1 简单介绍一下ssm吧?
SSM框架,是Spring + Spring MVC + MyBatis的缩写,目前主流的Java EE企业级框架,适用于搭建各种大型的企业级应用系统。使用ssm框架的好处是在于其易复用和简化开发,掌握了每个框架的核心思想。
Spring的核心思想是IoC(控制反转),即不再需要程序员去显式地new一个对象,而是让Spring框架帮你来完成这一切。
Spring MVC 分离了控制器、模型对象、分派器以及处理程序对象的角色,这种分离让它们更容易进行定制。
mybatis是对jdbc的封装,MyBatis 消除了几乎所有的JDBC代码和参数的手工设置以及结果集的检索。MyBatis 使用简单的 XML或注解用于配置和原始映射,将接口和 Java 的POJOs(普通的 Java对象)映射成数据库中的记录。
----------------------------------------------------------------------------------------------------------------------------------------------------
2 你有了解过spring的版本吗?3,4,5的区别是什么?

第5版比第4版改动相当大。
第5版只有466页,比第四版的576页少了110页。总体来看,第五版删除了基础讲解和不常用的模块,添加了spring cloud、响应式编程,更加注重实用性。
另外,第五版的demo都是基于springboot的,这点很不错。
不过spring功能太多了,所以该书只是简单介绍,比如springcloud只介绍了其主要功能。
只是觉得IOC、AOP、redis、nosql、websocket删除得有点可惜,这三部分还是蛮有用的,特别是redis。
还是学习Spring 4吧,太新的东西网上找解答会比较少,而新学老的,又享受不到新的功能。所以Spring 4比较合适
现在都已5了吧,除非你们的框架及新技术敏感度不高,或者系统的并发量不太高,
不然5里边的挺多新功能挺舍得一看的。可以看看这个系列。学习Spring4,目前2018年主流还是在使用Spring4
简单一点回答:第四版侧重于Spring框架本身的知识,
第五版完全基于Spring Boot 和 Spring Cloud 。第四版打基础,第五版跟新技术。
3 你说的xml配置的话,spring5搭建ssm还有在用吗?
1、概述:
对于 Spring 和 SpringBoot 到底有什么区别,我听到了很多答案,刚开始迈入学习 SpringBoot 的我当时也是一头雾水,随着经验的积累、我慢慢理解了这两个框架到底有什么区别,我相信对于用了 SpringBoot 很久的开发人员来说,有绝大部分还不是很理解 SpringBoot 到底和 Spring 有什么区别,看完文章中的比较,或许你有了不同的答案和看法!
2、什么是Spring呢?
先来聊一聊 Spring 作为 Java 开发人员,大家都 Spring 可不陌生,简而言之, Spring 框架为开发 Java 应用程序提供了全面的基础架构支持。它包含一些很好的功能,如依赖注入和开箱即用的模块,如:
Spring JDBC 、Spring MVC 、Spring Security、 Spring AOP 、Spring ORM 、Spring Test
这些模块大家应该都用过吧,这些模块缩短应用程序的开发时间,提高了应用开发的效率
例如,在 Java Web 开发的早期阶段,我们需要编写大量的代码来将记录插入到数据源中。但是通过使用 Spring JDBC 模块的 JDBCTemplate ,我们可以将这操作简化为只需配置几行代码。
3、什么是Spring Boot呢?
Spring Boot 基本上是 Spring 框架的扩展,它消除了设置 Spring 应用程序所需的 XML配置,为更快,更高效的开发生态系统铺平了道路。
以下是 Spring Boot 中的一些特点:
1:创建独立的 spring 应用。
2:嵌入 Tomcat , Jetty Undertow 而且不需要部署他们。
3:提供的“starters” poms来简化 Maven 配置
4:尽可能自动配置 spring 应用。
5:提供生产指标,健壮检查和外部化配置
6:绝对没有代码生成和 XML 配置要求
4、让我们逐步熟悉这两个框架
4.1、 Maven依赖
首先,让我们看一下使用Spring创建Web应用程序所需的最小依赖项
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>5.1.0.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>5.1.0.RELEASE</version>
</dependency>
与Spring不同,Spring Boot只需要一个依赖项来启动和运行Web应用程序:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.0.6.RELEASE</version>
</dependency>
在进行构建期间,所有其他依赖项将自动添加到项目中。
另一个很好的例子就是测试库。我们通常使用 Spring Test , JUnit , Hamcrest 和 Mockito 库。在 Spring 项目中,我们应该将所有这些库添加为依赖项。但是在 Spring Boot中 ,我们只需要添加 spring-boot-starter-test 依赖项来自动包含这些库。
Spring Boot为不同的Spring模块提供了许多依赖项。一些最常用的是:
spring-boot-starter-data-jpa
spring-boot-starter-security
spring-boot-starter-test
spring-boot-starter-web
spring-boot-starter-thymeleaf
4.2、MVC配置
让我们来看一下 Spring 和 Spring Boot 创建 JSP Web 应用程序所需的配置。
Spring 需要定义调度程序 servlet ,映射和其他支持配置。我们可以使用 web.xml 文件或 Initializer 类来完成此操作:
public class MyWebAppInitializer implements WebApplicationInitializer {
@Override
public void onStartup(ServletContext container) {
AnnotationConfigWebApplicationContext context = new AnnotationConfigWebApplicationContext();
context.setConfigLocation("com.pingfangushi");
container.addListener(new ContextLoaderListener(context));
ServletRegistration.Dynamic dispatcher = container
.addServlet("dispatcher", new DispatcherServlet(context));
dispatcher.setLoadOnStartup(1);
dispatcher.addMapping("/");
}
}
还需要将 @EnableWebMvc 注释添加到 @Configuration 类,并定义一个视图解析器来解析从控制器返回的视图:
@EnableWebMvc
@Configuration
public class ClientWebConfig implements WebMvcConfigurer {
@Bean
public ViewResolver viewResolver() {
InternalResourceViewResolver bean
= new InternalResourceViewResolver();
bean.setViewClass(JstlView.class);
bean.setPrefix("/WEB-INF/view/");
bean.setSuffix(".jsp");
return bean;
}
}
和上述操作一比,一旦我们添加了 Web 启动程序, Spring Boot 只需要在 application 配置文件中配置几个属性来完成如上操作:
spring.mvc.view.prefix=/WEB-INF/jsp/
spring.mvc.view.suffix=.jsp
上面的所有Spring配置都是通过一个名为auto-configuration的过程添加 Boot web starter 来自动包含的。
这意味着 Spring Boot 将查看应用程序中存在的依赖项,属性和 bean ,并根据这些依赖项,对属性和 bean 进行配置。当然,如果我们想要添加自己的自定义配置,那么 Spring Boot 自动配置将会退回。
4.3、配置模板引擎
现在我们来看下如何在Spring和Spring Boot中配置Thymeleaf模板引擎。
在 Spring 中,我们需要为视图解析器添加 thymeleaf-spring5 依赖项和一些配置:
@Configuration
@EnableWebMvc
public class MvcWebConfig implements WebMvcConfigurer {
@Autowired
private ApplicationContext applicationContext;
@Bean
public SpringResourceTemplateResolver templateResolver() {
SpringResourceTemplateResolver templateResolver = new SpringResourceTemplateResolver();
templateResolver.setApplicationContext(applicationContext);
templateResolver.setPrefix("/WEB-INF/views/");
templateResolver.setSuffix(".html");
return templateResolver;
}
@Bean
public SpringTemplateEngine templateEngine() {
SpringTemplateEngine templateEngine = new SpringTemplateEngine();
templateEngine.setTemplateResolver(templateResolver());
templateEngine.setEnableSpringELCompiler(true);
return templateEngine;
}
@Override
public void configureViewResolvers(ViewResolverRegistry registry) {
ThymeleafViewResolver resolver = new ThymeleafViewResolver();
resolver.setTemplateEngine(templateEngine());
registry.viewResolver(resolver);
}
}
SpringBoot1X 只需要 spring-boot-starter-thymeleaf 的依赖 项 来启用 Web 应用程序中的 Thymeleaf 支持。但是由于 Thymeleaf3.0 中的新功能, 我们必须将 thymeleaf-layout-dialect 添加 为 SpringBoot2X Web应用程序中的依赖项。一旦依赖关系到位,我们就可以将模板添加到 src/main/resources/templates 文件夹中, SpringBoot 将自动显示它们。
4.4、Spring Security 配置
为简单起见,我们使用框架默认的 HTTP Basic 身份验证。让我们首先看一下使用 Spring 启用Security 所需的依赖关系和配置。
Spring 首先需要依赖 spring-security-web 和 spring-security-config 模块。接下来, 我们需要添加一个扩展 WebSecurityConfigurerAdapter 的类,并使用 @EnableWebSecurity 注解:
@Configuration
@EnableWebSecurity
public class CustomWebSecurityConfigurerAdapter extends WebSecurityConfigurerAdapter {
@Autowired
public void configureGlobal(AuthenticationManagerBuilder auth) throws Exception {
auth.inMemoryAuthentication()
.withUser("admin")
.password(passwordEncoder()
.encode("password"))
.authorities("ROLE_ADMIN");
}
@Override
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests()
.anyRequest().authenticated()
.and()
.httpBasic();
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
}
这里我们使用 inMemoryAuthentication 来设置身份验证。同样, Spring Boot 也需要这些依赖项才能使其工作。但是我们只需要定义 spring-boot-starter-security 的依赖关系,因为这会自动将所有相关的依赖项添加到类路径中。
Spring Boot 中的安全配置与上面的相同。
5、应用程序引导配置
Spring 和 Spring Boot 中应用程序引导的基本区别在于 servlet 。
Spring 使用 web.xml 或 SpringServletContainerInitializer 作为其引导入口点。
Spring Boot 仅使用 Servlet 3 功能来引导应用程序,下面让我们详细来了解下
5.1、Spring 是怎样引导配置的呢?
Spring 支持传统的 web.xml 引导方式以及最新的 Servlet 3+ 方法。
让我们看一下 web.xml 方法的步骤:
Servlet 容器(服务器)读取 web.xml
web.xml 中定义的 DispatcherServlet 由容器实例化
DispatcherServlet 通过读取 WEB-INF / {servletName} -servlet.xml 来创建 WebApplicationContext
最后, DispatcherServlet 注册在应用程序上下文中定义的 bean
以下是使用 Servlet 3+ 方法的 Spring 引导:
容器搜索实现 ServletContainerInitializer 的类并执行
SpringServletContainerInitializer 找到实现所有类 WebApplicationInitializer
WebApplicationInitializer 创建具有XML或上下文 @Configuration 类
WebApplicationInitializer 创建 DispatcherServlet 的 与先前创建的上下文。
5.2、SpringBoot 有是如何配置的呢?
Spring Boot应用程序的入口点是使用@SpringBootApplication注释的类:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
默认情况下, Spring Boot 使用嵌入式容器来运行应用程序。在这种情况下, Spring Boot 使用 public static void main 入口点来启动嵌入式 Web 服务器。此外,它还负责将 Servlet ,Filter 和 ServletContextInitializer bean 从应用程序上下文绑定到嵌入式 servlet 容器。
Spring Boot 的另一个特性是它会自动扫描同一个包中的所有类或 Main 类的子包中的组件。
Spring Boot 提供了将其部署到外部容器的方式。在这种情况下,我们必须扩展 SpringBootServletInitializer :
/**
* War部署
*
* @author SanLi
* Created by [email protected] on 2018/4/15
*/
public class ServletInitializer extends SpringBootServletInitializer {
@Override
protected SpringApplicationBuilder configure(SpringApplicationBuilder application) {
return application.sources(Application.class);
}
@Override
public void onStartup(ServletContext servletContext) throws ServletException {
super.onStartup(servletContext);
servletContext.addListener(new HttpSessionEventPublisher());
}
}
这里外部 servlet 容器查找在war包下的 META-INF 文件夹下MANIFEST.MF文件中定义的 Main-class , SpringBootServletInitializer 将负责绑定 Servlet , Filter 和 ServletContextInitializer 。
6、打包和部署
最后,让我们看看如何打包和部署应用程序。这两个框架都支持 Maven 和 Gradle 等通用包管理技术。但是在部署方面,这些框架差异很大。例如,Spring Boot Maven插件在 Maven 中提供Spring Boot 支持。它还允许打包可执行 jar 或 war 包并 就地 运行应用程序。
在部署环境中 Spring Boot 对比 Spring 的一些优点包括:
提供嵌入式容器支持
使用命令 java -jar 独立运行jar
在外部容器中部署时,可以选择排除依赖关系以避免潜在的jar冲突
部署时灵活指定配置文件的选项
用于集成测试的随机端口生成
7、结论
简而言之,我们可以说 Spring Boot 只是 Spring 本身的扩展,使开发,测试和部署更加方便。
Spring Bean的生命周期是Spring面试热点问题。这个问题即考察对Spring的微观了解,又考察对Spring的宏观认识,想要答好并不容易!本文希望能够从源码角度入手,帮助面试者彻底搞定Spring Bean的生命周期。
只有四个!
是的,Spring Bean的生命周期只有这四个阶段。把这四个阶段和每个阶段对应的扩展点糅合在一起虽然没有问题,但是这样非常凌乱,难以记忆。要彻底搞清楚Spring的生命周期,首先要把这四个阶段牢牢记住。实例化和属性赋值对应构造方法和setter方法的注入,初始化和销毁是用户能自定义扩展的两个阶段。在这四步之间穿插的各种扩展点,稍后会讲。
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
实例化 -> 属性赋值 -> 初始化 -> 销毁
主要逻辑都在doCreate()方法中,逻辑很清晰,就是顺序调用以下三个方法,这三个方法与三个生命周期阶段一一对应,非常重要,在后续扩展接口分析中也会涉及。
- createBeanInstance() -> 实例化
- populateBean() -> 属性赋值
- initializeBean() -> 初始化
源码如下,能证明实例化,属性赋值和初始化这三个生命周期的存在。关于本文的Spring源码都将忽略无关部分,便于理解:
// 忽略了无关代码
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final 至于销毁,是在容器关闭时调用的,详见ConfigurableApplicationContext#close()
常用扩展点
Spring生命周期相关的常用扩展点非常多,所以问题不是不知道,而是记不住或者记不牢。其实记不住的根本原因还是不够了解,这里通过源码+分类的方式帮大家记忆。
第一大类:影响多个Bean的接口
实现了这些接口的Bean会切入到多个Bean的生命周期中。正因为如此,这些接口的功能非常强大,Spring内部扩展也经常使用这些接口,例如自动注入以及AOP的实现都和他们有关。
- BeanPostProcessor
- InstantiationAwareBeanPostProcessor
这两兄弟可能是Spring扩展中最重要的两个接口!InstantiationAwareBeanPostProcessor作用于实例化阶段的前后,BeanPostProcessor作用于初始化阶段的前后。正好和第一、第三个生命周期阶段对应。通过图能更好理解:

InstantiationAwareBeanPostProcessor实际上继承了BeanPostProcessor接口,严格意义上来看他们不是两兄弟,而是两父子。但是从生命周期角度我们重点关注其特有的对实例化阶段的影响,图中省略了从BeanPostProcessor继承的方法。
InstantiationAwareBeanPostProcessor extends BeanPostProcessor
InstantiationAwareBeanPostProcessor源码分析:
- postProcessBeforeInstantiation调用点,忽略无关代码:
@Override
protected Object createBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) throws BeanCreationException { try { // Give BeanPostProcessors a chance to return a proxy instead of the target bean instance. // postProcessBeforeInstantiation方法调用点,这里就不跟进了, // 有兴趣的同学可以自己看下,就是for循环调用所有的InstantiationAwareBeanPostProcessor Object bean = resolveBeforeInstantiation(beanName, mbdToUse); if (bean != null) { return bean; } } try { // 上文提到的doCreateBean方法,可以看到 // postProcessBeforeInstantiation方法在创建Bean之前调用 Object beanInstance = doCreateBean(beanName, mbdToUse, args); if (logger.isTraceEnabled()) { logger.trace("Finished creating instance of bean '" + beanName + "'"); } return beanInstance; } } 可以看到,postProcessBeforeInstantiation在doCreateBean之前调用,也就是在bean实例化之前调用的,英文源码注释解释道该方法的返回值会替换原本的Bean作为代理,这也是Aop等功能实现的关键点。
- postProcessAfterInstantiation调用点,忽略无关代码:
protected void populateBean(String beanName, RootBeanDefinition mbd, @Nullable BeanWrapper bw) { // Give any InstantiationAwareBeanPostProcessors the opportunity to modify the // state of the bean before properties are set. This can be used, for example, // to support styles of field injection. boolean continueWithPropertyPopulation = true; // InstantiationAwareBeanPostProcessor#postProcessAfterInstantiation() // 方法作为属性赋值的前置检查条件,在属性赋值之前执行,能够影响是否进行属性赋值! if (!mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) { for (BeanPostProcessor bp : getBeanPostProcessors()) { if (bp instanceof InstantiationAwareBeanPostProcessor) { InstantiationAwareBeanPostProcessor ibp = (InstantiationAwareBeanPostProcessor) bp; if (!ibp.postProcessAfterInstantiation(bw.getWrappedInstance(), beanName)) { continueWithPropertyPopulation = false; break; } } } } // 忽略后续的属性赋值操作代码 } 可以看到该方法在属性赋值方法内,但是在真正执行赋值操作之前。其返回值为boolean,返回false时可以阻断属性赋值阶段(continueWithPropertyPopulation = false;)。
关于BeanPostProcessor执行阶段的源码穿插在下文Aware接口的调用时机分析中,因为部分Aware功能的就是通过他实现的!只需要先记住BeanPostProcessor在初始化前后调用就可以了。
第二大类:只调用一次的接口
这一大类接口的特点是功能丰富,常用于用户自定义扩展。
第二大类中又可以分为两类:
- Aware类型的接口
- 生命周期接口
无所不知的Aware
Aware类型的接口的作用就是让我们能够拿到Spring容器中的一些资源。基本都能够见名知意,Aware之前的名字就是可以拿到什么资源,例如BeanNameAware可以拿到BeanName,以此类推。调用时机需要注意:所有的Aware方法都是在初始化阶段之前调用的!
Aware接口众多,这里同样通过分类的方式帮助大家记忆。
Aware接口具体可以分为两组,至于为什么这么分,详见下面的源码分析。如下排列顺序同样也是Aware接口的执行顺序,能够见名知意的接口不再解释。
Aware Group1
- BeanNameAware
- BeanClassLoaderAware
- BeanFactoryAware
Aware Group2
- EnvironmentAware
- EmbeddedValueResolverAware 这个知道的人可能不多,实现该接口能够获取Spring EL解析器,用户的自定义注解需要支持spel表达式的时候可以使用,非常方便。
- ApplicationContextAware(ResourceLoaderAware\ApplicationEventPublisherAware\MessageSourceAware) 这几个接口可能让人有点懵,实际上这几个接口可以一起记,其返回值实质上都是当前的ApplicationContext对象,因为ApplicationContext是一个复合接口,如下:
public interface ApplicationContext extends EnvironmentCapable, ListableBeanFactory, HierarchicalBeanFactory, MessageSource, ApplicationEventPublisher, ResourcePatternResolver {} 这里涉及到另一道面试题,ApplicationContext和BeanFactory的区别,可以从ApplicationContext继承的这几个接口入手,除去BeanFactory相关的两个接口就是ApplicationContext独有的功能,这里不详细说明。
Aware调用时机源码分析
详情如下,忽略了部分无关代码。代码位置就是我们上文提到的initializeBean方法详情,这也说明了Aware都是在初始化阶段之前调用的!
// 见名知意,初始化阶段调用的方法
protected Object initializeBean(final String beanName, final Object bean, 可以看到并不是所有的Aware接口都使用同样的方式调用。Bean××Aware都是在代码中直接调用的,而ApplicationContext相关的Aware都是通过BeanPostProcessor#postProcessBeforeInitialization()实现的。感兴趣的可以自己看一下ApplicationContextAwareProcessor这个类的源码,就是判断当前创建的Bean是否实现了相关的Aware方法,如果实现了会调用回调方法将资源传递给Bean。
至于Spring为什么这么实现,应该没什么特殊的考量。也许和Spring的版本升级有关。基于对修改关闭,对扩展开放的原则,Spring对一些新的Aware采用了扩展的方式添加。
BeanPostProcessor的调用时机也能在这里体现,包围住invokeInitMethods方法,也就说明了在初始化阶段的前后执行。
关于Aware接口的执行顺序,其实只需要记住第一组在第二组执行之前就行了。每组中各个Aware方法的调用顺序其实没有必要记,有需要的时候点进源码一看便知。
简单的两个生命周期接口
至于剩下的两个生命周期接口就很简单了,实例化和属性赋值都是Spring帮助我们做的,能够自己实现的有初始化和销毁两个生命周期阶段。
- InitializingBean 对应生命周期的初始化阶段,在上面源码的
invokeInitMethods(beanName, wrappedBean, mbd);方法中调用。
有一点需要注意,因为Aware方法都是执行在初始化方法之前,所以可以在初始化方法中放心大胆的使用Aware接口获取的资源,这也是我们自定义扩展Spring的常用方式。
除了实现InitializingBean接口之外还能通过注解或者xml配置的方式指定初始化方法,至于这几种定义方式的调用顺序其实没有必要记。因为这几个方法对应的都是同一个生命周期,只是实现方式不同,我们一般只采用其中一种方式。 - DisposableBean 类似于InitializingBean,对应生命周期的销毁阶段,以ConfigurableApplicationContext#close()方法作为入口,实现是通过循环取所有实现了DisposableBean接口的Bean然后调用其destroy()方法 。感兴趣的可以自行跟一下源码。
扩展阅读: BeanPostProcessor 注册时机与执行顺序
注册时机
我们知道BeanPostProcessor也会注册为Bean,那么Spring是如何保证BeanPostProcessor在我们的业务Bean之前初始化完成呢?
请看我们熟悉的refresh()方法的源码,省略部分无关代码:
@Override
public void refresh() throws BeansException, IllegalStateException { synchronized (this.startupShutdownMonitor) { try { // Allows post-processing of the bean factory in context subclasses. postProcessBeanFactory(beanFactory); // Invoke factory processors registered as beans in the context. invokeBeanFactoryPostProcessors(beanFactory); // Register bean processors that intercept bean creation. // 所有BeanPostProcesser初始化的调用点 registerBeanPostProcessors(beanFactory); // Initialize message source for this context. initMessageSource(); // Initialize event multicaster for this context. initApplicationEventMulticaster(); // Initialize other special beans in specific context subclasses. onRefresh(); // Check for listener beans and register them. registerListeners(); // Instantiate all remaining (non-lazy-init) singletons. // 所有单例非懒加载Bean的调用点 finishBeanFactoryInitialization(beanFactory); // Last step: publish corresponding event. finishRefresh(); } } 可以看出,Spring是先执行registerBeanPostProcessors()进行BeanPostProcessors的注册,然后再执行finishBeanFactoryInitialization初始化我们的单例非懒加载的Bean。
执行顺序
BeanPostProcessor有很多个,而且每个BeanPostProcessor都影响多个Bean,其执行顺序至关重要,必须能够控制其执行顺序才行。关于执行顺序这里需要引入两个排序相关的接口:PriorityOrdered、Ordered
-
PriorityOrdered是一等公民,首先被执行,PriorityOrdered公民之间通过接口返回值排序
-
Ordered是二等公民,然后执行,Ordered公民之间通过接口返回值排序
-
都没有实现是三等公民,最后执行
在以下源码中,可以很清晰的看到Spring注册各种类型BeanPostProcessor的逻辑,根据实现不同排序接口进行分组。优先级高的先加入,优先级低的后加入。
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
// 首先,加入实现了PriorityOrdered接口的BeanPostProcessors,顺便根据PriorityOrdered排了序
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); currentRegistryProcessors.clear(); // Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered. // 然后,加入实现了Ordered接口的BeanPostProcessors,顺便根据Ordered排了序 postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) { currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); currentRegistryProcessors.clear(); // Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear. // 最后加入其他常规的BeanPostProcessors boolean reiterate = true; while (reiterate) { reiterate = false; postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (!processedBeans.contains(ppName)) { currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); reiterate = true; } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); currentRegistryProcessors.clear(); } 根据排序接口返回值排序,默认升序排序,返回值越低优先级越高。
/**
* Useful constant for the highest precedence value.
* @see java.lang.Integer#MIN_VALUE
*/
int HIGHEST_PRECEDENCE = Integer.MIN_VALUE;
/** * Useful constant for the lowest precedence value. * @see java.lang.Integer#MAX_VALUE */ int LOWEST_PRECEDENCE = Integer.MAX_VALUE; PriorityOrdered、Ordered接口作为Spring整个框架通用的排序接口,在Spring中应用广泛,也是非常重要的接口。
总结
Spring Bean的生命周期分为四个阶段和多个扩展点。扩展点又可以分为影响多个Bean和影响单个Bean。整理如下:
四个阶段
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
多个扩展点
- 影响多个Bean
- BeanPostProcessor
- InstantiationAwareBeanPostProcessor
- 影响单个Bean
- Aware
- Aware Group1
- BeanNameAware
- BeanClassLoaderAware
- BeanFactoryAware
- Aware Group2
- EnvironmentAware
- EmbeddedValueResolverAware
- ApplicationContextAware(ResourceLoaderAware\ApplicationEventPublisherAware\MessageSourceAware)
- Aware Group1
- 生命周期
- InitializingBean
- DisposableBean
- Aware
------------------------------------------------------------------------------------------------------------------------------------
前置通知:在目标方法执行前执行
后置通知:在目标方法执行后执行,无论方法是否执行成功
返回通知:在目标方法返回后执行,执行成功之后
异常通知:在目标方法抛异常时执行
环绕通知:在目标方法执行中执行(之前或之后)
-----------------------------------------------------------------------------------------------------------------------------------------
9 servlet3.0和3.1区别
在Servlet 3.0之前:
请求的同步处理的问题是,它会导致线程(执行繁重的任务)在响应发出之前运行很长时间。如果这种情况大规模发生,servlet容器最终会耗尽线程(长时间运行的线程会导致线程耗尽)。
在Servlet 3.0之前,对于这些长时间运行的线程,有一些特定于容器的解决方案,我们可以生成单独的工作线程来执行繁重的任务,然后将响应返回给客户端。启动工作线程后,Servlet线程返回到Servlet线程池。Tomcat的Comet,WebLogic的FutureResponseServlet和WebSphere的异步请求分派器是异步处理实现的一些示例。
Servlet 3.0 Async:
实际工作可以委托给线程池实现(独立于特定于容器的解决方案)。Runnable实现将执行实际的处理,并将使用AsyncContext将该请求分派到另一个资源或写入响应。我们还可以向AsyncContext对象添加AsyncListener实现来实现回调方法。
Servlet 3.1 NIO:
如上所述,Servlet 3.0允许异步请求处理,但仅允许传统的I/O(与NIO相对)。为什么传统的I/O是一个问题?
在传统的I/O中,有两种情况需要考虑:
- 如果进入服务器(I/O)的数据阻塞或流传输的速度比服务器读取的速度慢,则尝试读取此数据的服务器线程必须等待该数据。
- 另一方面,如果从服务器写入
ServletOutputStream的响应数据很慢,则客户端线程必须等待。在这两种情况下,服务器线程都执行传统的I/O(用于请求/响应)块。
换句话说,使用Servlet 3.0,只有请求处理的部分变为异步,而没有用于服务请求和响应的I/O。如果有足够的线程阻塞,这将导致线程耗尽,并影响性能。
在Servlet 3.1 NIO中,这个问题通过ReadListener和WriteListener接口解决。它们在ServletInputStream和ServletOutputStream中注册。侦听器具有回调方法,当内容可读或可写时调用,而不需要servlet容器阻塞I/O线程。因此,这些I/O线程被释放,现在可以为其他请求提供服务,从而提高性能。
一、目录
1.概念
2.生命周期
3.职责
4.执行过程
二、内容
概念
1.servlet:servlet是一种运行服务器端的java应用程序,具有独立于平台和协议的特性,
可以动态生成web页面它工作在客户端请求与服务器响应的中间层;
2.filter:filter是一个可以复用的代码片段,可以用来转换HTTP请求,响应和头信息。
它不能产生一个请求或者响应,它只是修改对某一资源的请求或者响应;
3.listener:监听器,通过listener可以坚挺web服务器中某一执行动作,并根据其要求作出相应的响应。
就是在application,session,request三个对象创建消亡或者往其中添加修改删除属性时自动执行代码的功能组件;
4.interceptor:拦截器是对过滤器更加细化的应用,他不仅可以应用在service方法前后还可以应用到其他方法的前后
拦截器;
5.servlet,filter,listener是配置到web.xml中,interceptor不配置到web.xml中,struts的拦截器配置到struts。xml中。
spring的拦截器配置到spring.xml中;
生命周期
1.servlet
servle的生命周期开始于被装入web服务器的内存中,并在web服务终止或者重新装入servlet的时候结束;
servlet一旦被装入web服务器,一般不会从web服务器内存中删除;直到web服务器关闭;
装入:启动服务器时加载servlet的实例;
初始化:web服务器接收到请求时,或者两者之间的某个时刻启动,调用init()
调用:从第一次到以后的多次访问,都只调用doGet()或dopost)()方法;
销毁;停止服务器时调用destroy()方法,销毁实例;
2.filter
需要实现javax.servlet包的Filter接口的三个方法init(),doFilter(),destroy();
加载:启动服务器时加载过滤器的实例,并调用init()方法;
调用:每次请求的时候只调用方法doFilter()进行处理;
销毁:服务器关闭前调用destroy()方法,销毁实例;
3.listener
web.xml的加载顺序是:context-param->listener->filter->servlet
4.interceptor
加载配置文件后初始化拦截器,当有对action的请求的时候,调用interceptor方法,最后也是根据服务器停止进行销毁;
职责
1.servlet
创建并返回一个包含基于客户请求性质的动态内容的完整的html页面
创建可嵌入到现有的html页面中的一部分html页面(html片段)
读取客户端发来的隐藏数据
读取客户端发来的显示数据
与其他服务器资源(包括数据库和java的应用程序)进行通信
2.filter
filter能够在一个请求到达servlet之前预处理用户请求,也可以在离开servlet时处理http响应:
在执行servlet之前,首先执行filter程序,并为之做一些预处理工作;
在servlet被调用之后截获servlet的执行
3.listener
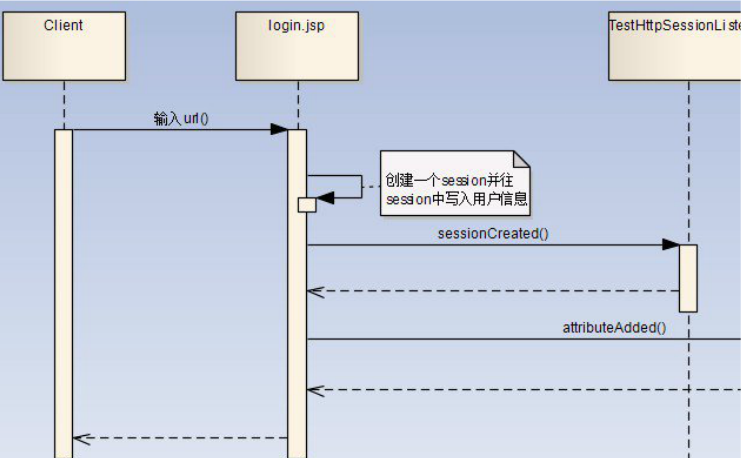
servlet2.4规范提供了8个listener接口,可以将其分为三类,分别如下;
第一类:与HttpContext有关的listener接口,包括:ServletContextListener、ServletContextAttributeListener
第二类:与HttpSession有关的listner接口。包括:HttpSessionListener、HttpSessionAttributeListener、
HttpSessionBindingListener、 HttpSessionActivationListener、
第三类:与ServletRequest有关的Listener接口,包括:ServletRequestListener、ServletRequestAttributeListener
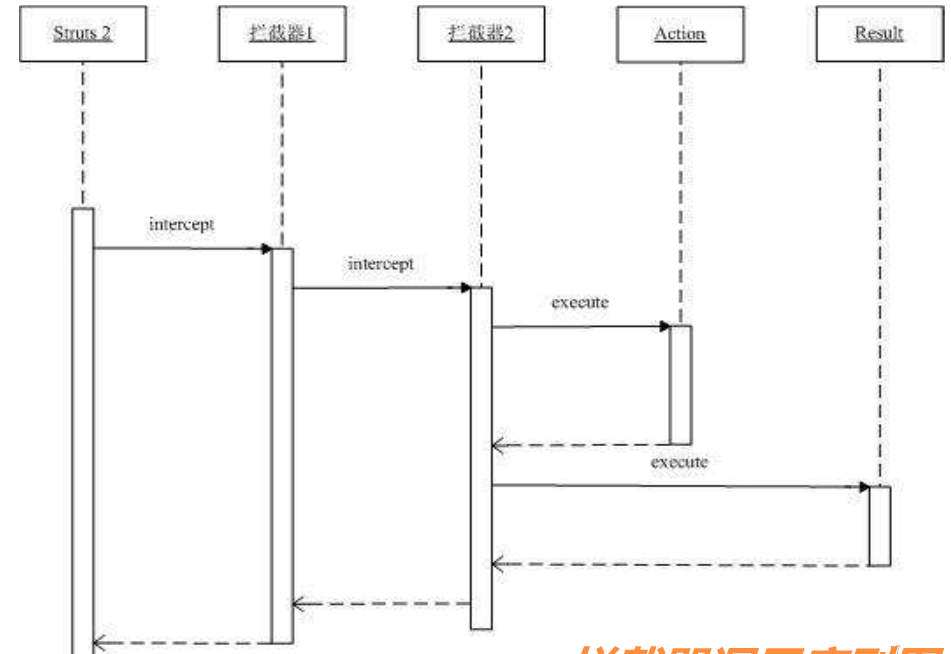
4.interceptor
与过滤器类似,通过层层拦截,处理用户的请求和响应;
区别
1,servlet 流程是短的,url传来之后,就对其进行处理,之后返回或转向到某一自己指定的页面。它主要用来在 业务处理之前进行控制.
2,filter 流程是线性的, url传来之后,检查之后,可保持原来的流程继续向下执行,被下一个filter, servlet接收等,而servlet 处理之后,不会继续向下传递。filter功能可用来保持流程继续按照原来的方式进行下去,或者主导流程,而servlet的功能主要用来主导流程。
filter可用来进行字符编码的过滤,检测用户是否登陆的过滤,禁止页面缓存等
3, servlet,filter都是针对url之类的,而listener是针对对象的操作的,如session的创建,session.setAttribute的发生,在这样的事件发生时做一些事情。
可用来进行:Spring整合Struts,为Struts的action注入属性,web应用定时任务的实现,在线人数的统计等;
4,interceptor拦截器,类似于filter,不过在struts中配置,不是在web.xml,并且不是针对url的而是针对action的,当页面提交时,进行过滤操作;
执行流程
1.servlet:

2.filter

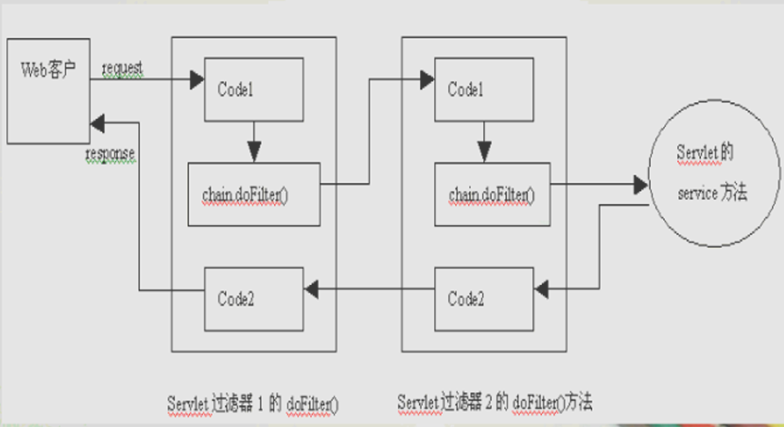
3.listener
4.interceptor
--------------------------------------------------------------------------------------------------------------
1.拦截器是基于java的反射机制的,而过滤器是基于函数回调。
2.拦截器不依赖与servlet容器,过滤器依赖与servlet容器。
3.拦截器只能对action请求起作用,而过滤器则可以对几乎所有的请求起作用。
4.拦截器可以访问action上下文、值栈里的对象,而过滤器不能访问。
5.在action的生命周期中,拦截器可以多次被调用,而过滤器只能在容器初始化时被调用一次
------------------------------------------------------------------------------------------------------------------------------------------------
11 你之前有用过哪些代码规范检查工具?
https://blog.csdn.net/EndTheme_Xin/article/details/85122956
https://www.cnblogs.com/chenjfblog/p/7685579.html
-----------------------------------------------------------------------------------------------------------------------------------------
12 用过maven吗?都有哪些maven命令?分别是做什么的?
一、Maven常用命令及其作用
1、 maven clean:对项目进行清理,删除target目录下编译的内容
2、 maven compile:编译项目源代码
3、 maven test:对项目进行运行测试
4、 maven packet:打包文件并存放到项目的target目录下,打包好的文件通常都是编译后的class文件
5、 maven install:在本地仓库生成仓库的安装包,可供其他项目引用,同时打包后的文件放到项目的target目录下
二、常用命令使用场景举例
1、mvn clean package依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)等7个阶段
package命令完成了项目编译、单元测试、打包功能,但没有把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库
2、mvn clean install依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)、install等8个阶段
install命令完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库,但没有布署到远程maven私服仓库
3、mvn clean deploy依次执行了clean、resources、compile、testResources、testCompile、test、jar(打包)、install、deploy等9个阶段
deploy命令完成了项目编译、单元测试、打包功能,同时把打好的可执行jar包(war包或其它形式的包)布署到本地maven仓库和远程maven私服仓库
三、常见问题
(一)mvn clean install 和 mvn install 的区别
1、根据maven在执行一个生命周期命令时,理论上讲,不做mvn install 得到的jar包应该是最新的,除非使用其他方式修改jar包的内容,但没有修改源代码
2、平时可以使用mvn install ,不使用clean会节省时间,但是最保险的方式还是mvn clean install,这样可以生成最新的jar包或者其他包
(二)maven两种跳过单元测试方法的区别
1、 mvn package -Dmaven.test.skip=true
不但跳过了单元测试的运行,同时也跳过了测试代码的编译
2、 mvn package -DskipTests
跳过单元测试,但是会继续编译。如果没时间修改单元测试的bug,或者单元测试编译错误,则使用第一种,不要使用第二种
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
13 你用过tomcat吗?tomcat有几个子目录? 如果修改内存,要改哪里?
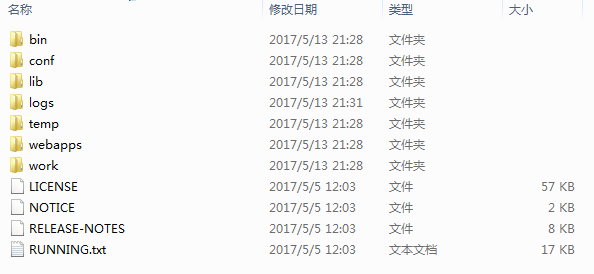
一、bin文件(存放启动和关闭tomcat脚本)

其中.bat和.sh文件很多都是成对出现的,作用是一样的,一个是Windows的,一个是Linux。
① startup文件:主要是检查catalina.bat/sh 执行所需环境,并调用catalina.bat 批处理文件。启动tomcat。
异常:打开可能有闪退的问题。原因可能有以下两点:
1)缺少环境变量配置,startup会检查你的电脑环境变量是否有JAVA_HOME。
2)已经开启了Tomcat容器,再次开启端口号会被占用。
java.net.BindException: Address already in use: JVM_Bind
② catalina文件:真正启动Tomcat文件,可以在里面设置jvm参数。
异常:可能出现内存溢出错误可以考虑修改它
1)java.lang.OutOfMemoryError: Java heap space
Tomcat默认可以使用的内存为128MB,在较大型的应用项目中,这点内存是不够的,从而导致客户端显示500错误。
Windows环境下修改catalina.bat文件,在文件开头增加如下设置:set JAVA_OPTS=-Xms256m -Xmx512m
Linux环境下修改catalina.sh文件,在文件开头增加如下设置:JAVA_OPTS=’-Xms256m -Xmx512m’
其中,-Xms设置初始化内存大小,-Xmx设置可以使用的最大内存。
2) java.lang.OutOfMemoryError: PermGen space
PermGen space的全称是Permanent Generation space,是指内存的永久保存区域,这块内存主要是被JVM
存放Class和Meta信息的,Class在被Loader时就会被放到PermGen space中,它和存放类实例(Instance)的
Heap区域不同,GC(Garbage Collection)不会在主程序运行期对PermGen space进行清理,所以如果你的应用
中有很CLASS的话,就很可能出现PermGen space错误,这种错误常见在web服务器对JSP进行pre compile的
时候。如果你的WEB APP下用了大量的第三方jar, 其大小超过了jvm默认的大小(4M)那么就会产生此错误信息了
解决方法:
在catalina.bat的第一行增加:(Windows)
set JAVA_OPTS=-Xms64m -Xmx256m -XX:PermSize=128M -XX:MaxNewSize=256m -
XX:MaxPermSize=256m
在catalina.sh的第一行增加:(Linux)
JAVA_OPTS=-Xms64m -Xmx256m -XX:PermSize=128M -XX:MaxNewSize=256m -
XX:MaxPermSize=256m
③ shutdown文件:关闭Tomcat
④ Tomcat8文件:相当于控制台直接输入startup
④ Tomcat8w文件:图像化控制Tomcat
如果想启动Tomcat,就点击Start。终止就点击Stop。
异常:点击Tomcat8和Tomcat8w的时候出现错误
解决:在命令行执行 service.bat install(必须在bin文件目录下执行),再点击就OK了。
二、conf文件(存放tomcat的配置文件)
① Catalina文件:用于存储自定义部署Web应用的路径(上一节详细阐述到了,如何部署)
② server.xml:
1 <?xml version="1.0" encoding="UTF-8"?> 2 3 <!-- Server代表一个 Tomcat 实例。可以包含一个或多个 Services,其中每个Service都有自己的Engines和Connectors。 4 port="8005"指定一个端口,这个端口负责监听关闭tomcat的请求 5 --> 6 <Server port="8005" shutdown="SHUTDOWN"> 7 <!-- 监听器 --> 8 <Listener className="org.apache.catalina.startup.VersionLoggerListener" /> 9 <Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" /> 10 <Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" /> 11 <Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" /> 12 <Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" /> 13 <!-- 全局命名资源,定义了UserDatabase的一个JNDI(java命名和目录接口),通过pathname的文件得到一个用户授权的内存数据库 --> 14 <GlobalNamingResources> 15 <Resource name="UserDatabase" auth="Container" 16 type="org.apache.catalina.UserDatabase" 17 description="User database that can be updated and saved" 18 factory="org.apache.catalina.users.MemoryUserDatabaseFactory" 19 pathname="conf/tomcat-users.xml" /> 20 </GlobalNamingResources> 21 <!-- Service它包含一个<Engine>元素,以及一个或多个<Connector>,这些Connector元素共享用同一个Engine元素 --> 22 <Service name="Catalina"> 23 <!-- 24 每个Service可以有一个或多个连接器<Connector>元素, 25 第一个Connector元素定义了一个HTTP Connector,它通过8080端口接收HTTP请求;第二个Connector元素定 26 义了一个JD Connector,它通过8009端口接收由其它服务器转发过来的请求. 27 --> 28 <Connector port="8080" protocol="HTTP/1.1" 29 connectionTimeout="20000" 30 redirectPort="8443" /> 31 <Connector port="8009" protocol="AJP/1.3" redirectPort="8443" /> 32 <!-- 每个Service只能有一个<Engine>元素 --> 33 <Engine name="Catalina" defaultHost="localhost"> 34 <Realm className="org.apache.catalina.realm.LockOutRealm"> 35 <Realm className="org.apache.catalina.realm.UserDatabaseRealm" 36 resourceName="UserDatabase"/> 37 </Realm> 38 <!-- 默认host配置,有几个域名就配置几个Host,但是这种只能是同一个端口号 --> 39 <Host name="localhost" appBase="webapps" 40 unpackWARs="true" autoDeploy="true"> 41 <!-- Tomcat的访问日志,默认可以关闭掉它,它会在logs文件里生成localhost_access_log的访问日志 --> 42 <Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" 43 prefix="localhost_access_log" suffix=".txt" 44 pattern="%h %l %u %t "%r" %s %b" /> 45 </Host> 46 <Host name="www.hzg.com" appBase="webapps" 47 unpackWARs="true" autoDeploy="true"> 48 <Context path="" docBase="/myweb1" /> 49 <Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs" 50 prefix="hzg_access_log" suffix=".txt" 51 pattern="%h %l %u %t "%r" %s %b" /> 52 </Host> 53 </Engine> 54 </Service> 55 </Server>
访问http://localhost:8080/aaa和http://www.hzg.com/8080/aaa效果一致。
③ tomcat-users.xml:配置Tomcat的server的manager信息
1 <?xml version="1.0" encoding="UTF-8"?> 2 <tomcat-users xmlns="http://tomcat.apache.org/xml" 3 xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" 4 xsi:schemaLocation="http://tomcat.apache.org/xml tomcat-users.xsd" 5 version="1.0"> 6 <role rolename="manager-gui"/> 7 <user username="manager" password="manager" roles="manager-gui"/> 8 </tomcat-users>
三、lib文件(存放Tomcat运行需要的库文件)
存放Tomcat运行需要的库文件
四、logs文件(存放Tomcat执行时的LOG文件)

1、catalina.日期.log:控制台日志
2、commons-daemon.日期.log:启动、重启和停止对Tomcat的操作日志
3、host-manager.日期.log:Tomcat管理页面中的host-manager的操作日志
4、localhost.日期.log:Web应用的内部程序日志
5、localhost_access_log.日期:用户请求Tomcat的访问日志(这个文件在conf/server.xml里配置)

6、manager.日期.log:Tomcat管理页面中的manager app的操作日志。
五、temp文件(存放Tomcat执行时的临时文件)
temp目录用户存放tomcat在运行过程中产生的临时文件。(清空不会对tomcat运行带来影响)
六、webapps文件(存放Tomcat的应用文件)
webapps目录用来存放应用程序,当tomcat启动时会去加载webapps目录下的应用程序。可以以文件夹、war包、jar包的形式发布应用。
当然,你也可以把应用程序放置在磁盘的任意位置,在配置文件中映射好就行。
七、work文件(存放Tomcat运行时产生的class文件)
work目录用来存放tomcat在运行时的编译后文件,例如JSP编译后的文件。清空work目录,然后重启tomcat,可以达到清除缓存的作用。

-------------------------------------------------------------------------------------------------------------------------
linux :
修改TOMCAT_HOME/bin/catalina.sh,在echo "Using CATALINA_BASE: $CATALINA_BASE"上面加入以下行:
JAVA_OPTS="-server -XX:PermSize=64M -XX:MaxPermSize=256M
windows:
修改TOMCAT_HOME/bin/catalina.bat
再 rem ----- Execute The Requested Command --------------------------------------- 下面加上:
JAVA_OPTS=-server -XX:PermSize=128M -XX:MaxPermSize=512M
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
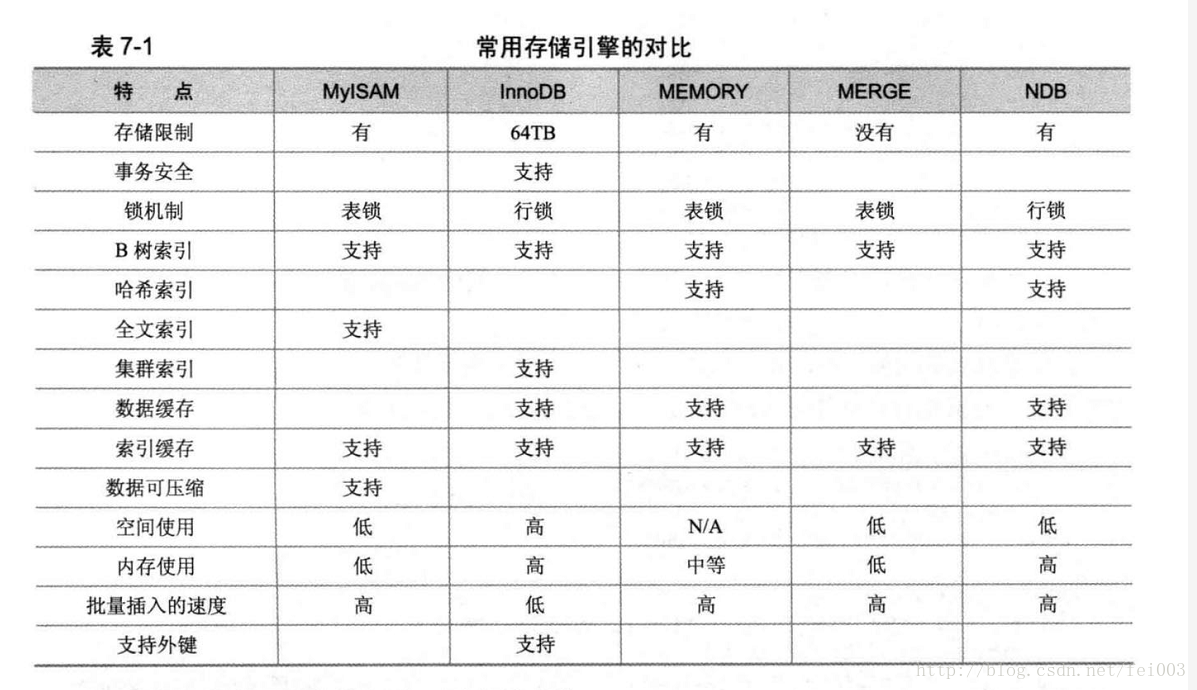
mysql几种引擎?
MySQL5.5以后默认使用InnoDB存储引擎,其中InnoDB和BDB提供事务安全表,其它存储引擎都是非事务安全表。
若要修改默认引擎,可以修改配置文件中的default-storage-engine。可以通过:show variables like ‘default_storage_engine’;查看当前数据库到默认引擎。命令:show engines和show variables like ‘have%’可以列出当前数据库所支持到引擎。其中Value显示为disabled的记录表示数据库支持此引擎,而在数据库启动时被禁用。在MySQL5.1以后,INFORMATION_SCHEMA数据库中存在一个ENGINES的表,它提供的信息与show engines;语句完全一样,可以使用下面语句来查询哪些存储引擎支持事物处理:select engine from information_chema.engines where transactions = ‘yes’;
可以通过engine关键字在创建或修改数据库时指定所使用到引擎。
主要存储引擎:MyISAM、InnoDB、MEMORY和MERGE介绍:
在创建表到时候通过engine=…或type=…来指定所要使用到引擎。show table status from DBname来查看指定表到引擎。
MyISAM
它不支持事务,也不支持外键,尤其是访问速度快,对事务完整性没有要求或者以SELECT、INSERT为主的应用基本都可以使用这个引擎来创建表。
每个MyISAM在磁盘上存储成3个文件,其中文件名和表名都相同,但是扩展名分别为:
- .frm(存储表定义)
- MYD(MYData,存储数据)
- MYI(MYIndex,存储索引)
数据文件和索引文件可以放置在不同的目录,平均分配IO,获取更快的速度。要指定数据文件和索引文件的路径,需要在创建表的时候通过DATA DIRECTORY和INDEX DIRECTORY语句指定,文件路径需要使用绝对路径。
每个MyISAM表都有一个标志,服务器或myisamchk程序在检查MyISAM数据表时会对这个标志进行设置。MyISAM表还有一个标志用来表明该数据表在上次使用后是不是被正常的关闭了。如果服务器以为当机或崩溃,这个标志可以用来判断数据表是否需要检查和修复。如果想让这种检查自动进行,可以在启动服务器时使用–myisam-recover现象。这会让服务器在每次打开一个MyISAM数据表是自动检查数据表的标志并进行必要的修复处理。MyISAM类型的表可能会损坏,可以使用CHECK TABLE语句来检查MyISAM表的健康,并用REPAIR TABLE语句修复一个损坏到MyISAM表。
MyISAM的表还支持3种不同的存储格式:
- 静态(固定长度)表
- 动态表
- 压缩表
其中静态表是默认的存储格式。静态表中的字段都是非变长字段,这样每个记录都是固定长度的,这种存储方式的优点是存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多。静态表在数据存储时会根据列定义的宽度定义补足空格,但是在访问的时候并不会得到这些空格,这些空格在返回给应用之前已经去掉。同时需要注意:在某些情况下可能需要返回字段后的空格,而使用这种格式时后面到空格会被自动处理掉。
动态表包含变长字段,记录不是固定长度的,这样存储的优点是占用空间较少,但是频繁到更新删除记录会产生碎片,需要定期执行OPTIMIZE TABLE语句或myisamchk -r命令来改善性能,并且出现故障的时候恢复相对比较困难。
压缩表由myisamchk工具创建,占据非常小的空间,因为每条记录都是被单独压缩的,所以只有非常小的访问开支。
InnoDB
InnoDB存储引擎提供了具有提交、回滚和崩溃恢复能力的事务安全。但是对比MyISAM的存储引擎,InnoDB写的处理效率差一些并且会占用更多的磁盘空间以保留数据和索引。
1)自动增长列:
InnoDB表的自动增长列可以手工插入,但是插入的如果是空或0,则实际插入到则是自动增长后到值。可以通过”ALTER TABLE…AUTO_INCREMENT=n;”语句强制设置自动增长值的起始值,默认为1,但是该强制到默认值是保存在内存中,数据库重启后该值将会丢失。可以使用LAST_INSERT_ID()查询当前线程最后插入记录使用的值。如果一次插入多条记录,那么返回的是第一条记录使用的自动增长值。
对于InnoDB表,自动增长列必须是索引。如果是组合索引,也必须是组合索引的第一列,但是对于MyISAM表,自动增长列可以是组合索引的其他列,这样插入记录后,自动增长列是按照组合索引到前面几列排序后递增的。
2)外键约束:
MySQL支持外键的存储引擎只有InnoDB,在创建外键的时候,父表必须有对应的索引,子表在创建外键的时候也会自动创建对应的索引。
在创建索引的时候,可以指定在删除、更新父表时,对子表进行的相应操作,包括restrict、cascade、set null和no action。其中restrict和no action相同,是指限制在子表有关联的情况下,父表不能更新;casecade表示父表在更新或删除时,更新或者删除子表对应的记录;set null 则表示父表在更新或者删除的时候,子表对应的字段被set null。
当某个表被其它表创建了外键参照,那么该表对应的索引或主键被禁止删除。
可以使用set foreign_key_checks=0;临时关闭外键约束,set foreign_key_checks=1;打开约束。
MEMORY
memory使用存在内存中的内容来创建表。每个MEMORY表实际对应一个磁盘文件,格式是.frm。MEMORY类型的表访问非常快,因为它到数据是放在内存中的,并且默认使用HASH索引,但是一旦服务器关闭,表中的数据就会丢失,但表还会继续存在。
默认情况下,memory数据表使用散列索引,利用这种索引进行“相等比较”非常快,但是对“范围比较”的速度就慢多了。因此,散列索引值适合使用在”=”和”<=>”的操作符中,不适合使用在”<”或”>”操作符中,也同样不适合用在order by字句里。如果确实要使用”<”或”>”或betwen操作符,可以使用btree索引来加快速度。
存储在MEMORY数据表里的数据行使用的是长度不变的格式,因此加快处理速度,这意味着不能使用BLOB和TEXT这样的长度可变的数据类型。VARCHAR是一种长度可变的类型,但因为它在MySQL内部当作长度固定不变的CHAR类型,所以可以使用。
create table tab_memory engine=memory select id,name,age,addr from man order by id;
使用USING HASH/BTREE来指定特定到索引。
create index mem_hash using hash on tab_memory(city_id);
在启动MySQL服务的时候使用–init-file选项,把insert into…select或load data infile 这样的语句放入到这个文件中,就可以在服务启动时从持久稳固的数据源中装载表。
服务器需要足够的内存来维持所在的在同一时间使用的MEMORY表,当不再使用MEMORY表时,要释放MEMORY表所占用的内存,应该执行DELETE FROM或truncate table或者删除整个表。
每个MEMORY表中放置到数据量的大小,受到max_heap_table_size系统变量的约束,这个系统变量的初始值是16M,同时在创建MEMORY表时可以使用MAX_ROWS子句来指定表中的最大行数。
MERGE
merge存储引擎是一组MyISAM表的组合,这些MyISAM表结构必须完全相同,MERGE表中并没有数据,对MERGE类型的表可以进行查询、更新、删除的操作,这些操作实际上是对内部的MyISAM表进行操作。对于对MERGE表进行的插入操作,是根据INSERT_METHOD子句定义的插入的表,可以有3个不同的值,first和last值使得插入操作被相应的作用在第一个或最后一个表上,不定义这个子句或者为NO,表示不能对这个MERGE表进行插入操作。可以对MERGE表进行drop操作,这个操作只是删除MERGE表的定义,对内部的表没有任何影响。MERGE在磁盘上保留2个以MERGE表名开头文件:.frm文件存储表的定义;.MRG文件包含组合表的信息,包括MERGE表由哪些表组成,插入数据时的依据。可以通过修改.MRG文件来修改MERGE表,但是修改后要通过flush table刷新。
create table man_all(id int,name varchar(20))engine=merge union=(man1,man2) insert_methos=last;