注:本文只讲思路,非实战教程
【python爬虫+pyqt5+pyinstaller】
前言
前段时间在某个弹窗里打开了一本漫画,奈何正版会员太过昂贵(美元),因此寻思着去某些网站寻找资源。资源很容易找到,但是观看体验让人难以忍受
- 垃圾广告太多
- 强制性弹窗,让手机几乎崩溃
- pc端利用chrome可以拦截弹窗,但是用电脑观看总是有点不舒服
因此决定将漫画爬取并保存成pdf形式,在掌阅app里观看
一.作品演示

下载好的漫画以pdf形式存放。
二.开发思路
1.漫画的简要信息爬取

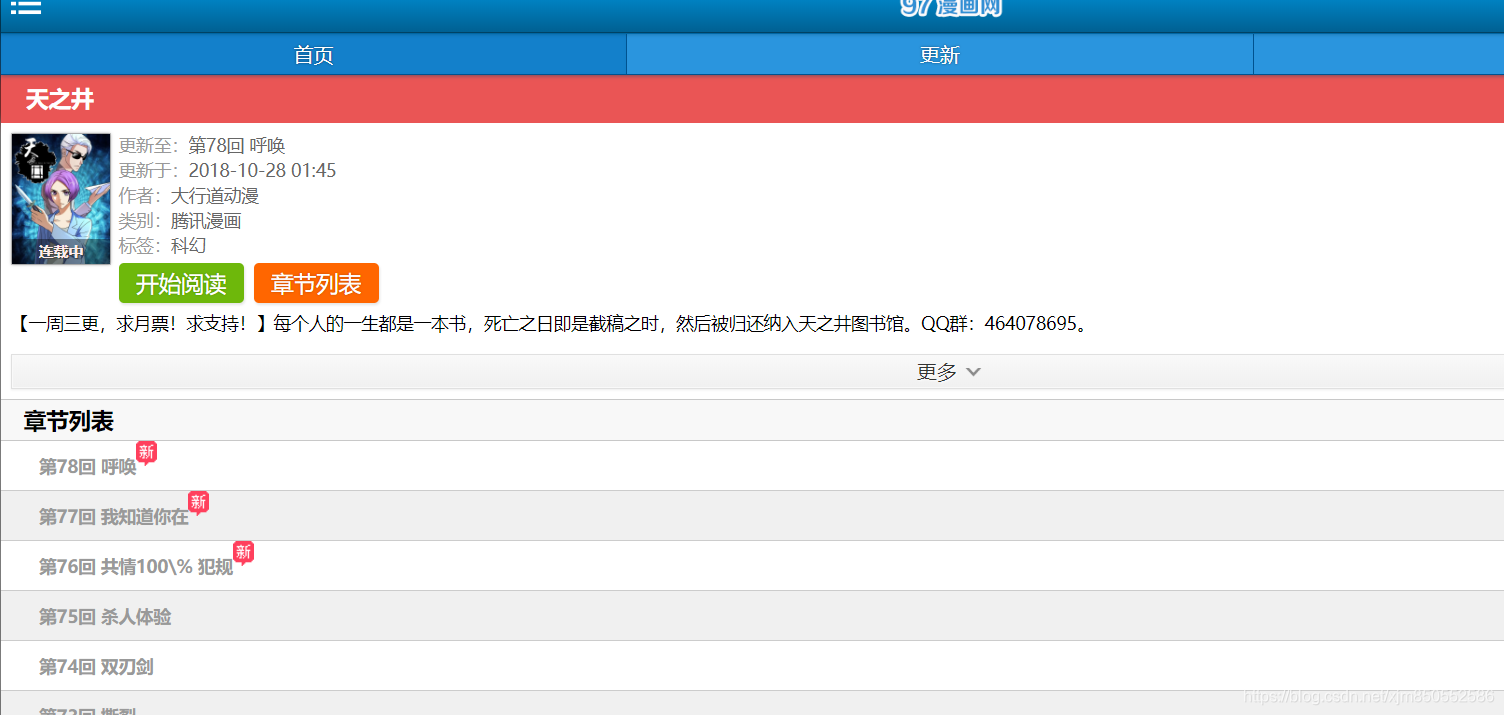
该网站下的小说的章节列表完全显示,未采用ajax技术动态加载,因此很容易爬取(当然下载器的制作需要多个网站混合,不过思路大致相同)。
方法:直接下载网页源代码,然后通过正则表达式或者xpath进行数据抓取
章节信息采用多重数组(list)存储,保存章节名称,超链接
假如网站的信息是通过ajax动态加载,则需要通过打开f12查看network信息/或者通过fiddler抓包
2.漫画下载
因为章节信息存储在list中,完本下载就是遍历整个list中的url,而部分章节下载就是先对list进行切片,然后再进行遍历。
以单个url举例,爬取过程:
- 打开url
- 遍历存储图片的原链接(src)【关键】
- 遍历访问src,下载存储图片
爬取实战中可能遇到的几种漫画网站:
(1)静态漫画网站
该网站基本无任何爬取难度。其漫画图片原链接直接暴露在网页代码中,直接通过urllib/request等常用库下载网页后提取其中图片链接即可。
(2)利用ajax技术的动态漫画网站
【该网站的形式为:打开一本漫画后,无需翻页,一直下拉便可看到结束】
首先打开f12下的network页面,观看漫画过程中不断下拉页面,使其进行ajax加载,然后在network里寻找数据更新条目,然后爬取。
(3)利用js技术的动态漫画网站
题主在下载器的制作过程中主要遇到的网站。其中这类网站还有区别。
1.虽然是动态加载,但是图片信息完全暴露在网页源代码中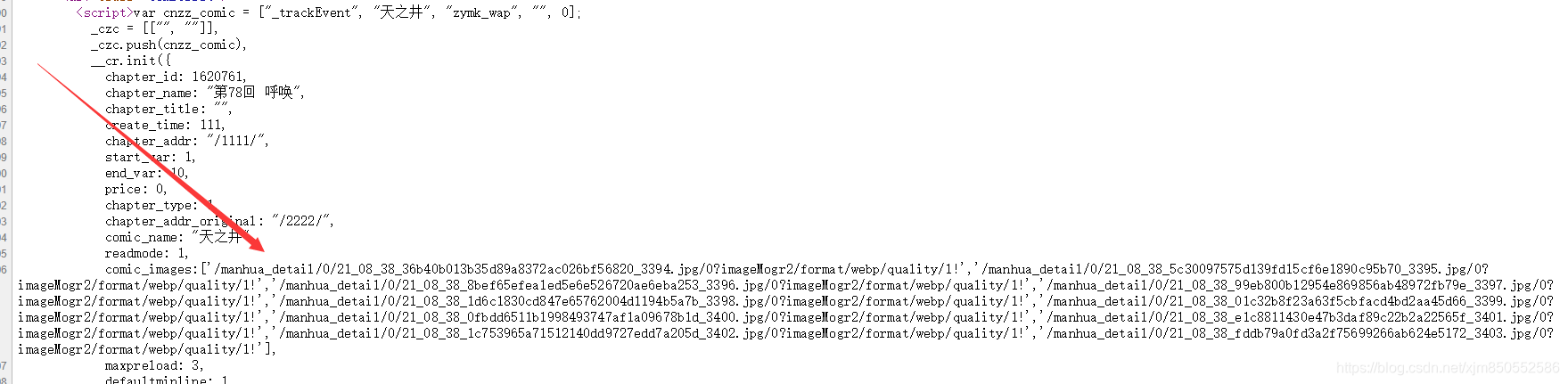
2.实动态加载,信息通过抓包或者源代码完全寻迹不到(最难爬取)
此时便需要使用python大法中针对动态加载网页的策略了。
(1)通过selenium+phantomjs
按照该小标题自行度娘/google便可搜到N多教程方法
该方法优点:适合打包,打包文件夹里放入一个phantomjs.exe便可跨机器使用
备注:
目前selenium已经停止与phantomjs的合作。
因此还想继续使用的话只能降级selenium。
当前配置:
selenimum==3.0
phantomjs==2.11
(2)通过selenium+chrome无框浏览器
该方法优点:无需降级selenium
缺点:要求运行机器上必须装有chrome浏览器,局限性较大。
3.漫画搜索

多数网站的搜索url如下:

因此找到了该规律,便可以自行制作搜索爬虫了。
需要注意的点:
request.get(url)或者urllib.Request(url)中的url里不能包含中文
因此我们获取搜索信息后,需要先对中文进行转码,然后放入url中。
转码采用parse.quote()函数。
4.其他信息的爬取过程同上
5.搜索/爬取信息加速
采用sqllite数据库。
爬取数千个漫画的简介(包含名称,封面图片链接,章节页面链接)存储在数据库中。在搜索时优先检索数据库,节约了简介信息爬取时间。

多线程爬虫
对于并行爬虫而言,处理空队列要比处理序列爬虫更加复杂,空的队列并不意味着爬虫已经完成工作,因为此刻其他的进程或线程可能依然在解析网页,并且马上会产生新的URL。进程或者线程管理者需要给报告队列为空的线程发送临时的休眠信号,线程管理员需要不断追踪休眠线程的数目,只有当所有的线程都休眠的时候,爬虫才可以终止。
多线程在网络阻塞方面的效率极高,因此采用多线程爬虫可以大幅度缩减爬取时间!
pyqt方面
1.基本控件,基本布局
2.利用qss美化页面
参考:https://www.colabug.com/4444378.html
3.多线程ui
与多线程爬虫不同,多线程ui是为了防止页面“卡死”。
举个例子:
1.在搜索漫画时,程序需要执行爬虫进行抓取。加入是单线程ui,在爬虫抓取结束前,页面必须进行等待,不能进行其他操作,宛若卡死,影响用户体验。
2.在下载管理页面,用户需要了解下载进度,如果是单线程ui,用户不仅操纵不了页面,而且看到的进度只有0和100。采用多线程ui后,爬虫在爬取过程中不断发生信号,页面进行刷新,可以有效提供信息。
一些额外的坑
1.编码问题
我觉得可能大家都会遇到这种问题,爬取后打印页面信息,发现很多乱码。
其中编码无非gbk,utf8,gb2312等这些,推荐挨个试吧。
其他
当然开发过程中各种各样的问题都会出现,我编写博客时也不可能事无巨细都写出来。
因此大家在开发过程中如果遇到问题可以留言。
有偿代写相关软件。
源码参考请留言邮箱信息。
打包完成的下载器下载链接:https://pan.baidu.com/s/1dGmJ5mYISkHehn0GBfiXHA。
【禁止转载,严禁软件违规使用】