一、什么是量化?为什么要量化?
在深度神经网络模型应用中,量化是削减模型大小的一种常用方法。实际上就是把高位宽表示的权值和激活值用更低位宽来表示。为什么要削减模型,是因为硬件平台的自身性能不理想,如计算力低,内存、电量消耗等限制,导致模型推断速度慢、功耗高。 而定点运算指令比浮点运算指令在单位时间内能处理更多数据,同时,量化后的模型可以减少存储空间。当然,也可以将量化后的模型部署在高效的定制化计算平台上以达到更快的推断速度。
二、有哪些量化方法?怎样量化?
具体的量化方案有以下几种:
1.Uniform Affine Quantizer(均匀映射量化)
也叫非对称量化
下图是一个uint8非对称量化的映射过程:

首先,量化前要计算量化因子,包括步长和零点两个量化参数。量化因子就是用来保证浮点区间内的变量都能无一缺漏的映射到要量化bit数的取值区间内。其中,步长和零点的计算公式如下:

这里要重点说下零点z,也叫做偏移,为何这里需要零点?
实际上,浮点型的0会映射到零点,这个零点是一个整型数,用来确保0没有量化误差。具体就是,0有特殊意义,比如padding时,0值也是参与计算的,浮点型的0进行8bit量化后还是0就不对了,所以加上这个零点后,浮点型0就会被映射到0-255这个区间内的一个数,这样的量化就更精确。就相当于让映射后区间整体偏移,浮点最小值对应0。
计算完量化因子,再从浮点区间任取一值的量化过程:

即浮点值除以步长,就近取整,加上零点。再做clamp使量化的区间为(0,Nlevels-1),对于8bit量化,其中Nlevels就是2^8 =256。
注:对于单边分布,范围(Xmin,Xmax)需要进一步放宽去包含0点。例如,范围为(2.1, 3.5)的浮点型变量将会放宽为(0, 3.5),然后再量化。故,这种方式对于极端的单边分布会产生精度损失。
逆量化:

2.Uniform symmetric quantizer(对称量化)
对称量化是映射量化的简化版本。
下图是一个int8对称量化的映射过程:


首先,根据浮点区间的最大最小值计算量化因子(量化步长),然后在该范围内任选一个浮点型变量,利用给出的公式把它映射到8bit区间,即除以量化因子,就近取整,再根据有符号或无符号做一个clamp(截断),确定量化后的区间,当量化为8bit时,Nlevels就是2^8 =256,如果是4bit量化就是2 ^4=16。最后所有的浮点数都被映射在(-127,128)这个区间内,浮点数的最大最小值分别对应128、-127,将零点约束到0的位置。
文中提到:
若想更快的实现SIMD(SingleInstruction Multiple Data 单指令流多数据流),可以进一步约束权重的范围。这时,截断运算可以简化为:

对称量化的逆量化为:

更多对称量化内容查看这篇论文:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
以上两个量化方案是比较常用的。
3.Stochastic quantizer(随机量化)
随机量化方法加了一个噪声:

期望情况下,随机量化方法通过对范围外的值进行饱和(既clamp),可以降低浮点型权重的通量。因此,这种方法比较适用于计算梯度。【这个量化不是很懂,后面再补充】
三、 在后向传播中的训练模拟量化建模
还是先放一张非对称量化的图以及模拟量化过程公式:


该模拟量化操作是在训练时就进行量化的(训练时量化后面会说),操作实际包括一个量化再紧跟一个逆量化。具体的,就是在前向传播的时候(forward)模拟了量化的这个过程,在forward时首先会把权值和激活值量化到8bit再反量化回有误差的32bit,整体训练还是浮点,反向传播(backward)的时候求得的梯度是模拟量化之后权值的梯度,用这个梯度去更新量化前的权值。
如上图,选择从左到右数第4个点进行量化,量化后的值为253,然后再进行反量化,就得到它正对着的第5个点,即误差点,实际上用的这个点做的前向推理的,用误差点求梯度去更新原始点,simquant就是量化+反量化。

由于模拟量化方程的导数几乎在各个位置均为0(我的理解就是连续的浮点数量化映射成了离散的点),故在反向传播求梯度时无法求得,所以需要在反向传播中构建一个近似量化。在实际工程中一种效果比较好的近似方法是将量化指定为下面公式的形式,这样可以方便定义导数。


上图是: 模拟量化器(顶部),显示量化输出值。 用于导数计算的近似(底部)。
而反向传播可以建模为“直通估计器”,即:

其中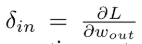
是关于模拟的量化输出的loss的反向传播误差。
具体内容查看这篇论文:Binaryconnect: Training deep neural
networks with binary weights during propagations
四、量化参数如何求得
量化参数可以利用一些标准来决定。前文中的量化参数是根据浮点值的最大最小计算出,这种计算量化因子实际是有问题的,这种属于不饱和的线性量化,会导致精度损失较大。于是就有了一种TensorRT的后量化算法,它通过最小化原始数据分布和量化后数据分布之间的KL散度来决定步长尺度。
具体的:
该算法对激活值进行饱和量化,即选择合适的阈值;对权值还是非饱和量化。
什么是饱和?非饱和?
看下面这张图:

首先左边的图,上面是未量化的浮点区间,下面是要映射的int8区间。可以看到负值取值更大一点,就假设取这个值作为阈值,而正数最大值这边可能只有负值这边大小的一半,所以这个点量化后可能只映射到0-127的一半处,假设是64,所以量化后64-127这个区间显然就被浪费了;再假如负数最大值处是一个噪声点,只占激活值的一小部分甚至一个,而正值这边的值占比大的话,那么量化之后这些有效值就会压缩到一个很小的区间,然后精度损失就会比较大。
而TensorRT的后量化算法是找到一个合适的阈值,如右图,把超出范围的噪声点的值都设为[T],然后量化之后,值会非常均匀的分布在(-127-127)这个区间。故左图代表非饱和,右图为饱和。
接下来用一段代码直观感受一下:
import numpy as np
def quant(x,s):
return[int(e) for e in np.clip(np.round(x*s),-128,127)]
arr=np.array([-0.75,-0.5,-0.1,0.1,0.2,0.5,1])
scale=127/np.max(np.abs(arr))
print("量化前:[%s]"%",".join([str(e) for e in arr]))
print("量化后:[%s]"%",".join([str(e) for e in quant(arr,scale)]))
人为给定一组数,假设是激活输出统计的值,按照量化的步骤,首先求得量化因子(根据区间最大值),可以看到该组数据的最大值是1,然后打印量化前后的值。
输出:

可以看到,量化前后一一对应的,这种量化精度几乎没有损失。
-------------------------------------------美丽分割线-----------------------------------------
然后这段代码,是把区间最大值换成了100,同样是用区间最大值来计算量化因子,打印量化前后的值。
arr=np.array([-0.75,-0.5,-0.1,0.1,0.2,0.5,100])
scale=127/np.max(np.abs(arr))
print("量化前:[%s]"%",".join([str(e) for e in arr]))
print("量化后:[%s]"%",".join([str(e) for e in quant(arr,scale)]))
输出:

而选取100作为量化因子的计算,可以很明显的看到,100的确映射到了127,但是整个量化后的区间都更偏向右,最左边的值的映射与-127相差很远,并且中间的值被压缩映射成了相同的0,因此这种选择精度损失非常大。
-------------------------------------------美丽分割线-----------------------------------------
最后一段代码是TensorRT算法思想,虽然数据里有一个超大值100的噪声点,但是不用它作为量化因子,而是选择一个较为合适的值如0.75,打印量化前后的值。
scale=127/0.75
print("量化前:[%s]"%",".join([str(e) for e in arr]))
print("量化后:[%s]"%",".join([str(e) for e in quant(arr,scale)]))
输出:

而基于TensorRT思想的结果,就更加合理,精度损失很小。
-------------------------------------------美丽分割线-----------------------------------------
在本文中,对于量化参数的计算采用一些更简单的方法。
权重:使用实际的最大和最小值来决定量化参数。
激活输出:使用跨批(batches)的最大和最小值的滑动平均值来决定量化参数。
先训练后量化的方法:可以通过仔细地选择量化参数来提高量化模型的精度。
五、量化的粒度
逐层量化:指定一个量化器(由尺度∆和零点z定义)对张量进行量化。如果想让精度进一步提升,可以采用对张量的每个卷积核都使用对应的量化器。
逐通道量化:对每个卷积核有不同的量化器。
对于激活输出我们不考虑逐通道量化,因为这会使卷积操作和矩阵乘操作中的内积计算变得复杂。“逐层量化”和“逐通道量化”都支持高效的点乘操作和卷积实现,因为这两种量化方式中量化参数在每个卷积核中都是固定的常量。
未完待续。。。。
虽然一下午只写了一点点,但文中大部分是自己理解总结的,可能会有纰漏。@小宋是呢
https://blog.csdn.net/xiaosongshine
参考:
https://blog.csdn.net/wc996789331/article/details/90601123
https://www.bilibili.com/video/BV1cZ4y1u7T5/