这是我见过的最容易出错的一道Java笔试题,如果不是对Set有非常深入的理解,百分百会出错。
下面就来看一下,这道题到底坑在哪里。
题目如下:
定义了一个Person类,重写了hashCode和equals方法,如下图所示:
public class Person {
public int id;
public String name;
public Person(int id, String name) {
this.id = id;
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
if (id != person.id) return false;
return name != null ? name.equals(person.name) : person.name == null;
}
@Override
public int hashCode() {
int result = id;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
@Override
public String toString() {
return "Person{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}
请写出下面一段代码的运行结果
public class Test {
public static void main(String[] args) {
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set);
}
}
此时的运行结果是怎样的呢?可以先自己猜一下,然后在看运行结果。
此时的输出结果如下所示:
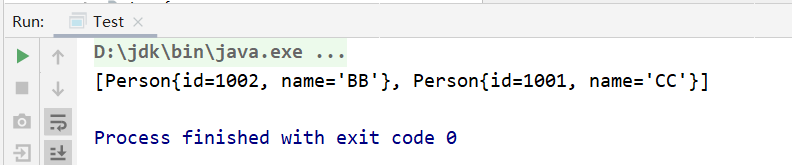
为什么是这样的运行结果呢?
因为存储p1时,是按照p1的哈希值计算的索引位置,之后p1.name进行了修改,那么当删除p1时,会按照现在的p1,也就是name修改后的p1的哈希值计算的索引,此时计算出的索引位置与之前存储p1的索引位置不相同,所以不会把p1删除掉。
那么接着往下看,还有更坑的。
public class Test {
public static void main(String[] args) {
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set);
set.add(new Person(1001,"CC"));
Sys,,idtem.out.println(set);
}
}
此时的运行结果又是怎样的呢?Person(1001,“CC”)能存储成功吗?可以先自己猜一下,在看运行结果。
此时的运行结果如下所示:

那么为什么是这样的运行结果呢?
因为存储p1时,是按照第一次的哈希值计算的索引位置,也就是按照p1=new Person(1001,“AA”)计算出来的索引位置进行的存储。后来又把name值进行了修改,那么此时p1的id=1001,name=“CC”。当又往Set中添加id=1001,name="CC"的Person时,会按照Person(1001,“CC”)的哈希值计算索引位置,此时计算出的索引位置与之前存储p1时id=1001,name="AA"计算的索引位置不一样,所以可以添加成功。
别急,还有更坑的,接着往下看。

public class Test {
public static void main(String[] args) {
HashSet set = new HashSet();
Person p1 = new Person(1001,"AA");
Person p2 = new Person(1002,"BB");
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set);
set.add(new Person(1001,"CC"));
System.out.println(set);
set.add(new Person(1001,"AA"));
System.out.println(set);
}
}
此时的运行结果又是怎样的呢?当Person(1001,“AA”)再次存储时,到底能不能存储成功呢?
此时的运行结果如下所示:

那么为什么是这样的运行结果呢?
因为当再次存储id=1001,name="AA"的Person时,虽然使用哈希值计算出的索引位置相同,但是因为此时p1的name值为CC,当调用equals方法判断两者是否相等时,会返回false,所以可以存储成功。
注意:Set集合是元素无序、不可重复的集合,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
向HashSet中添加元素的过程:
当向HashSet集合中存入一个元素时,HashSet会先计算出该元素的哈希值,然后把哈希值与数组长度-1进行与运算计算出该元素在HashSet底层数组中的存储位置。然后判断该位置上是否已经存在元素,如果不存在则直接存储成功;如果该位置上已经存在一个或多个元素,那么就会从前往后依次比较元素是否相等。比较时会先比较元素的哈希值,如果哈希值不相同则添加成功。如果哈希值相同则会调用元素所在类的equals方法进行比较;如果equals方法返回true,则表示两者相等,添加失败;如果equals方法返回false,则表示两者不相等,会添加成功。
如果对你有帮助,记得点赞关注。
关注我,带你学习更多更有用的干货。