示意图
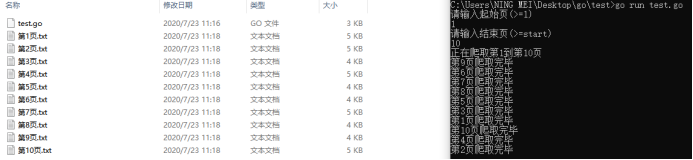

来到我们的main函数,首先是获取起始页和结束页,由用fmt.Scan来打印用户输入进来起始值和结束值
看toWork函数,打印要爬取的页数,创建page通并传入实现并发

效果图

url的格式的xiaohua_1.html、xiaohua_2.html、xiaohua_3.html以此类推
使用传递进来的i值并转换格式拼接进url中,HttpGet获取url中的源码

使用正则匹配,<a href=”https://www.xxx.com/content_(.*?).html” _target=”_blank”>
来匹配连接,后面打开拼接剩余的url,以防止其他ulr参杂进来
SpiderJokePage打开匹配到的url,SaveJokeFile保存标题和内容

获取源码返回result

获取当前目录,并以页数保存txt文件

package main
import (
"fmt"
"io"
"net/http"
"os"
"regexp"
"strconv"
"strings"
)
func HttpGet(url string)(result string,err error){
rep ,err1 := http.Get(url)
if err1 != nil{
err = err1
return
}
defer rep.Body.Close()
buf := make([]byte,4096)
for {
n,err2 := rep.Body.Read(buf)
if n==0 {
break
}
if err2!=nil && err2!=io.EOF{
err =err2
return
}
result += string(buf[:n])
}
return
}
func SpiderJokePage(url string) (title,content string,err error){
result , err := HttpGet(url)
if err!=nil{
fmt.Println("HttpGet err:",err)
return
}
ret1 := regexp.MustCompile(`<h1>(?s:(.*?))</h1>`)
alls := ret1.FindAllStringSubmatch(result,1)
for _,tmpTitle := range alls{
title = tmpTitle[1]
title = strings.Replace(title,"\t","",-1)
break
}
ret2 := regexp.MustCompile(`<div class="content-txt pt10">(?s:(.*?)[^<img])<a id="prev" href=`)
allss := ret2.FindAllStringSubmatch(result,1)
for _,tmpConten := range allss{
content = tmpConten[1]
content = strings.Replace(content,"\n","",-1)
content = strings.Replace(content,"\t","",-1)
content = strings.Replace(content," ","",-1)
break
}
return
}
func SpderPage(index int,page chan int){
url := "https://www.xxx.com/xiaohua_"+strconv.Itoa(index)+".html"
result , err := HttpGet(url)
if err!=nil{
fmt.Println("HttpGet err:",err)
return
}
ret := regexp.MustCompile(`<a href="https://www.xxx.com/content_(.*?).html" target="_blank">`)
alls := ret.FindAllStringSubmatch(result,-1)
fileTitle := make([]string,0)
filecontent := make([]string,0)
for _,jokeurl := range alls{
title,content,err := SpiderJokePage("https://www.xxx.com/content_"+jokeurl[1]+".html")
if err != nil{
fmt.Println("SpiderJokePage err:",err)
continue
}
/*
fmt.Println("title: ",title)
fmt.Println("content: ",content)
*/
fileTitle = append(fileTitle,title)
filecontent = append(filecontent,content)
}
SaveJokeFile(index,fileTitle,filecontent)
page <- index
}
func SaveJokeFile(index int,fileTitle,filecontent []string){
strpath,_:= os.Getwd()
path := strpath+"/第"+strconv.Itoa(index)+"页.txt"
f,err := os.Create(path)
if err !=nil{
fmt.Printf("Http get :",err)
}
defer f.Close()
n := len(fileTitle)
for i:=0;i<n;i++{
f.WriteString(fileTitle[i]+"\n"+filecontent[i]+"\n")
f.WriteString("------------分割线--------------\n")
}
}
func toWork(start int,end int)(){
fmt.Printf("正在爬取第%d到第%d页\n",start,end)
page := make(chan int)
for i:=start;i<=end;i++{
go SpderPage(i,page)
}
for i:=start;i<=end;i++{
fmt.Printf("第%d页爬取完毕\n",<-page)
}
}
func main(){
var start,end int
fmt.Println("请输入起始页(>=1)")
fmt.Scan(&start)
fmt.Println("请输入结束页(>=start)")
fmt.Scan(&end)
toWork(start,end)
}