今天分享的paper是刘群老师发表在ACL2019的一篇文章,同样是一篇介绍复述生成的论文,叫Decomposable Neural Paraphrase Generation(DNPG,网络可分解的复述生成)。
论文的动机:作者发现一个句子的复述通常有多个不同粒度的模式组成,从单词粒度到短语粒度到句子粒度等,如下图:

蓝色部分为句子粒度,绿色部分为短语粒度。在这篇论文中,作者取了这两个粒度进行分析。
论文的主要贡献:
1. 可解释性;
2. 可控性;
3. 可迁移性。
论文的主要框架如下图:

模型结构共分为四个部分:Separator(分离器),encoder,decoder,Aggregator(聚合器)。分离器将原句子的每个词分为短语模式或者句子模式,encoder,decoder即分别对每个模式进行编码解码,最后使用聚合器将各个模式聚合起来,得到预测的结果。
以下三条公式分别表示encoder,decoder以及最后的输出(即复述生成的结果):

前两条公式的m表示不同粒度模式下使用不同的编码,最后一条公式中的表示不同的模式:短语模式或者句子模式,相应的取值0或1;公式第一项表示在
模式下的预测结果,第二项表示t时刻的输出为
模式的概率。
Separator(分离器):
分离器部分,作者使用stacked LSTM来判断输入变量的每个时刻的模式(0或1):

Multi-granularity encoder and decoder:
编码解码部分作者使用了transformer的结构,并做了一点小改动。这部分作者介绍了三个方面,分别是positional encoding, multi-head attention, model capacity.
positional encoding 如下图所示,跟transformer中的描述一样,想仔细了解这部分的读者,可以看我上一篇文章:transformer中的positional encoding(位置编码)

对于短语模式,位置编码不做改变;对于句子模式,对于每个位置,作者取该位置之前的所有模式为1的位置编码之和作为该位置的编码。
multi-head attention方面,在短语模式下,作者取邻近三个变量做attention,目的是为了获取局部特征;句子模式下,作者取所有模式为1的变量做attention。具体如下图:

Model Capacity方面,作者为了提高短语模式下transformer的能力,引入了16年一篇文章中介绍的attention过程中的copy机制(这篇文章我还没看,暂不做展开,后续看完再开一篇博客具体介绍),具体如下:

下面一张图是对短语模式和句子模式的对比。
Aggregator(聚合器):

聚合器其实就是一个判别器,判断当前时刻输出结果的模式,如下图公式所:

我们上文提到,最后输出结果由下式得到:
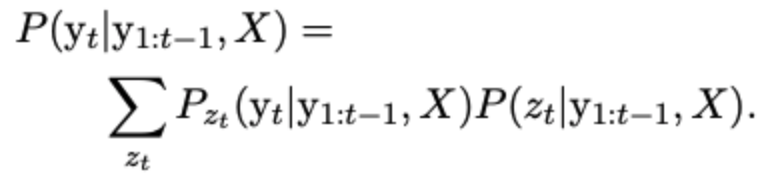
其中聚合器完成第二项的计算,而第一项由每个模式下decoder的输出结果得到。
引入先验知识:Learning of Separator and Aggregator
we induce weak supervision to guide the training of the model. (引入先验知识:短语对)

其中,作者从一个已知库中获取一些短语对,并把这些短语对中的词作为短语模式,即存在短语对中的为1,或者为0,以此来添加先验知识,加快收敛速度,同时,在模型训练过程中,
从1到0衰减。
接下来介绍实验结果:

Interpretable Paraphrase Generation(可解释性):

Controllable Paraphrase Generation(可控性):

Unsupervised Domain Adaptation(可迁移性):

作者使用强化学习的方法将第一个数据集的语言模型得到的结果作为奖励添加到第二个数据集中,以此来提高第二个数据集的学习能力,得到的结果如下:

Ablation Studies(消融实验):

以上,便是这篇论文的所有介绍,欢迎交流。