你还在为找不到心仪的offer发愁吗?还在为面试担心吗?和我一起,提起剑来,攻克面试的种种难关!直指心仪offer!!!

**题目三:输入一个单链表的头结点,从尾到头打印出来每个节点的值。
分析:
拿到这个题,首先要明白单链表从头结点开始,只能依次访问下一个节点,既只能头从到尾访问。但是这道题却是让从 尾到头打印。那有人就想了。可以从头到尾依次遍历到最后一个节点,打印出来。然后再从头到尾访问至倒数第二个节点,在打印出来,以此类推。咳咳,怎么说呢?同学,回家种地吧。那可能更适合你……

好了,言归正传。我们发现,这个题的实质就是,先访问的头结点最后一个被打印。而最后一个被访问的尾结点却第一个被打印。等等……怎么 这么熟悉?这不是典型的 “后进先出” 嘛 。什么?栈啊!!!

其实说到 “后进先出” 还有一种结构也很常用——递归。说到递归大家可能第一印象就是代码非常简洁。可能就是搞定offer的杀手锏了。稳住,先别急。其实这个也有缺陷。咱们等会再说。还是先上代码吧:
#include<iostream>
#include<assert.h>
#include<stdlib.h>
using namespace std;
typedef struct listnode
{
int value;
struct listnode *next;
}listnode;
typedef listnode* list;
//为了观察结果,我把插入也简单实现一下
void listpush( list * p)
{
*p = (listnode *)malloc(sizeof(listnode));
assert(*p != NULL);
(*p)->value = 1;
(*p)->next = NULL;
for (int i = 2; i <= 10; i++)
{
listnode *s = (listnode *)malloc(sizeof(listnode));
assert(s != NULL);
s->value =i;
s->next = (*p);
(*p) = s;
}
}
//从尾到头打印 初始值 10 9 8 7 6 5 4 3 2 1
void rprint_list(listnode *p)
{
if (p != nullptr)
{
if (p->next!= nullptr)
{
rprint_list(p->next);
}
cout << p->value;
}
}
int main()
{
list ls;
listpush(&ls);
list * p = &ls;
rprint_list(*p);
cout << endl;
return 0;
}
运行结果(初始值 10 9 8 7 6 5 4 3 2 1):
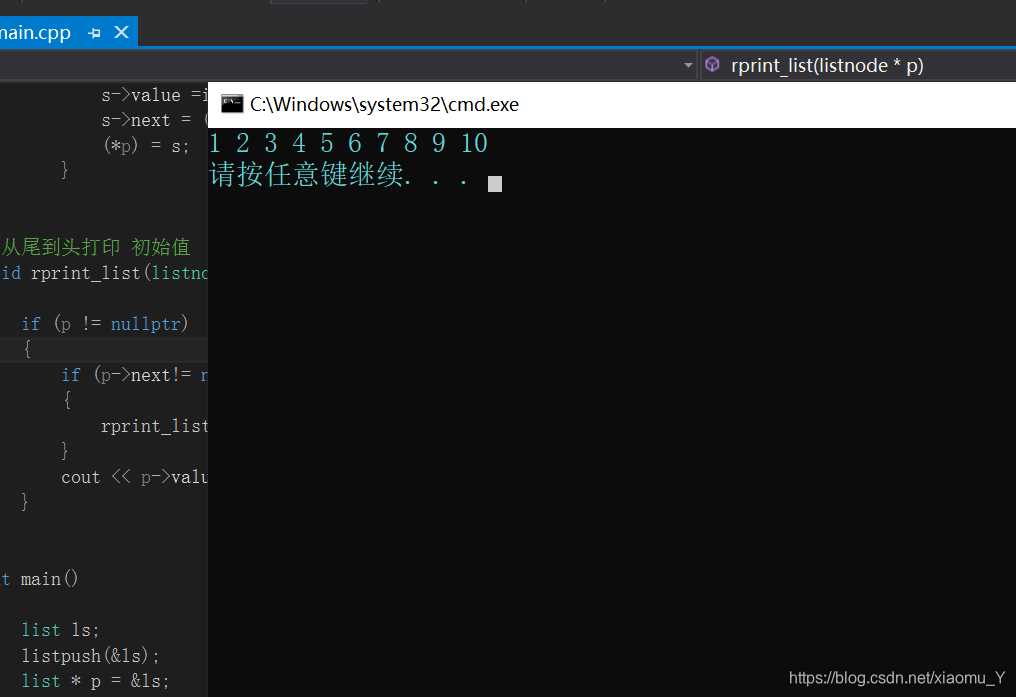
这个代码的从尾到头打印函数部分可以说是很简洁了:
//从尾到头打印 初始值 10 9 8 7 6 5 4 3 2 1
void rprint_list(listnode *p)
{
if (p != nullptr)
{
if (p->next!= nullptr)
{
rprint_list(p->next);
}
cout << p->value;
}
}
可是当链表长度非常大的时候,会导致函数调用层级太深,可能会导致函数调用栈溢出。所以我们在来看另一种基于栈的实现方法:
//从尾到头打印 初始值 10 9 8 7 6 5 4 3 2 1
void rprint_list(listnode *p)
{
stack<listnode *> nodes;
listnode *s = p;
while (s != nullptr)
{
nodes.push(s);
s = s->next;
}
while (!nodes.empty())
{
p = nodes.top();
cout << p->value << " ";
nodes.pop();
}
}
运行结果(初始值 10 9 8 7 6 5 4 3 2 1):
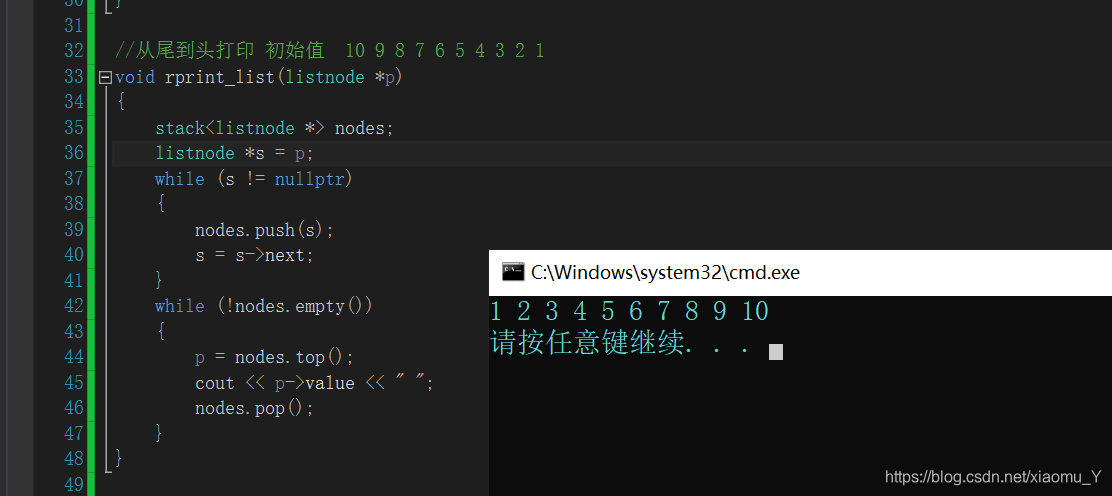
相比较之下,基于栈的实现方法就好多了。好了,本期内容就到此结束,谢谢大家的支持!
文章系本人原创,转载请注明作者和出处。