Java当中的集合框架介绍
个人先来谈一下为什么有集合,用一个东西之前先要知道它能干什么,之前学了数组,用数组就可以存啊,为什么要用集合。那我我来说一下我个人观点,首先数组只能储存基本的数据类型,还有数组长度固定,很难去动态使用,还有如果有大量的对象,数组就不能存了,综合这些东西,我们知道,只有使用集合,集合的大小可以动态改变的,还有可以存储对象,种种来说我们使用集合的概率就很高了。
集合有分为两大类:单列集合双列集合
一、单列集合
先来看一张图:
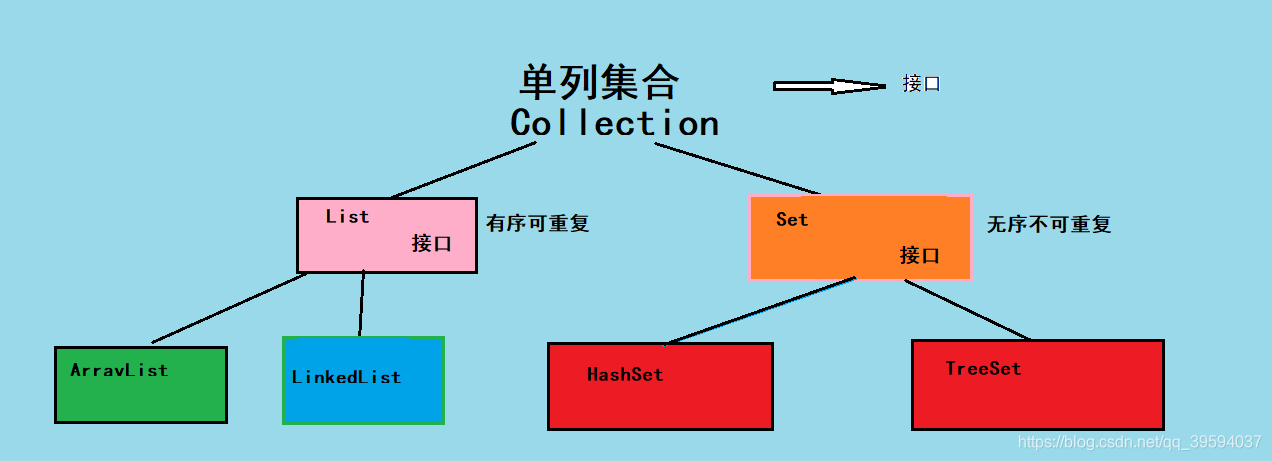
Collection是所有单列集合的父接口,因此在Collection中定义了单列集合(List和Set)通用的一些方法,这些方法可用于操作所有的单列集合。方法如下:
public boolean add(E e): 把给定的对象添加到当前集合中 。public void clear():清空集合中所有的元素。public boolean remove(E e): 把给定的对象在当前集合中删除。public boolean contains(E e): 判断当前集合中是否包含给定的对象。public boolean isEmpty(): 判断当前集合是否为空。public int size(): 返回集合中元素的个数。public Object[] toArray(): 把集合中的元素,存储到数组中。
-
List集合
先来看一下List集合,这是一个接口,是Collection下面的一个子接口,里面带有索引,类似于数组,所以查找很快,增删可能就慢了,下面是里面的一些方法:
-
public void add(int index, E element): 将指定的元素,添加到该集合中的指定位置上。 -
public E get(int index):返回集合中指定位置的元素。 -
public E remove(int index): 移除列表中指定位置的元素, 返回的是被移除的元素。 -
public E set(int index, E element):用指定元素替换集合中指定位置的元素,返回值的更新前的元素。List接口下还有两个ArrayList和LinkedList
扫描二维码关注公众号,回复: 11426835 查看本文章
java.util.ArrayList集合数据存储的结构是数组结构。元素增删慢,查找快,由于日常开发中使用最多的功能为查询数据、遍历数据,所以ArrayList是最常用的集合。java.util.LinkedList集合数据存储的结构是链表结构。方便元素添加、删除的集合。
-
-
Set集合
Set中有很多子类,主要看HashSet和LinkedHashSet这两个实现类
-
HashSet:
java.util.HashSet是Set接口的一个实现类,它所存储的元素是不可重复的,并且元素都是无序的(即存取顺序不一致)。java.util.HashSet底层的实现其实是一个java.util.HashMap支持,由于我们暂时还未学习,先做了解。HashSet是根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。保证元素唯一性的方式依赖于:hashCode与equals方法。在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的
总而言之,JDK1.8引入红黑树大程度优化了HashMap的性能,那么对于我们来讲保证HashSet集合元素的唯一,其实就是根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
-
-
LinkedHashSet:
我们知道HashSet保证元素唯一,可是元素存放进去是没有顺序的,那么我们要保证有序,怎么办呢?
在HashSet下面有一个子类
java.util.LinkedHashSet,它是链表和哈希表组合的一个数据存储结构。
二、Map集合(双列集合)
Map集合,这个是我们集合框架中的双列集合,为啥是双列的,是因为存储的数据都是key-value的形式,举个例子:我生活中的每一个都有一个身份证ID这种一一对应的就是映射。Map下面实现的常用的类有HashMap类。
Map中常用的方法如下:
-
public V put(K key, V value): 把指定的键与指定的值添加到Map集合中。 -
public V remove(Object key): 把指定的键 所对应的键值对元素 在Map集合中删除,返回被删除元素的值。 -
public V get(Object key)根据指定的键,在Map集合中获取对应的值。 -
boolean containsKey(Object key)判断集合中是否包含指定的键。 -
public Set<K> keySet(): 获取Map集合中所有的键,存储到Set集合中。 -
public Set<Map.Entry<K,V>> entrySet(): 获取到Map集合中所有的键值对对象的集合(Set集合)。Map集合中如何遍历找值呢?主要用keyset()方法来获取key,然后用get()方法来获取键值
public class CollectionTest { public static void main(String[] args) { Map<String, Integer> hm = new HashMap<>(); hm.put("yi",11); hm.put("er",18); hm.put("sa",22); Set<String> keySet = hm.keySet(); for (String s : keySet) { System.out.println(s+"--->"+hm.get(s)); } } } 输出结果为: yi--->11 er--->18 sa--->22遍历其实还有一种方法,这种方法涉及一个知识点,就是entry,我们知道Map保存的是一对对键值对,那么这些键值对的对象就是entry,然后我通过entryKey()方法来获取键值对的对象,再通过getkey和getvalue来实现获取对应的键和键值,入下:
public class CollectionTest { public static void main(String[] args) { Map<String, Integer> hm = new HashMap<>(); hm.put("yi",11); hm.put("er",18); hm.put("sa",22); Set<Map.Entry<String, Integer>> entries = hm.entrySet(); for (Map.Entry<String, Integer> entry : entries) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println(key+"---->"+value); } } } 输出结果同上-
HashMap
保证存储的键值对唯一,查询速度很快,存进去的是无序的
-
LinkedHashMap
这是HashMap的一个子类,保证了有序性
-
-