我们先看下RIV的编码方式。关于RIV的编码过程,已经在《LTE-TDD随机接入过程(4)-RIV的解析和Preamble资源的选择》中有详细的解释,具体公式见下面的图1。其中,L_CRBs表示分配的RB的长度,N_UL_RB表示该带宽总的RB个数,RB_START表示分配RB的起始位置,编码生成的RIV就是UL_GRANT(由MSG2或DCI0携带)中的具体数值。
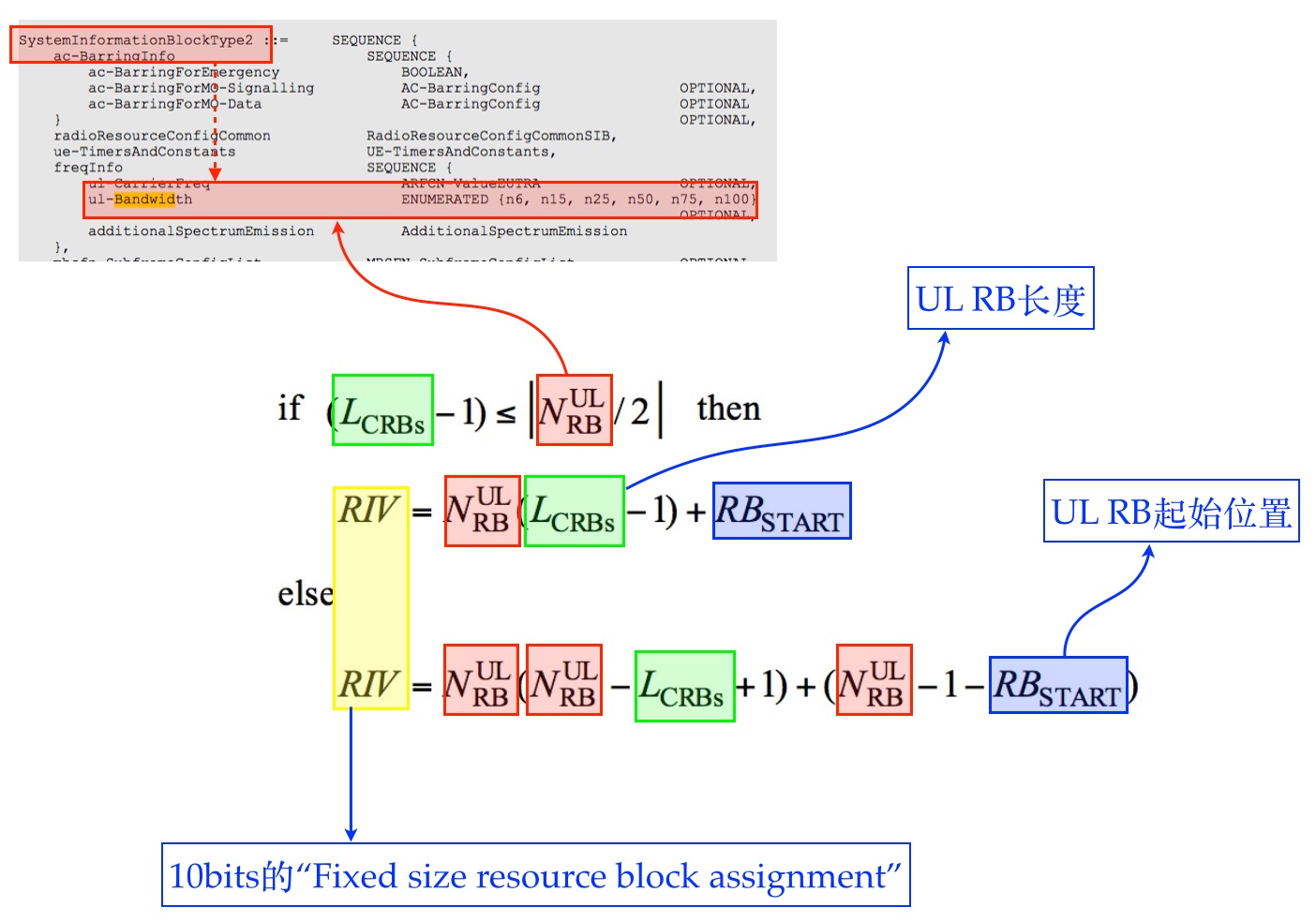
图1的这种编码方式是2007年由NEC和DoCoMo联合提出来的,采用的是基于三角形二叉树(Tree Based)的高效编码方式,这个数学公式的图形表达方式如图2所示。这种二叉树组成的形状是等边三角形,每个边的节点个数相同,均等于叶子节点个数N,N为该带宽RB总个数。根据这种特性,可以得到这种三角形二叉树占用的总节点个数为N×(N+1)/2,二叉树中的每个节点对应的值就是一个RIV值,且只需要ceil(log2(N×(N+1)/2))bit就可以编码RIV值。
根据上面的解释,现在我们可以知道图2显示的实际就是1.4MHz带宽时的树形资源分配图。在1.4M带宽时,RB的总个数N=6,二叉树占用的节点个数=N×(N+1)/2=21,意味着编码生成的RIV值不会超过20。比如当前eNB正在给3个UE分配资源,其中为UE1分配的是绿色的2个RB,RB-ID分别是{RB0,RB1},为UE2分配的是红色的3个RB,RB-ID分别是{RB2,RB3,RB4},为UE3分配的是蓝色的1个RB,RB-ID是{RB5}。eNB给每个UE配置的RIV值与RB集合组成1个等边三角形,所以这3个UE的RIV值分别是6(与RB0/1组成一个三角形)、14(与RB2/3/4组成一个三角形)、5(只有1个节点即为本身)。根据上面图1的公式,分别代入三个UE的RB起始位置和长度,也同样可以计算得到三个RIV值分别是6、14和5。

有的朋友可能会发现图2中的节点11、16、17这三个并不是顺序递增的,那是怎么得到的呢?实际过程如图3所示,每个节点号按行从左到右依次递增。行数i=1时,节点号从0增加到N-1;行数i=2时,节点号从N增加到2*(N-1),超过等边三角形范围的节点号用红色的三角框圈住,比如11号节点。然后再继续其它行数的处理,依次类推。当处理完行数i=4时,完成节点18、19和20的填写,此时会发现三个节点11、16、17是没有写到三角形二叉树中的,但却在二叉树的右侧形成一个倒三角。将这三个节点组成的倒三角反转180度移入整个二叉树的最上方,就可以得到叶子节点树为N的三角形二叉树。

我们再回头看下图1中的数学公式就会发现,这个公式有两个不同的分支:if分支对应RB长度小于或等于4的RIV计算方式(以N=6为例),else分支对应长度为5和6的RIV计算方式。而观察图3的二叉树生成过程,也会发现两个不同的组成部分:第一个组成部分是前4行的RIV值按行顺序递增,第二个组成部分是第5行和第6行的倒三角反转移入。数学公式和图形的结果是相互印证的:对于顺序按行递增的,可以得到if分支的公式;对于倒三角移入的,则可以得到else分支的公式。
至此,RIV的编码过程已经详细介绍完,下面继续介绍解码的部分。
从RIV解码RB起始位置RB_START和RB长度L_CRBs,第一种也是比较笨的方法是通过查表得到。这种方式是先通过图1编码的方式得到所有的RIV值,然后反向查RIV表,得到对应的RB起始位置和RB长度。这种方法虽然没有问题,但效率是比较低的,下面介绍第二种方法。假定P表示RB的长度,O表示RB的起始位置,N表示带宽RB数,x表示RIV值,则记:
a = floor(x / N)+1
b = x mod N
那么存在:
if (a + b > N)
{
P = N + 2 - a
O = N - 1 - b
}
else
{
P = a
O = b
}
还是以图2为例,比如当前的x=RIV=14,N=6,那么a=3,b=2。因(a+b)=5<6,所以执行else分支,故RB长度P=a=3,RB起始位置O=b=2。
再比如当前的x=RIV=17,N=6,那么a=3,b=5。因(a+b)=8>6,所以执行if分支,故RB长度P=N+2-a=5,RB起始位置O=N-1-b=0,即对应RB集合为{RB0,RB1,RB2,RB3,RB4},符合图2中的二叉树结构。