在前面一篇文章,我们介绍了如何摘取页面字段,通过正则进行匹配符合要求的字段。如果感觉有点困难,不能立马理解,没有关系。把字符串摘取放到第一篇,是因为自动化测试脚本,经常要利用字符串操作,字符串切割,查找,匹配等手段,得到新的字符串或字符串数组,然后根据新得到的字符串进行判断用例是否通过。
本篇介绍如何通过元素节点信息ID来定位该元素,使用id来定位元素虽然效率要高于XPath,但是实际测试测项目,能直接通过id定位的元素还是比较少,以下来举例百度首页搜索输入框的id定位。
脚本如下:
# coding=utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("https://www.baidu.com") try: driver.find_element_by_id("kw") print ('test pass: ID found') except Exception as e: print ("Exception found", format(e)) driver.quit()
这里,我们通过try except语句块来进行测试断言,这个在实际自动化测试脚本开发中,经常要用到处理异常。本文,我们学习了可以利用find_element_by_id()方法来定位网页元素对象。
上文介绍了如何通过元素的id值来定位web元素,下文介绍如何通过tag name来定位元素。个人认为,通过tag name来定位还是有很大缺陷,定位不够精确。主要是tag name有很多重复的,造成了选择tag name来定位页面元素不准确,所以使用这个方法定位web元素的机会很少。
什么是tag name? 还是以百度首页搜索输入框,在火狐浏览器,右键,通过firepath,检查元素,看下图:
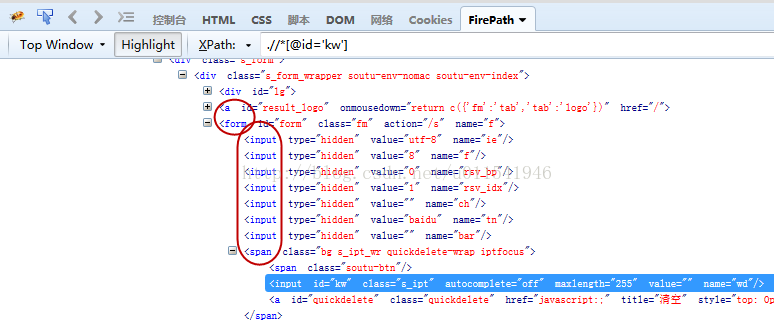
上面图片中红色圈选区域的标签名称都是tag name;实际上我们目标元素是输入框,应该是input这个tag name,在图中蓝色高亮区域。但是如果只是通过input这个tag name来定位,发现上面有很多input的选项。所以我们扩大节点的参照选择,我们选择上面这个form来作为我们tag name。(软件测试交流:1140267353,还会有同行一起技术交流,同时还有海量免费学习资料)
看看如何写定位form这个元素的脚本:
# coding=utf-8 from selenium import webdriver driver = webdriver.Chrome() driver.maximize_window() driver.implicitly_wait(6) driver.get("https://www.baidu.com") try: driver.find_element_by_tag_name("form") print ('test pass: tag name found') except Exception as e: print ("Exception found", format(e)) driver.quit()
测试结果:
test pass: tag name found
总结:本文介绍了webdriver 八大定位元素方法中
driver.find_element_by_tag_name("form") # form是tag name
从实际项目中自动化脚本开发来看,使用这个方法定位元素的机会比较少,知道有这么一种方法就好了。
上一篇 Python+Selenium练习篇之1-摘取网页上全部邮箱
下一篇 Python+Selenium练习篇之3-利用link text/partial link text定位元素
以上仅供参考和借鉴,希望对你有所帮助!
点个关注不迷路
小枫文章整理不易,欢迎各位朋友点赞关注!