研究对象:AES、Blowfish、Camellia、DES和 IDEA 等 5 种分组密码体制。
特征选择:基于 NIST 测试集中的 15 种随机性测试提出了 54 种基于随机性测试的新密文特征。
分类器选择:支持向量机、随机森林。
分类器优化:降维算法和并行
主要工作:
- 构建基于机器学习算法的密码体制识别方案
- 分析影响密码体制识别效率的因素
- 挖掘密文特征,提高密码体制识别方案的效率
- 采用并行化和特征降维技术进一步优化方案
密码体制识别发展方向:
持续改进密文特征方法(假设检验、分布函数、主成分分析、因子分析等)。
深度学习技术应用。
借鉴其他识别领域的思想与方法(文本特征抽取等)。
基于支持向量机的密码体制识别方案
密码体制识别主要分为:特征提取和密文识别两部分。
密码体制识别模型见上一篇密码体制分层识别方案-单分
密码体制识别方案公式:
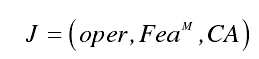
密码体制识别方案评价指标: 主要指标为识别准确率,同时密文特征维数、数据量、运行时间、特征识别准确率的标准差都可作为评价方案的辅助指标。
准确率包含 :误报率(FPR)、精准率(precison)、召回率(recall)。
误报(FP,false positive)是将本不属于某类密码体制的密文识别为该类密码体制;漏报(FN,false negative)是指将本属于某类密码体制的密文识别为其它类型密码体制;真报(TP,true positive)是将属于某类型密码体制的密文识别为该类密码体制。
误报率(FPR,false positive rate):
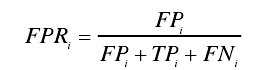
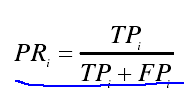
精确率(precison):
召回率(recall):
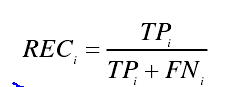
密文特征提取算法
主要基于四种方式:
源于 NIST 随机性测试标准中的三种随机性测试:the Frequency test、the Block Frequency test、the Run test,和一种基于定长比特串概率特征。
- 随机性测试方式,通过对密文分块,提取各分块在随机性测试下的返回值作为特征,可以据此比较密文局部的随机性,进而将其作为分类识别的依据。
- 基于定长比特串概率特征,则直接以密文比特的分布信息作为密文特征,是一种比较自然直观的特征提取方法。
算法输入:文件数量 F,密文序列长度lB bits,密文分块数 K(K =64,128,256),密文序列(0、1 比特串)file.
the Frequency test特征提取算法:
先将密文分为K块,每块Bi大小为
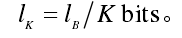
再将密文比特串Bi中的 0 和 1 分别用 1 和-1 来表示,计算Sn
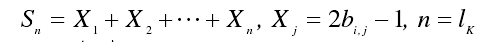
然后计算测试统计量Si和特征fi(erfc 为余补误差函数)
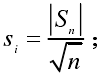
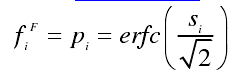
最后将所有的密文分块得到 K 个返回值作为密文特征,记作
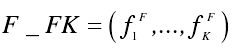
the Block Frequency test特征提取算法:
第一步同上,将密文分块。在 测 试 中 设 置 Block Size M 设 为 512bits 。
再将第 i 个密文块划分成N个非重叠的比特块(N=lB/M)并舍弃多余的比特。
对每个长度为M的比特串计算Xi、统计量X²和测试值p:
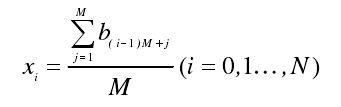
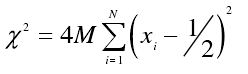
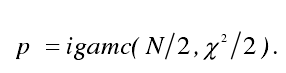
最后将提取到的 K 个返回值作为密文特征,记
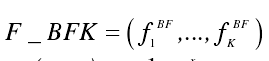
the Run test特征提取算法:
先将密文分成K块,在分别对每一小块密文执行Run test并得到一个返回值。
再对于密文比特串计算测试统计量Vi,n和随机测试值pi
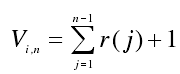
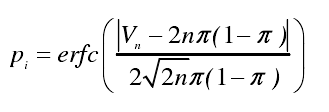
最后返回所有 K 个返回值 p,形成 K 维特征,记为
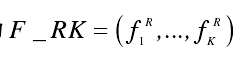
基于定长比特串概率特征:
除算法输入值外,还需要密文定长比特长度 h(h=7,8,9,10,11),输出为密文件中所有 h bits 比特串出现的概率值。
第一步将密文按照每 h bits 划分成块,再计算每个密文分块的T种可能取值出现的概率T=2^h
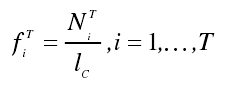
最后返回 T 个概率值形成 T 维特征,记为
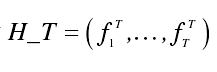
基于支持向量机密码体制识别算法
算法输入:待识别密码体制数量 N,密文件数量 n,密文长度 lB bits,密文分块 K,密文0、1 序列。
算法输出:各密文件所属密码体制识别结果。
算法描述:
1 训练阶段
(1)分别采集由 5 种密码体制加密的 N 组密文文件,每组含有 n 个文件;
(2)对密文数据进行特征提取,得到 N 组特征集,并加入与其密码体制类别对
应的标签;
(3)将带标签的特征数据输入支持向量机分类器,进行分类模型的训练。
2 测试阶段
(1)对一个待识别密文文件的内容数据进行特征提取,得到特征数据;
(2)输入特征数据到训练好的分类模型中,后者给出识别结果,并记录。
(3)重复测试阶段第 2 步 S 次,取 S 次识别准确率平均值作为结果。
先到这里吧!明天再更新!