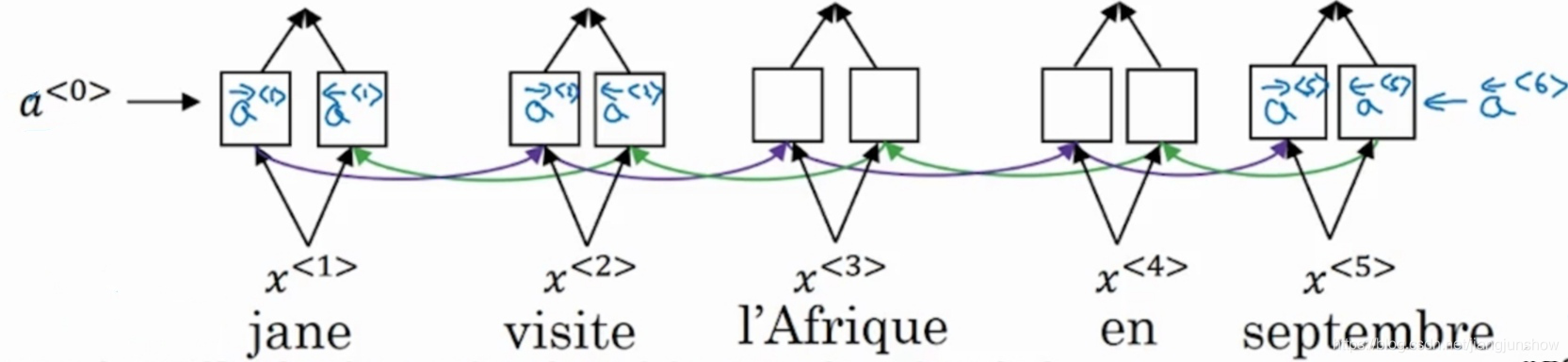
在本文中我们会用t'来表示编码网络中时间步编号,而且为了简单起见我们用一个激活值符号来表示往右传播的激活值和往左传播的激活值。如下图所示。
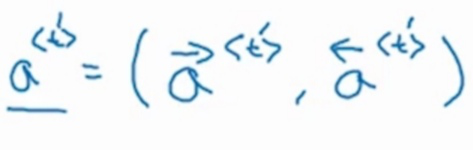
下图展示了计算y<1>时的过程,也就是生成第一个翻译单词的过程。

图中解码网络的第一个时间步的输入c是基于参数α和编码网络每个时间步的激活值a生成的。公式如下
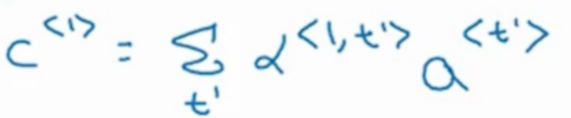
另外这个公式中的所有α参数相加起来必须等于1,也就是说要满足下面的公式。
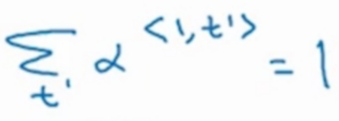
从上面的两个公式也可以看出,参数α决定了编码网络中某个时间步是否起作用,例如,如果第3个时间步关联的参数α<1,3>为0的话,那么参数α<1,3>与激活值a<3>的乘积就为0,也就是说,在生成c<1>时会忽略掉激活值a<3>。
同理,生成第二个单词时如下图中的绿色部分所示
如何设置注意力权重
我们知道注意力模型的主要原理是通过一组新的参数α(阿尔法alpha)来决定应该基于编码网络中的哪些时间步的激活值来生成解码网络中的翻译结果。从上面这句话中就可以看出这组参数非常重要。因为他们决定了应该把注意力集中在哪里。这组参数可以叫做注意力权重。
那么这组参数的值是如何设置的呢?其实严格来说这些值不是人为设置的,而是由神经网络设置的。下面我就一步一步地给大家解释如何通过神经网络设置注意力权重。
注意力权重α(阿尔法alpha)的值可以由下面这个公式计算得来,这个公式确保了某一组注意力权重的值累加起来等于1。因为注意力权重的目的是要表明把注意力分配在编码网络中的哪些位置上,所以这些配额累加起来肯定是要等于1的。例如第1个时间步的值为0.6,说明占了60%,其余的时间步只有另外40%可以分配了。

公式中的t'上一篇文章我们已经说到了,它表示编码网络中时间步的编号,例如第1个时间步,第2个时间步,第3个时间步等等等。而t则表示解码网络中时间步的编号。公式中的e是由另外一个小型神经网络学习而来的,如下图所示。
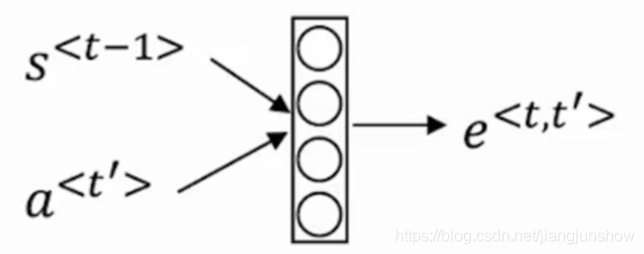
从图中可以得知这个小型神经网络的输入是解码网络前一个时间步的激活值s以及编码网络中本时间步的激活值a。这里千万要注意呀,图中的是激活值a而不是注意力权重α。
也就是说这个e不是人为设置的值,而是由上面这种小型的神经网络学习而来的。感觉是不是很奇妙?在一个大型的神经网络中,还可以利用一个小型的神经网络来设置参数值。因为人为根本无法知道应该设置什么值,所以干脆用另外一个神经网络通过梯度下降来学习这些值。
这种通过另一个神经网络来学习参数的方法的一个缺点就是计算量很大,但是通常来说,机器翻译中输入句子的长度都不是特别长,所以计算量还是可以接受。当然也有很多研究人员在想办法减少计算量。