我接触飞桨框架是在2019年年底左右,到现在已经有大半年了,这段时间里,我通过飞桨框架学习了很多关于机器学习的理论和方法,也跑过不少项目了。但是,在往更深的领域去做时,我发现越来越吃力了,其实问题就在于基础不够扎实,我在找解决办法的时候,翻阅了AI Studio社区里很多大佬的文章。在翻阅这些文章的过程中,我发现我对飞桨确实不够了解,并且飞桨是2016年开源的,有些文章的内容稍微有一点点过时的,所以借此机会,我打算重新开始学习飞桨框架:

1. 关于PaddlePaddle的版本
这里的版本都是指大方向,即出现之前的版本和出现之后的版本
Fluid
出现Fluid前的版本和出现Fluid后的版本做比较,重点介绍出现Fluid以后的版本
最开始的PaddlePaddle还没有Fluid
如果你翻看PaddlePaddle以前的文档,就会发现PaddlePaddle已经有很多版本了,并且最初的版本是没有Fluid这个概念的:
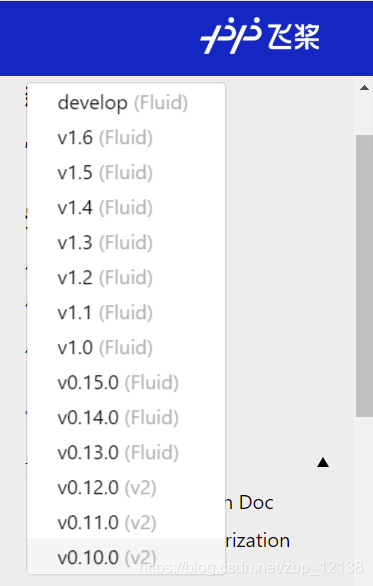
Fluid这个概念是在0.13.0才开始出现的,这里我简单讲讲Fluid出现前的PaddlePaddle是什么样的:
# network config
x = paddle.layer.data(name='x', type=paddle.data_type.dense_vector(2))
y_predict = paddle.layer.fc(input=x, size=1, act=paddle.activation.Linear())
y = paddle.layer.data(name='y', type=paddle.data_type.dense_vector(1))
cost = paddle.layer.mse_cost(input=y_predict, label=y)
定义一层全连接网络,输入x,输出y,拿网络输出的y(y_predict)和期望的y做比较,计算损失cost
再来看一下训练的代码:
# training
trainer.train(
reader=paddle.batch(
train_reader(), batch_size=1),
feeding=feeding,
event_handler=event_handler,
num_passes=100)
训练是通过调用trainer的train方法启动的
Fluid的出现让PaddlePaddle焕发生机
下面是对比图

官方给的区别是从有模型变为无模型,我理解的是,最大的改变就在于程序的编译过程里。
文档的原文是这么描述的:
When a Fluid application program runs, it generates a ProgramDesc protobuf message as an intermediate representation of itself. The C++ class Executor can run this protobuf message as an interpreter.
换句话说,Fluid能让PaddlePaddle的执行速度变的更快
静态图和动态图
PaddlePaddle引入动态图是在1.5之后,即从1.6开始支持动态图
因为静态图和动态图的内容较多,所以我将在下一篇文章内整理
2. Fluid的核心思想
上面的版本其实只是做了一个铺垫,现在使用PaddlePaddle都是需要用到Fluid
Fluid使用一种编译器式的执行流程,分为编译时和运行时两个部分,具体包括:编译器定义 Program ,创建Executor 运行 Program 。
Fluid内部执行流程
-
编译时,用户编写一段python程序,通过调用 Fluid 提供的算子,向一段 Program 中添加变量(Tensor)以及对变量的操作(Operators 或者 Layers)。用户只需要描述核心的前向计算,不需要关心反向计算、分布式下以及异构设备下如何计算。
-
原始的 Program 在平台内部转换为中间描述语言: ProgramDesc。
-
编译期最重要的一个功能模块是 Transpiler。Transpiler 接受一段 ProgramDesc ,输出一段变化后的 ProgramDesc ,作为后端 Executor 最终需要执行的 Fluid Program
-
后端 Executor 接受 Transpiler 输出的这段 Program ,依次执行其中的 Operator(可以类比为程序语言中的指令),在执行过程中会为 Operator 创建所需的输入输出并进行管理。
Executor与Program的设计思想
Program
用户完成网络定义后,一段 Fluid 程序中通常存在 2 段 Program:
-
fluid.default_startup_program:定义了创建模型参数,输入输出,以及模型中可学习参数的初始化等各种操作
default_startup_program 可以由框架自动生成,使用时无需显示地创建
如果调用修改了参数的默认初始化方式,框架会自动的将相关的修改加入default_startup_program -
fluid.default_main_program :定义了神经网络模型,前向反向计算,以及优化算法对网络中可学习参数的更新
使用Fluid的核心就是构建起 default_main_program
Programs and Blocks
Fluid 的 Program 的基本结构是一些嵌套 blocks,形式上类似一段 C++ 或 Java 程序。
blocks中包含:
- 本地变量的定义
- 一系列的operator
block的概念与通用程序一致,例如在下列这段C++代码中包含三个block:
int main(){ //block 0
int i = 0;
if (i<10){ //block 1
for (int j=0;j<10;j++){ //block 2
}
}
return 0;
}
类似的,在下列 Fluid 的 Program 包含3段block:
import paddle.fluid as fluid # block 0
limit = fluid.layers.fill_constant_batch_size_like(
input=label, dtype='int64', shape=[1], value=5.0)
cond = fluid.layers.less_than(x=label, y=limit)
ie = fluid.layers.IfElse(cond)
with ie.true_block(): # block 1
true_image = ie.input(image)
hidden = fluid.layers.fc(input=true_image, size=100, act='tanh')
prob = fluid.layers.fc(input=hidden, size=10, act='softmax')
ie.output(prob)
with ie.false_block(): # block 2
false_image = ie.input(image)
hidden = fluid.layers.fc(
input=false_image, size=200, act='tanh')
prob = fluid.layers.fc(input=hidden, size=10, act='softmax')
ie.output(prob)
prob = ie()
BlockDesc and ProgramDesc
用户描述的block与program信息在Fluid中以protobuf 格式保存,所有的protobub信息被定义在framework.proto中,在Fluid中被称为BlockDesc和ProgramDesc。ProgramDesc和BlockDesc的概念类似于一个抽象语法树。
BlockDesc中包含本地变量的定义vars,和一系列的operator(ops):
message BlockDesc {
required int32 parent = 1;
repeated VarDesc vars = 2;
repeated OpDesc ops = 3;
}
parent ID表示父块,因此block中的操作符可以引用本地定义的变量,也可以引用祖先块中定义的变量。
Program 中的每层 block 都被压平并存储在数组中。blocks ID是这个数组中块的索引:
message ProgramDesc {
repeated BlockDesc blocks = 1;
}
使用Blocks的Operator
上面的例子中,IfElseOp这个Operator包含了两个block——true分支和false分支。
下述OpDesc的定义过程描述了一个operator可以包含哪些属性:
message OpDesc {
AttrDesc attrs = 1;
...
}
属性可以是block的类型,实际上就是上面描述的block ID:
message AttrDesc {
required string name = 1;
enum AttrType {
INT = 1,
STRING = 2,
...
BLOCK = ...
}
required AttrType type = 2;
optional int32 block = 10; // when type == BLOCK
...
}
Executor
Executor 在运行时将接受一个ProgramDesc、一个block_id和一个Scope。ProgramDesc是block的列表,每一项包含block中所有参数和operator的protobuf定义;block_id指定入口块;Scope是所有变量实例的容器。
完整的编译执行的具体过程如下:
- Executor 为每一个block创建一个Scope,Block是可嵌套的,因此Scope也是可嵌套的
- 创建所有Scope中的变量
- 按顺序创建并执行所有operator
Executor的C++实现代码如下:
class Executor{
public:
void Run(const ProgramDesc& pdesc,
Scope* scope,
int block_id) {
auto& block = pdesc.Block(block_id);
//创建所有变量
for (auto& var : block.AllVars())
scope->Var(Var->Name());
}
//创建OP并按顺序执行
for (auto& op_desc : block.AllOps()){
auto op = CreateOp(*op_desc);
op->Run(*local_scope, place_);
}
}
};
创建Executor
Fluid中使用fluid.Executor(place)创建Executor,place属性由用户定义,代表程序将在哪里执行。
下例代码表示创建一个Executor,其运行场所在CPU内:
cpu=core.CPUPlace()
exe = fluid.Executor(cpu)
运行Executor
Fluid使用Executor.run来运行程序。定义中通过Feed映射获取数据,通过fetch_list获取结果:
x = numpy.random.random(size=(10, 1)).astype('float32')
outs = exe.run(
feed={'X': x},
fetch_list=[loss.name])
Fluid编程指南
Fluid核心使用概念
使用张量Tensor表示数据
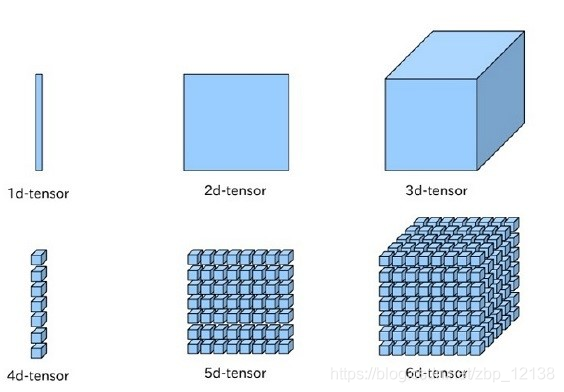
在神经网络中传递的数据都是Tensor,Tensor可以简单理解成一个多维数组,一般而言可以有任意多的维度。不同的Tensor可以具有自己的数据类型和形状,同一Tensor中每个元素的数据类型是一样的,Tensor的形状就是Tensor的维度。
下图是1~6维的张量Tensor:
在 Fluid 中存在三种特殊的 Tensor:
- 模型中的可学习参数
- 输入输出Tensor
- 常量 Tensor
模型中的可学习参数
模型中的可学习参数(包括网络权重、偏置等)生存期和整个训练任务一样长,会接受优化算法的更新,在 Fluid 中以 Variable 的子类 Parameter 表示。
在Fluid中可以通过fluid.layers.create_parameter来创建可学习参数:
w = fluid.layers.create_parameter(name="w",shape=[1],dtype='float32')
一般情况下,不需要自己来创建网络中的可学习参数,Fluid 为大部分常见的神经网络基本计算模块都提供了封装。以最简单的全连接模型为例,下面的代码片段会直接为全连接层创建连接权值(W)和偏置( bias )两个可学习参数,无需显式地调用 Parameter 相关接口来创建:
import paddle.fluid as fluid
y = fluid.layers.fc(input=x, size=128, bias_attr=True)
输入输出Tensor
整个神经网络的输入数据也是一个特殊的 Tensor,在这个 Tensor 中,一些维度的大小在定义模型时无法确定(通常包括:batch size,如果 mini-batch 之间数据可变,也会包括图片的宽度和高度等),在定义模型时需要占位。
Fluid 中使用 fluid.layers.data 来接收输入数据, fluid.layers.data 需要提供输入 Tensor 的形状信息,当遇到无法确定的维度时,相应维度指定为 None ,如下面的代码片段所示:
import paddle.fluid as fluid
#定义x的维度为[3,None],其中我们只能确定x的第一的维度为3,第二个维度未知,要在程序执行过程中才能确定
x = fluid.layers.data(name="x", shape=[3,None], dtype="int64")
#batch size无需显示指定,框架会自动补充第0维为batch size,并在运行时填充正确数值
a = fluid.layers.data(name="a",shape=[3,4],dtype='int64')
#若图片的宽度和高度在运行时可变,将宽度和高度定义为None。
#shape的三个维度含义分别是:channel、图片的宽度、图片的高度
b = fluid.layers.data(name="image",shape=[3,None,None],dtype="float32")
常量 Tensor
Fluid 通过 fluid.layers.fill_constant 来实现常量Tensor,用户可以指定Tensor的形状,数据类型和常量值。代码实现如下所示:
import paddle.fluid as fluid
data = fluid.layers.fill_constant(shape=[1], value=0, dtype='int64')
需要注意的是,上述定义的tensor并不具有值,它们仅表示将要执行的操作
数据传入
Fluid有特定的数据传入方式
需要使用 fluid.layers.data 配置数据输入层,并在 fluid.Executor 或fluid.ParallelExecutor 中,使用 executor.run(feed=…) 传入训练数据
使用Operator表示对数据的操作
在Fluid中,所有对数据的操作都由Operator表示。
为了便于用户使用,在Python端,Fluid中的Operator被一步封装入paddle.fluid.layers,paddle.fluid.nets 等模块。
这是因为一些常见的对Tensor的操作可能是由更多基础操作构成,为了提高使用的便利性,框架内部对基础 Operator 进行了一些封装,包括创建 Operator 依赖可学习参数,可学习参数的初始化细节等,减少用户重复开发的成本。
例如用户可以利用paddle.fluid.layers.elementwise_add()实现两个输入Tensor的加法运算:
#定义网络
import paddle.fluid as fluid
a = fluid.layers.data(name="a",shape=[1],dtype='float32')
b = fluid.layers.data(name="b",shape=[1],dtype='float32')
result = fluid.layers.elementwise_add(a,b)
#定义Exector
cpu = fluid.core.CPUPlace() #定义运算场所,这里选择在CPU下训练
exe = fluid.Executor(cpu) #创建执行器
exe.run(fluid.default_startup_program()) #网络参数初始化
#准备数据
import numpy
data_1 = int(1)
data_2 = int(2)
x = numpy.array([[data_1]])
y = numpy.array([[data_2]])
#执行计算
outs = exe.run(
feed={'a':x,'b':y},
fetch_list=[result.name])
#验证结果
print("%d+%d=%d"%(data_1,data_2,outs[0][0]))

如果想获取网络执行过程中的a,b的具体值,可以将希望查看的变量添加在fetch_list中:
#执行计算
outs = exe.run(
feed={'a':x,'b':y},
fetch_list=[a,b,result.name])
#查看输出结果
print(outs)

使用Program描述神经网络模型
开发者的所有 Operator 都将写入 Program ,在Fluid内部将自动转化为一种叫作 ProgramDesc 的描述语言,Program 的定义过程就像在写一段通用程序,有开发经验的用户在使用 Fluid 时,会很自然的将自己的知识迁移过来。
其中,Fluid通过提供顺序、分支和循环三种执行结构的支持,让用户可以通过组合描述任意复杂的模型。
- 顺序执行:
用户可以使用顺序执行的方式搭建网络:
x = fluid.layers.data(name='x',shape=[13], dtype='float32')
y_predict = fluid.layers.fc(input=x, size=1, act=None)
y = fluid.layers.data(name='y', shape=[1], dtype='float32')
cost = fluid.layers.square_error_cost(input=y_predict, label=y)
- 条件分支——switch、if else:
Fluid 中有 switch 和 if-else 类来实现条件选择,用户可以使用这一执行结构在学习率调节器中调整学习率或其他希望的操作:
lr = fluid.layers.tensor.create_global_var(
shape=[1],
value=0.0,
dtype='float32',
persistable=True,
name="learning_rate")
one_var = fluid.layers.fill_constant(
shape=[1], dtype='float32', value=1.0)
two_var = fluid.layers.fill_constant(
shape=[1], dtype='float32', value=2.0)
with fluid.layers.control_flow.Switch() as switch:
with switch.case(global_step == zero_var):
fluid.layers.tensor.assign(input=one_var, output=lr)
with switch.default():
fluid.layers.tensor.assign(input=two_var, output=lr)
使用Executor执行Program
Fluid的设计思想类似于高级编程语言C++和JAVA等。程序的执行过程被分为编译和执行两个阶段。
用户完成对 Program 的定义后,Executor 接受这段 Program 并转化为C++后端真正可执行的 FluidProgram,这一自动完成的过程叫做编译。
编译过后需要 Executor 来执行这段编译好的 FluidProgram。
例如上文实现的加法运算,当构建好 Program 后,需要创建 Executor,进行初始化 Program 和训练 Program:
#定义Exector
cpu = fluid.core.CPUPlace() #定义运算场所,这里选择在CPU下训练
exe = fluid.Executor(cpu) #创建执行器
exe.run(fluid.default_startup_program()) #用来进行初始化的program
#训练Program,开始计算
#feed以字典的形式定义了数据传入网络的顺序
#fetch_list定义了网络的输出
outs = exe.run(
feed={'a':x,'b':y},
fetch_list=[result.name])
3. 开发机器学习模型的全流程
问题描述
给定一组数据 <X,Y>,求解出函数 f,使得 y=f(x),其中X,Y均为一维张量。最终网络可以依据输入x,准确预测出 。
定义数据
假设输入数据X=[1 2 3 4],Y=[2,4,6,8],在网络中定义:
#定义X数值
train_data=numpy.array([[1.0],[2.0],[3.0],[4.0]]).astype('float32')
#定义期望预测的真实值y_true
y_true = numpy.array([[2.0],[4.0],[6.0],[8.0]]).astype('float32')
搭建网络(定义前向计算逻辑)
接下来需要定义预测值与输入的关系,使用一个简单的线性回归函数进行预测:
# 定义输入数据类型
x = fluid.data(name="x", shape=[None, 1], dtype='float32')
y = fluid.data(name="y", shape=[None, 1], dtype='float32')
# 搭建全连接网络
y_predict = fluid.layers.fc(input=x, size=1, act=None)
这样的网络就可以进行预测了,但是输出结果只是一组随机数,离预期结果相差甚远:
# 加载库
import paddle.fluid as fluid
import numpy
# 定义输入数据
train_data=numpy.array([[1.0],[2.0],[3.0],[4.0]]).astype('float32')
y_true = numpy.array([[2.0],[4.0],[6.0],[8.0]]).astype('float32')
# 组建网络
x = fluid.data(name="x",shape=[None, 1],dtype='float32')
y = fluid.data(name="y",shape=[None, 1],dtype='float32')
y_predict = fluid.layers.fc(input=x,size=1,act=None)
# 网络参数初始化
cpu = fluid.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
outs = exe.run(
feed={'x':train_data, 'y':y_true},
fetch_list=[y_predict])
# 输出训练结果
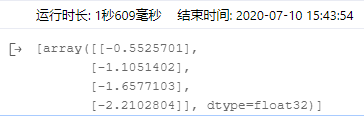
print(outs)
输出结果:
添加损失函数
完成模型搭建后,如何评估预测结果的好坏呢?
我们通常在设计的网络中添加损失函数,以计算真实值与预测值的差。
在本例中,损失函数采用均方差函数:
# 定义损失函数
cost = fluid.layers.square_error_cost(input=y_predict,label=y)
avg_cost = fluid.layers.mean(cost)

可以看到cost现在挺大的,说明还有下降的空间
网络优化
确定损失函数后,可以通过前向计算得到损失值,然后通过链式求导法则得到参数的梯度值。
获取梯度值后需要更新参数,最简单的算法是随机梯度下降法:w=w−η⋅g,由fluid.optimizer.SGD实现:
# 选择优化方法
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.01)
sgd_optimizer.minimize(avg_cost)
让我们的网络训练100次,查看结果:
# 加载库
import paddle.fluid as fluid
import numpy
# 定义输入数据
train_data=numpy.array([[1.0],[2.0],[3.0],[4.0]]).astype('float32')
y_true = numpy.array([[2.0],[4.0],[6.0],[8.0]]).astype('float32')
# 组建网络
x = fluid.data(name="x",shape=[None, 1],dtype='float32')
y = fluid.data(name="y",shape=[None, 1],dtype='float32')
y_predict = fluid.layers.fc(input=x,size=1,act=None)
# 定义损失函数
cost = fluid.layers.square_error_cost(input=y_predict,label=y)
avg_cost = fluid.layers.mean(cost)
# 选择优化方法
sgd_optimizer = fluid.optimizer.SGD(learning_rate=0.01)
sgd_optimizer.minimize(avg_cost)
# 网络参数初始化
cpu = fluid.CPUPlace()
exe = fluid.Executor(cpu)
exe.run(fluid.default_startup_program())
# 开始训练,迭代100次
for i in range(100):
outs = exe.run(
feed={'x':train_data, 'y':y_true},
fetch_list=[y_predict, avg_cost])
# 输出训练结果
print(outs)
输出结果:

可以看到100次迭代后,预测值已经非常接近真实值了,损失值也下降到了0.01。
该项目我已在AI Studio公开,欢迎大家交流学习:
https://aistudio.baidu.com/aistudio/projectdetail/622255