在bin目录运行,db目录必须已经提前创建,否则保存,然后就可以使用了
mongod --dbpath d:\data\db默认登录不需要验证。可以使用compass更加直观的使用
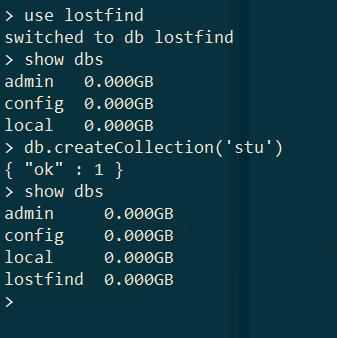
创建数据库
使用use,如果不存在则指向该数据库,但如果不添加数据,该数据库依然不会被真正创建
可以看到,只有进行操作之后才会真正创建数据库
删除使用
db.dropDatabase()
修改
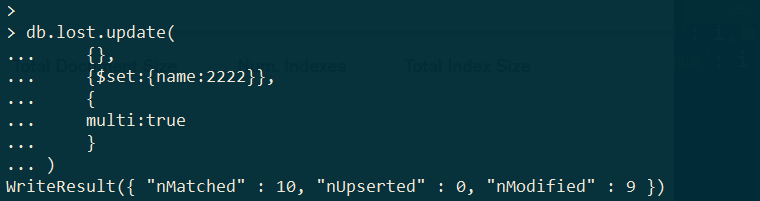
默认update只修改 第一个找到的数据,并且不使用set的话,会替换整个文档

修改多行,需要使用set和multi关键字,匹配了10条记录,但由于之前修改了一次,所以只修改了9条记录
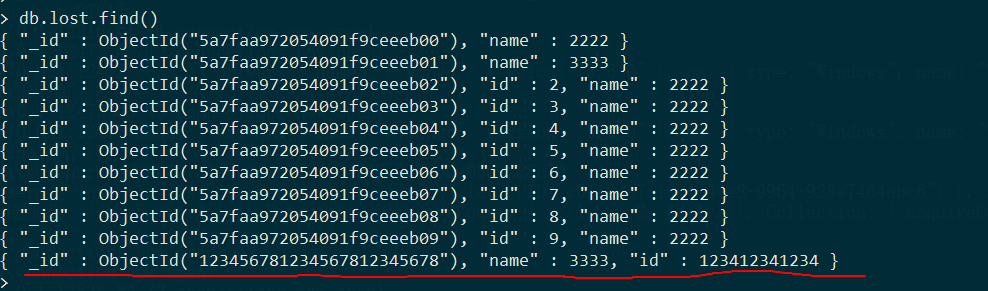
save,如果_id 已经存在则替换原始文档,如果不存在则新增并设置_id
db.lost.save({
'_id': ObjectId('5a7faa972054091f9ceeeb01'),
'name': 3333
})
db.lost.save({
'_id': ObjectId('123456781234567812345678'),
'name': 3333,
'id':123412341234
})
注意_id长度必须与原始的相同,否则保存失败
删除

删除全部
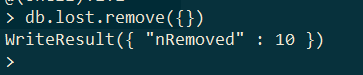
只删除一条
db.lost.remove({},{justOne:true})

比较运算
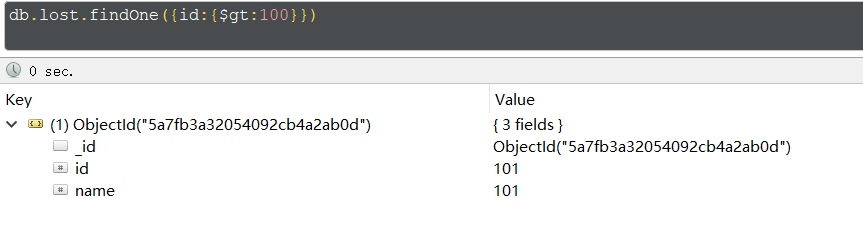
逻辑 运算,使用逗号间隔,表示一系列的条件必须全部满足
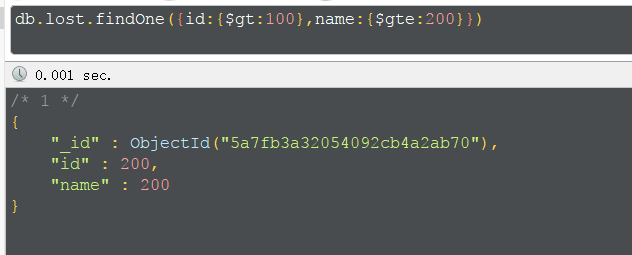
使用or,表示数组中一个条件满足即可
集合in,并不是范围
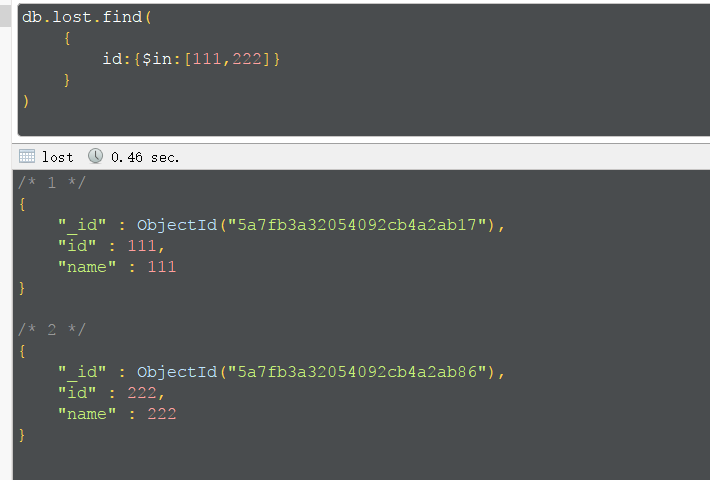
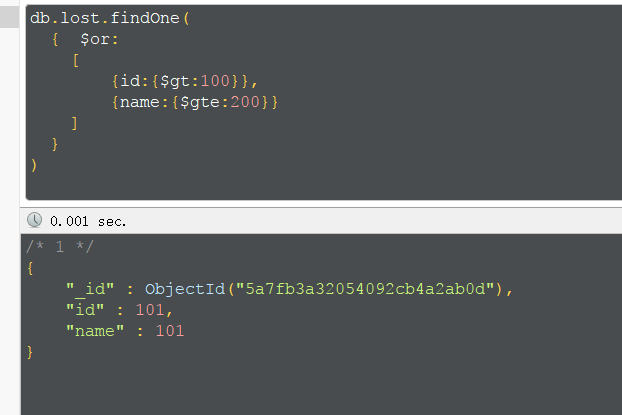
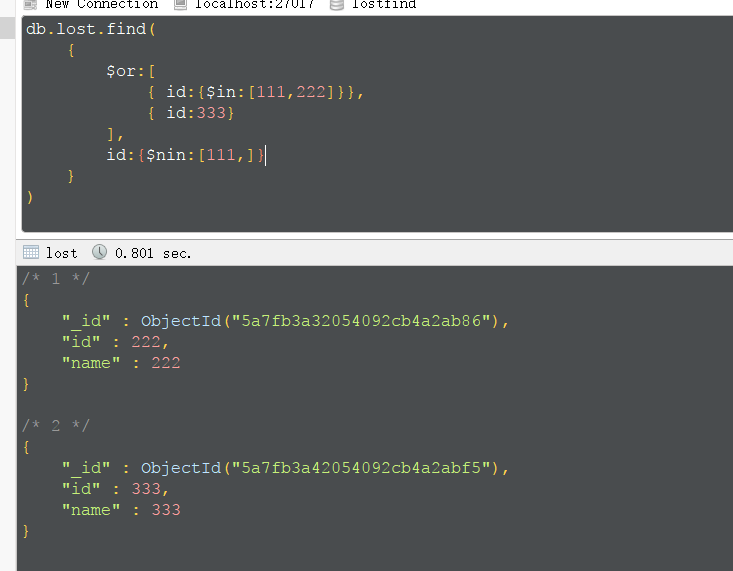
混合使用,查找id为111,222或id为333并且id不为111的结果
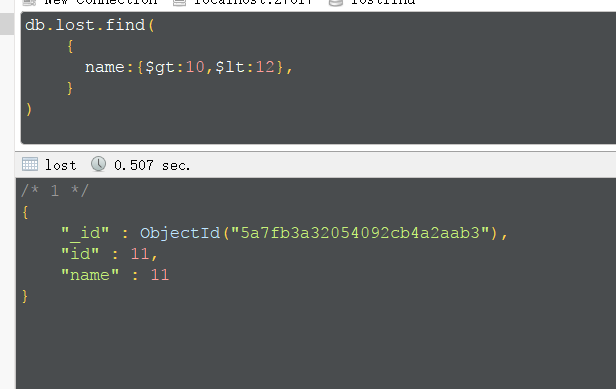
范围查询的坑,只会查到比20小的数据

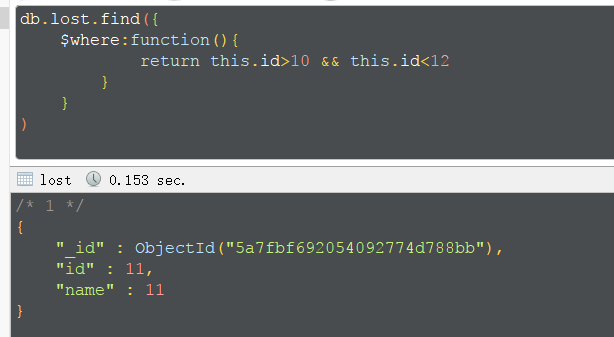
自定义查询,不推荐,十分慢
正则匹配,查询指定范围中,以2开头的数据
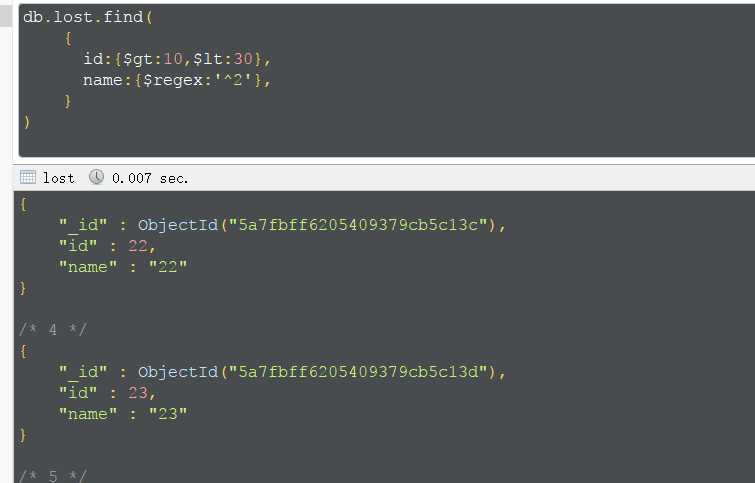
limit skip 完成分页,skip是在查询出的结果中跳过的指定条数

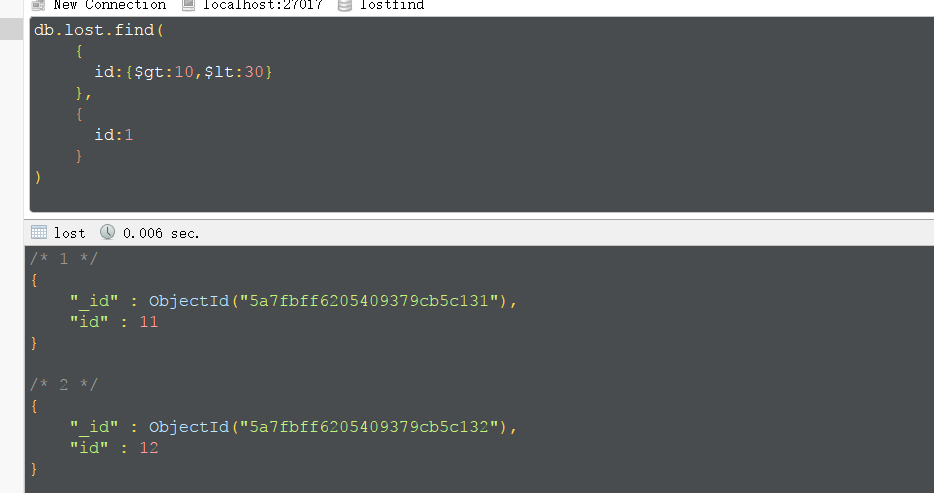
指定返回的字段。_id默认显示,不设置表示不显示,字段设置为1,表示显示
sort排序

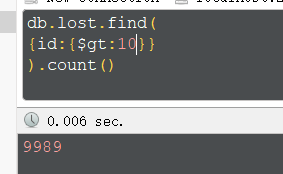
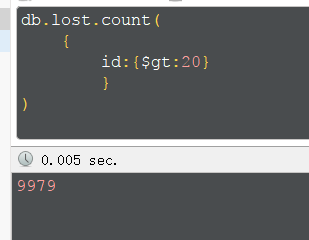
统计个数,使用count,或者省略find
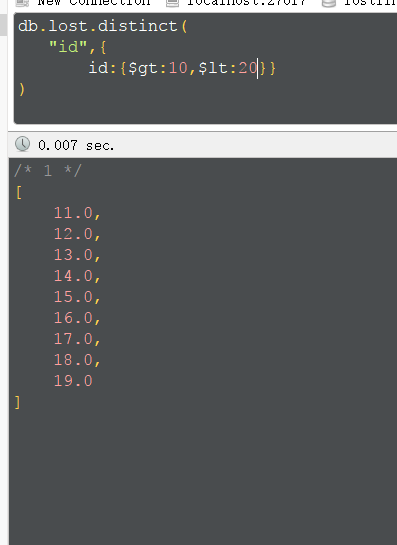
去重
distinct(‘去重的字段’,查询条件)
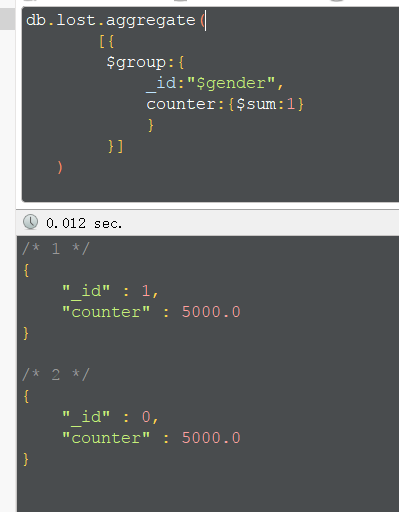
聚合函数,将文档分组,_id表示,用于分组的字段,sum后面的数字表示每次 有一行就加一
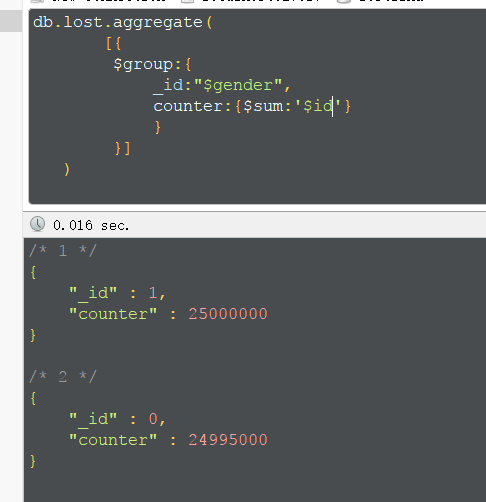
统计某一个字段的和
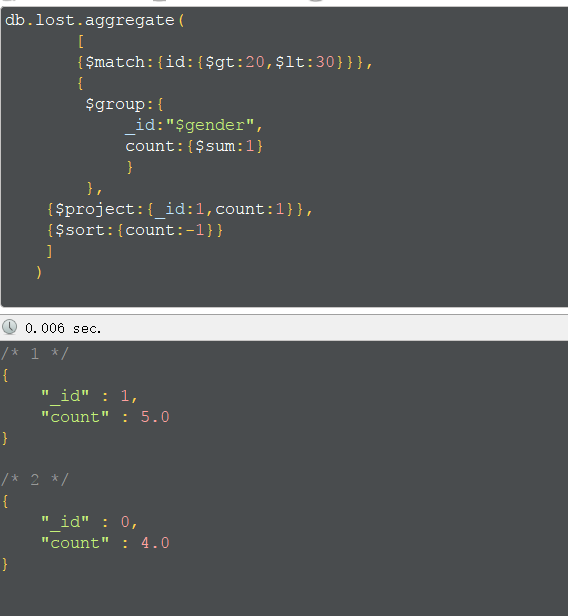
管道的使用,先匹配,然后分组,将数据文档用push放入指定字段

排序和指定显示字段
查看查询计划

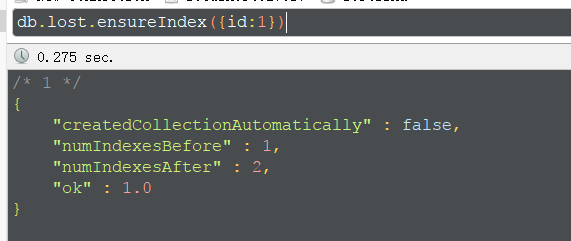
建立索引,1/-1 表示顺序还是降序
db.collection.ensureIndex({属性,1、-1})