之前AlphaGo击败韩国名将李世石的新闻让更多的人开始关注人工智能,特别是后来AlphaGo Zero,只训练的40天又把AlphaGo远远超越。着实让人不得不感叹道:哎呀卧槽!好牛逼!!要知道,之前的AlphaGo是学习人类的棋谱训练出来的,也算是以人类的智慧为基础,博采众长嘛,赢了也正常。可是这Zero版本就不一样了,从来没见过人类是怎么下棋,只知道下棋规则,如何算赢。这样经过几百万盘的自我博弈后就轻松的击败老版本AlphaGo,这让人类颜面往哪儿搁;好歹AlphaGo Zero也是人类(DeepMind团队)写出来的,总算挽回了些面子。等有一天这玩意儿进化成【天网】的时候,就没人类什么事了。
口水话太多,还是引入几个专业术语来提升提升文章的逼格吧。
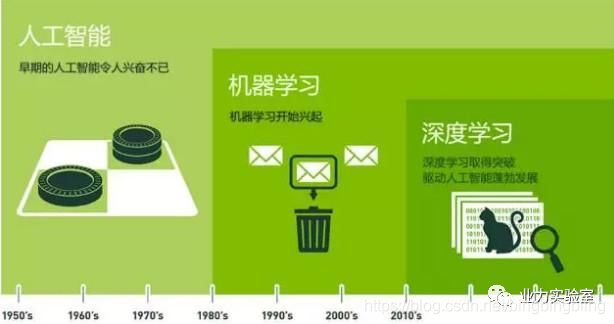
很容易看出来:机器学习是一种实现人工智能的方法,而深度学习则是实现机器学习的一种技术。
深度学习,说白了就是:我们建立一个模型,把一堆训练数据不停的往里扔,根据当前模型算出来的结果与真实结果的差异来修正模型参数,直到这个模型能真正反映训练数据。再白一点就是:已知曲线过几个点,求这个曲线的方程——经过的这几个点就是我们的数据,算出来的方程就是我们最终训练出来的模型 。

目前深度学习对图像识别、语音识别等问题来说就很适合,因为它就是现实的映射。比如你写个8,最多歪一点,但是大体形状跑不了;你说一句话,那一串音频信号和一些文字其实是一一对应的。正如x通过函数y=f(x)之后与y一一对应一样。
正是因为深度学习的模型是现实的一种反映,所以它缺乏反馈机制,无法根据情况的变化实时改变。像AlphaGo Zero那种可以“自娱自乐”的程序则需要引入强化学习。
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
为了让我们的人工智能更加智能,能够举一反三,所以还需要迁移学习。
Transfer learning or inductive transfer is a research problem in machine learning that focuses on storing knowledge gained while solving one problem and applying it to a different but related problem.[1] For example, knowledge gained while learning to recognize cars could apply when trying to recognize trucks. This area of research bears some relation to the long history of psychological literature on transfer of learning, although formal ties between the two fields are limited.
瞄了一眼文章的标题,感觉稍微有点跑题。
好了,现在开始科普无人驾驶。在无人驾驶前先了解下机器学习入门的 Hello World 程序:手写数字识别(还要继续跑题)
对于手写数字识别,我们的输入是写着1234567890的一张张图片,还有这一张张照片本来代表的数字的标记,也就是我们需要求解的方程y=ax+b里面的x(手写数字图片)、y (图片上的数字到底是几) 。
图片是x?(书读得少,不要骗我,以前数学老师没讲过x可以代表图片哦)计算机二进制晓得噻,01010010是啥,我也不知道,只是经过约定好的规则转换过来显示在屏幕上人类才能识别。人与人之间的交流也是一样的,我们的祖先不知道从什么时候开始约定用“人”这个符号代表我们这个物种;等哪天大家都说“狗”这个字笔画多些,显得大气,跟我们这个物种的身份更匹配,那么我们从此以后就改叫“狗类”。其实都一样,我们这样约定了之后,大家再说“狗类”的时候,我们就晓得是在说我们自己了。一点也不影响我们要表达的意思。
回到刚刚的“x可以代表图片”问题。图片是什么,电脑里面的图片并不是真正意义上的图片。照相机的CMOS记录的是曝光一瞬间CMOS各个位置的亮度信息,而亮度就是0-255(或者0-1,跟刚才说的一样,只要大家约定好一点不影响)之间的一个数值。

上面这女娃打印出来其实就是一个三维数组,最里面那个中括号括起来的数字代表的就是一个像素点的信息,分别是R、G、B、透明度。中间括号括起来的就是一行像素点,最外面的中括号就包括整个图片的像素点了。电脑里面存的就是这一堆数字——其实还不是这堆数字,应该是二进制?。等你要看图片的时候电脑读取各个通道的亮度信息渲染成一张照片。
好了,既然x和y都是数字,现在可以放心的代入方程 y = ax+b 求a、b(这个过程就叫神经网络的训练),求出的方程(模型)我们就可以拿来识别数字。显然,a、b已知,代入x ,算出的y就是模型的识别结果。
当然,刚刚你也看到了,图片的数组里面有很多数字,一个x是远远无法代表的,所以我们需要很多的x,x1、x2、x3 、…、 xn,很多的方程,方程嵌套方程——所谓神经网络(Neural Network)就像下面这种:

还有这种:
哈哈,懵逼了吧
不懂也没关系,反正知道通过梯度下降,反向传播算法最后确实可以把那一个个参数算出来就行。反正是科普嘛,了解得太深入那不成了科研?
才疏学浅,我也有点懵逼。不知道DeepMind那帮人脑子里面都装了些啥,AlphaGo Zero这样的程序也能写出来,程序员与程序员的差距咋就这么大呢 [好好反省]
打总结:总之,像手写数字识别这种,只要知道输入图片和图片对应的数字就可以求出方程[假装懂了] ——总感觉表情不够用。
无人驾驶其实和手写数字识别一样,也使用深度学习技术。而在无人驾驶的车辆上面,我们会在车辆前方安装一台照相机,还有一个测量方向盘当前角度的仪器。在训练的时候(由人驾驶车辆),照相机负责不停的拍照,获取车上视觉拍摄到的马路照片;与此同时从方向盘角度测量仪获取角度值。
下面两张图片分别是汽车左转和右转的时候拍摄的马路照片:
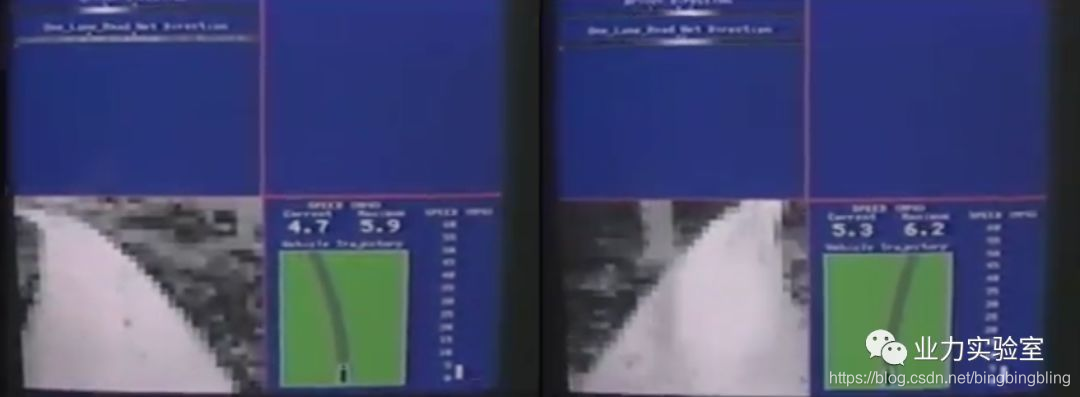
好吧,我们又来【解方程】。
输入x便是马路的照片,y便是方向盘的角度,带入假设方程y=ax+b解出参数便得方程(即最终训练好的模型)。等到自动驾驶的时候,实时拍摄马路照片x,代入方程(模型)算出方向盘角度y。然后根据方向盘的角度——突然意识到,在车上还需要安装一个可以根据角度值旋转方向盘的机械装置了
所谓无人驾驶就是这么回事,这下明白了吧,Give me five !
如果还没明白,那么接下来请广大程序员的男神吴恩达来给我们再讲讲。
请戳下面的视频:
视频来源:
https://www.coursera.org/learn/machine-learning/lecture/zYS8T/autonomous-driving
这下明白了噻
如果还不明白的话,额… 那就随缘吧