如果经常创建和销毁、使用量特别大的资源,比如并发情况下的线程,对性能影响很大。线程池通过提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。
1、使用线程池的好处:
①提高响应速度(减少了创建新线程的时间)
②降低资源消耗(重复利用线程池中线程,不需要每次都创建)
③便于线程进行管理,线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
2、线程池的体系结构

3、线程池的工作流程
使用ThreadPoolExecutor创建线程池的方法及各个参数的意思,如下所示:
ThreadPoolExecutor threadPoolExecutor1 = new ThreadPoolExecutor(
int corePoolSize, //核心线程数
int maximumPoolSize, //最大线程数
long keepAliveTime, //备用线程的存活时间
TimeUnit unit, //时间单位
BlockingQueue<Runnable> workQueue, //任务队列
RejectedExecutionHandler handler //饱和策略(拒绝策略)
);
下面我们就先使用ThreadPoolExecutor 创建一个线程池,并画图演示它的工作流程,如下所示:
ThreadPoolExecutor threadPoolExecutor1 = new ThreadPoolExecutor(
corePoolSize:2, //核心线程数为2
maximumPoolSize:5, //最大线程数为5
keepAliveTime:10, //备用线程的存活时间
TimeUnit.SECONDS, //时间单位
new ArrayBlockingQueue<>(10), //任务队列
new ThreadPoolExecutor.AbortPolicy() //拒绝策略(饱和策略)
);
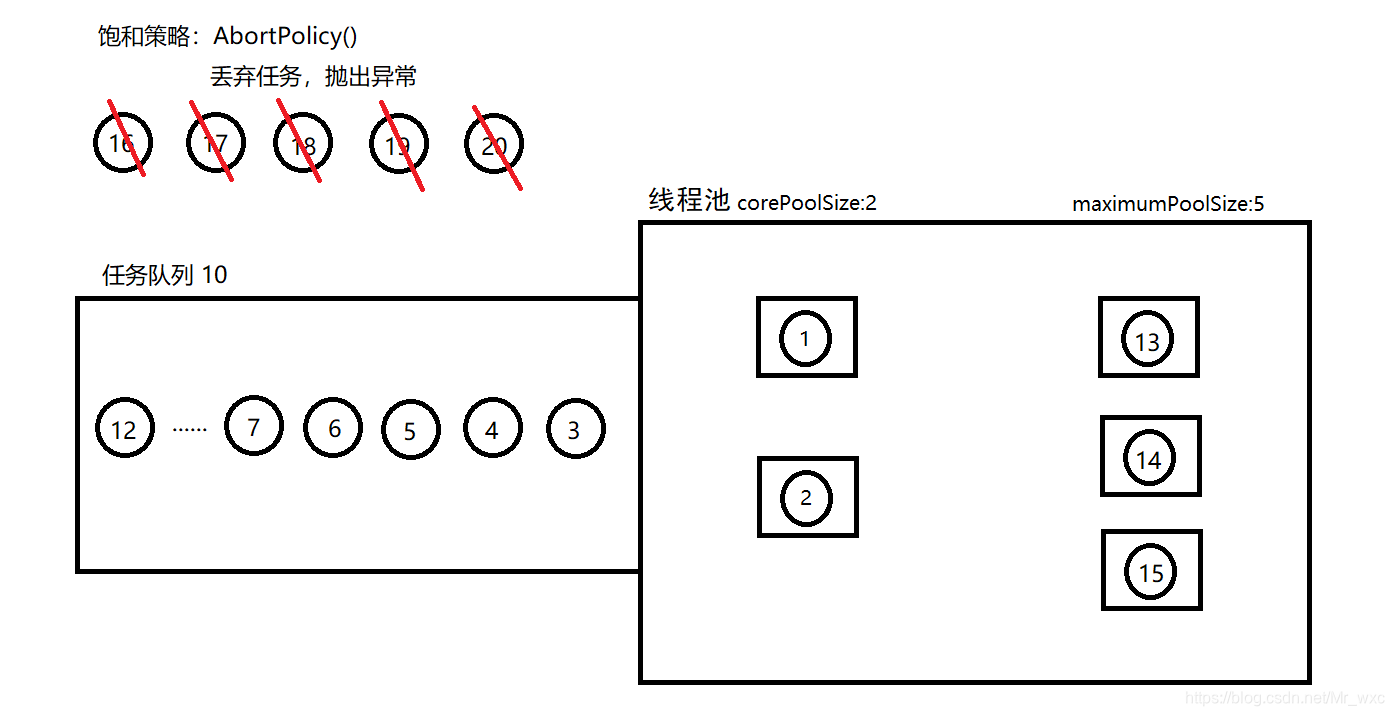
线程池的工作流程如下:
(1)判断当前线程池中的线程数是否小于设置的核心线程数。如果小于核心线程数,就创建一个新的线程来执行当前任务;
(2)如果当前线程池中的线程数大于核心线程数,则将任务放入任务队列;
(3)如果任务队列已满,不能入队,则判断当前线程池中的线程数是否小于设置的最大线程数。如果小于设置的最大线程数则创建一个临时线程(非核心线程)执行该任务;
(4)如果大于设置的最大线程池则说明当前线程池已经饱和,需要进行拒绝策略,根据设置的拒绝策略进行处理。
注意:当线程池中的线程数大于coolPoolSize,超过keepAliveTime时间的闲置线程会被回收掉。回收的是非核心线程,核心线程一般是不会回收的。如果设置了allowCoreThreadTimeOut(true),则核心线程在闲置keepAliveTime时间后也会被回收。
4、线程池的三种任务队列
(1) SynchronousQueue 同步队列
SynchronousQueue一次只能装一个任务,只有把当前任务消费了,才能再装下一个任务;
使用SynchronousQueue阻塞队列一般要求maximumPoolSizes为无界,避免线程拒绝执行操作。
(2) LinkedBlockingQueue
LinkedBlockingQueue是一个无界缓存等待队列,可以装无限个任务。如果线程池中当前执行任务的线程数量达到corePoolSize,则剩余的任务都会装入阻塞队列里进行等待。(所以在使用此阻塞队列时maximumPoolSizes就相当于无效了)
(3) ArrayBlockingQueue
ArrayBlockingQueue是一个有界缓存等待队列,可以装指定个数的任务。如果线程池中正在执行的线程数等于corePoolSize时,多余的任务就会缓存在ArrayBlockingQueue队列中,等待有空闲的线程时继续执行。如果ArrayBlockingQueue已满,加入ArrayBlockingQueue失败时,会开启新的备用线程去执行,当线程数已经达到maximumPoolSizes时,再有新的任务尝试加入ArrayBlockingQueue时就会报错。
5、线程池的四种拒绝策略
ThreadPoolExecutor中内置了四种拒绝策略:
(1) ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常;(默认)
(2) ThreadPoolExecutor.CallerRunsPolicy:不丢弃任务,交由调用线程池的线程(提交任务的线程)执行该任务;
(3) ThreadPoolExecutor.DiscardPolicy:丢弃队列最后面的任务,但是不抛出异常;
(4)ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,不抛出异常。
使用场景分析
(1) ThreadPoolExecutor.AbortPolicy:丢弃任务并抛出RejectedExecutionException异常
这是线程池默认的拒绝策略,在任务不能再提交的时候会抛出异常,及时反馈程序运行状态。如果是比较关键的业务,推荐使用此拒绝策略,这样在系统不能承载更大并发量的时候,能够及时的通过异常发现问题。
(2) ThreadPoolExecutor.CallerRunsPolicy:不丢弃任务,交由调用线程池的线程(提交任务的线程)执行该任务;
这种拒绝策略适用于一般在不允许失败的、对性能要求不高、并发量较小的场景;因为线程池一般情况下不会关闭,也就是提交的任务一定会被执行,但是由于是调用者线程自己执行的,当多次提交任务时,就会阻塞后续任务执行,性能和效率就会变慢。
(3) ThreadPoolExecutor.DiscardPolicy:丢弃队列最后面的任务,但是不抛出异常;
使用此策略时,线程池会直接静悄悄的丢弃任务,可能会使我们无法发现系统的异常状态,不推荐使用。如果要使用,建议使用在一些无关紧要的业务上面。
(4)ThreadPoolExecutor.DiscardOldestPolicy:丢弃队列最前面的任务,不抛出异常;
可以根据实际业务是否允许丢弃老任务来衡量是否使用此策略。
6、线程池的工具类
Executors是线程池的工具类,提供了四种快速创建线程池的方法。这四种方法底层也是通过ThreadPoolExecutor创建的。
① Executors.newCachedThreadPool():创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若没有可回收的线程,则新建线程;
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
② Executors.newFixedThreadPool(n); 创建一个可重用的固定线程数的线程池;
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
③ Executors.newScheduledThreadPool(n):创建一个定长线程池,支持定时及周期性任务执行。
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue()); //Delayed是无界阻塞队列,只有在延迟期满时才能从中提取元素
}
ScheduledExecutorService中两个常用的方法:
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
//常用方法一:延时执行任务
//参数1:任务 参数2:延迟时间 参数3:时间单位
scheduledExecutorService.schedule(new PrintNumber2(),10,TimeUnit.SECONDS);
//常用方法二:周期性执行任务
//参数1:任务 参数2:延迟时间 参数3:间隔时间 参数4:时间单位
scheduledExecutorService.scheduleAtFixedRate(new PrintNumber2(),5,3,TimeUnit.SECONDS);
④ Executors.newSingleThreadExecutor() :创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
7、线程池ThreadPoolExecutor的源码分析
友情提示:每一部分源码,我都加了注释,在看源码的同时,结合着注释可以更好的进行理解。
ThreadPoolExecutor中最主要的实现源码如下:
//HashSet中存放的是所有的工作线程,实际上我们所说的线程池指的就是它
private final HashSet<Worker> workers = new HashSet<Worker>();
HashSet中存放的是所有的工作线程,实际上我们所说的线程池指的就是它。
集合中的每一个Woker都是一个工作线程,Woker也是线程池实现的核心,下面一点一点的分析Woker的源码。
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
Woker实现了Runnable接口,代表它也是一个可执行的任务。
Woker中有两个重要的属性如下:
final Thread thread; //具体执行任务的线程
Runnable firstTask; //第一次要执行的任务
Woker的构造器如下:
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask; //创建worker时,传入第一次要执行的任务
this.thread = getThreadFactory().newThread(this); //把Woker本身作为参数传递给线程工厂的newThread方法创建线程
//这样,当thread启动时,Woker中的run()方法就会被执行
}
firstTask是创建worker时,传入的第一次要执行的任务;thread就把Woker本身作为参数传递给线程工厂的newThread方法创建的线程。这样,当thread启动时,Woker中的run()方法就会被执行。
接着看Woker的run()方法,里面有线程复用的真相,源码如下:
//worker的run方法中直接调用了runWorker(this); this代表worker对象本身
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask; // 第一次要执行的任务
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//如果任务不为空 或者 使用getTask方法获取到的任务不为空
while (task != null || (task = getTask()) != null) {
w.lock();
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run(); //那么将会执行run()方法
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null; //执行完后清空任务,继续循环执行
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
由上述源码可知,如果任务不为空或者使用getTask方法获取到的任务不为空,那么将会执行run()方法,执行完后清空任务,继续循环执行。
那么getTask()方法是怎样获取任务的呢?看一下getTask()方法的源码
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take(); //WokerQueue是线程池中的任务队列
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
由getTask()方法的源码可知,getTask()方法会去workQueue任务队列里获取任务,这样run()方法中的while循环就能一直执行,线程也能够一直复用,这就是线程复用的真相。
那么什么时候woker会被创建呢?创建之后什么时候会被启动呢?
这就得分析一下execute()方法的源码了。
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { //如果工作线程的数量小于核心线程数,就会添加一个worker
if (addWorker(command, true)) //参数1:要执行的任务 参数2: true代表添加核心线程,false代表添加的是临时线程
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { //如果核心线程数够了,那么就会尝试向任务队列workQueue中添加一个任务
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false)) //如果任务队列workQueue已满,那么就会执行拒绝策略
reject(command);
通过execute()方法的源码可知,如果工作线程的数量小于核心线程数,就会添加一个worker;如果核心线程数够了,那么就会尝试向任务队列workQueue中添加一个任务;如果任务队列workQueue已满,那么就会执行拒绝策略。与之前我们所说的线程池的工作流程是一样的。接着我们看一下addWorker方法的源码是怎样创建Woker的?
Worker w = null;
try {
w = new Worker(firstTask); //把第一次要执行的任务作为参数传递给Woker的构造器,创建一个Woker对象
final Thread t = w.thread; //调用Woker中的线程
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
workers.add(w); //将worker对象添加到workers集合中
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true; //把workerAdded设为true,表示添加成功
}
} finally {
mainLock.unlock();
}
if (workerAdded) { //如果添加worker成功
t.start(); //就会启动Woker中的thread线程,那么Woker中的run方法也会被执行
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
由源码可知,创建Woker时会把第一次要执行的任务作为参数传递给Woker的构造器,创建一个Woker对象;然后调用Woker中的线程赋值给当前线程。接着将worker对象添加到workers集合中,把workerAdded设为true,表示添加成功。最后如果添加worker成功,就会启动Woker中的thread线程,那么Woker中的run方法也会被执行。
如果对你有帮助,记得点赞关注。
关注我,带你学习更多更有用的干货。