目录
ConcurrentHashMap的存储结构
ConcurrentHashMap是一个存储key/value对的容器,并且是线程安全的。它的存储结构和HashMap类似,都是数组加链表的形式,并且在链表长度到达阈值(阈值为8)后自动转化为红黑树,加快查找速度。
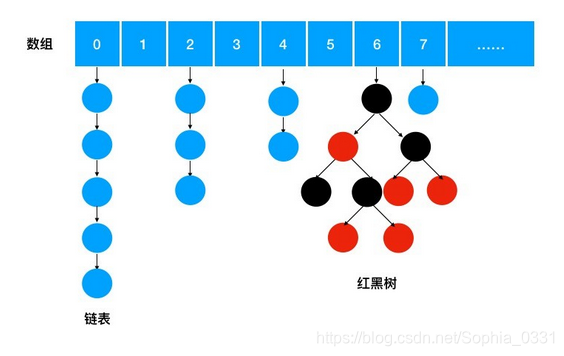
存储和取值原理
ConcurrentHashMap的存储结构我们已经知道了,那每一个key是以怎样的方式存入到这个容器中的呢?
key存入容器的逻辑分三步:
1、通过key的hashCode()方法获取其hashCode值。
2、将hashCode值映射到数组的某个位置上。
3、把该元素存储到该位置的链表中。
从容器取数的逻辑分三步:
1、通过key的hashCode()方法获取其hashCode值
2、将hashCode映射到数组的某个位置上
3、遍历该位置的链表或者从红黑树中找到匹配的对象返回
其中把对象key映射到数组的某个位置的函数,叫做hash函数。我们知道,在数组中随机查找一个元素的时间复杂度是O(1),在链表中查找一个元素的时间复杂度是O(n), hash 函数的好坏决定了元素在哈希表中分布是否均匀,如果元素都堆积在一个位置上,那么在取值时需要遍历很长的链表,那时间复杂度就是遍历一个链表的时间复杂度O(n)。但元素如果是均匀的分布在数组中,那么链表就会比较短,通过哈希函数定位位置后,能够快速找到对应的元素,这样时间复杂度会趋于O(1)。
扩容
当数组中保存的链表越来越多,那么再存储进来的元素大概率会插入到链表中,而不是使用数组中剩下的空位,这样就会造成数组中保存的链表越来越长,从而导致哈希表的查找效率下降,从O(1)慢慢趋近于链表的时间复杂度O(n)。所以ConcurrentHashMap这时会做扩容来解决这个问题,即把数组长度变长,增加更多的空位出来。
ConcurrentHashMap 会在数组中75%的位置被使用时,进行扩容操作。
ConcurrentHashMap 的重要属性
transient volatile Node<K,V>[] table
//这个 Node 数组就是 ConcurrentHashMap 用来存储数据的哈希表
private static final int DEFAULT_CAPACITY = 16;
//默认的初始化哈希表数组大小为16
static final int TREEIFY_THRESHOLD = 8
//转化为红黑树的链表长度阈值
static final int MOVED = -1
//这个标识位用于识别扩容时正在转移数据
static final int HASH_BITS = 0x7fffffff;
//计算哈希值时用到的参数,用来去除符号位
private transient volatile Node<K,V>[] nextTable;
//数据转移时,新的哈希表数组
源码解析
put 方法源码
put用来将一个键值对存储到Map中。
put方法中直接调用了putVal方法,第三个参数传入false,控制key存在时覆盖原来的值。
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
//key和value不能为空
if (key == null || value == null) throw new NullPointerException();
//计算key的hash值,后面我们会看spread方法的实现
int hash = spread(key.hashCode());
int binCount = 0;
//开始自旋,table属性采取懒加载,第一次put的时候进行初始化
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果table未被初始化,则初始化table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//通过key的hash值映射table位置,如果该位置的值为空,那么生成新的node来存储该key、value,放入此位置
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果该位置节点元素的hash值为MOVED,也就是-1,代表正在做扩容的复制。那么该线程参与复制工作。
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
//下面分支处理table映射的位置已经存在node的情况
else {
V oldVal = null;
synchronized (f) {
//再次确认该位置的值是否已经发生了变化
if (tabAt(tab, i) == f) {
//fh大于0,表示该位置存储的还是链表
if (fh >= 0) {
binCount = 1;
//遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
//如果存在一样hash值的node,那么根据onlyIfAbsent的值选择覆盖value或者不覆盖
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
//如果找到最后一个元素,也没有找到相同hash的node,那么生成新的node存储key/value,作为尾节点放入链表。
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//下面的逻辑处理链表已经转为红黑树时的key/value保存
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
//node保存完成后,判断链表长度是否已经超出阈值,则进行哈希表扩容或者将链表转化为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//计数,并且判断哈希表中使用的桶位是否超出阈值,超出的话进行扩容
addCount(1L, binCount);
return null;
}
spread方法源码解析
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
传入的参数h为key对象的hashCode,spreed方法对hashCode进行了加工。重新计算出hash。
hash值是用来映射该key值在哈希表中的位置。取出哈希表中该hash值对应位置的代码如下:
tabAt(tab,i=(n-1)&hash);
第一个参数是哈希表,第二个参数是哈希表中的数组下标。通过(n-1)&hash计算下标。n为数组长度,以数组默认大小16举例说明计算过程,那么n-1=15,假设hash值为100,那么15&100为多少?
先将15和100用二进制数表示,在java中int类型为8个字节,一共32个bit位,所以:
n 的值 15 转为二进制:
0000 0000 0000 0000 0000 0000 0000 1111
hash 的值 100 转为二进制:
0000 0000 0000 0000 0000 0000 0110 0100。
计算结果:
0000 0000 0000 0000 0000 0000 0000 0100
对应的十进制值为 4
通过计算结果我们可以看出,经过&运算(1&1=1,1&0=0,0&0=0)后,hash值100的高位全部被清零,地位则保持不变,并且一定是小于(n-1)的。即经过计算后,通过hash值得的数组下标绝对不会越界。
面试高频问题
1、数组大小可以为17,或者18吗
2、如果为了保证不越界为什么不直接用%计算取余数?
3、为什么不直接用key的hashCode,而是使用经spreed方法加工后的hash值?
(1)数组大小必须是2的n次方
数组大小必须是2的n次方,也就是16,32,64…,不能为其他值。因为如果不是2的n次方,那么经过计算的数组下标会增大碰撞的几率。
例如数组长度为 21,那么 n-1=20,对应的二进制为:10100
那么 hash 值的二进制如果是 10000(十进制 16)、10010(十进制 18)、10001(十进制 17),和 10100 做 & 计算后,都是 10000,也就是都被映射到数组 16 这个下标上。这三个值会以链表的形式存储在数组 16 下标的位置。这显然不是我们想要的结果。
但如果数组长度 n 为 2 的 n 次方,2 进制的数值为 10,100,1000,10000……n-1 后对应二进制为 1,11,111,1111…… 这样和 hash 值低位 & 后,会保留原来 hash 值的低位数值,那么只要 hash 值的低位不一样,就不会发生碰撞。
(2)为什么不直接用 hash% n 呢?
其实如果数组长度为 2 的 n 次方,那么 (n - 1) & hash 等价于 hash% n。那么为什么不直接用 hash% n 呢?这是因为按位的操作效率会更高,经过我本地测试,& 计算速度大概是 % 操作的 50 倍左右。
所以 JDK 为了性能,而使用这种巧妙的算法,在确保元素均匀分布的同时,还保证了效率。
(3)为什么不直接用key的hashCode?
不直接用key的hashCode,目的还是为了减少碰撞的概率。
分析spreed方法中都做了哪些事情:
1、(h ^ (h >>> 16))
h >>> 16 的意思是把 h 的二进制数值向右移动 16 位。我们知道整型为 32 位,那么右移 16 位后,就是把高 16 位移到了低 16 位。而高 16 位清 0 了。
^ 为异或操作,二进制按位比较,如果相同则为 0,不同则为 1。这行代码的意思就是把高低 16 位做异或。如果两个 hashCode 值的低 16 位相同,但是高位不同,经过如此计算,低 16 位会变得不一样了。为什么要把低位变得不一样呢?这是由于哈希表数组长度 n 会是偏小的数值,那么进行 (n - 1) & hash 运算时,一直使用的是 hash 较低位的值。那么即使 hash 值不同,但如果低位相当,也会发生碰撞。而进行 h ^ (h >>> 16) 加工后的 hash 值,让 hashCode 高位的值也参与了哈希运算,因此减少了碰撞的概率。
2、(h ^ (h >>> 16)) & HASH_BITS
高位移到低位和原来低位做异或操作后,还需要和 HASH_BITS 这个常量做 & 计算。HASH_BITS 这个常量的值为 0x7fffffff,转化为二进制为 0111 1111 1111 1111 1111 1111 1111 1111。这个操作后会把最高位转为 0,其实就是消除了符号位,得到的都是正数。这是因为负的 hashCode 在 ConcurrentHashMap 中有特殊的含义,因此我们需要得到一个正的 hashCode。
小结
关于ConcurrentHashMap我们要掌握以下几个重点:
1、ConcurrentHashMap采用数组+链表+红黑树的存储结构,并且是线程安全的
2、存入的key通过自己的hashCode映射到数组的相应位置
3、ConcurrentHashMap 为保障查询效率,会在数组中75%的位置被占用时,进行扩容
4、当链表长度增加到阈值8时,触发链表转红黑树。
5、为了减小hash值碰撞的几率,ConCurrentHashMap的大小必须为2的n次方。