前言
终于到了期待的内存了,这章主讲的是堆和栈。我们按照做题的思想分开来看堆和栈,首先是在栈溢出的角度,在编写payload的时候就需要在脑海中有一个栈部署的体系,哪个位置是参数,哪个位置是指令,栈顶指针走到哪一步的时候执行某种操作等等,想好了这些东西之后再通过代码实现出来。在从堆溢出的角度来看,如何申请一个堆块,申请多大,堆块中应该些什么,堆块之间如何连接,释放之后会有什么效果。这些也是应该在计划之中的。这一章,主要想写一写关于堆的介绍。我是通过做栈溢出题来了解栈结构的,可以说是野路子,在看这本书的栈时,虽然讲的东西一样,但总感觉很别扭,关于栈的东西可以看一下原著,也可以看我之前发布的栈溢出的教程。
这章如果能够帮助到你,希望能够点个赞支持一下
Thanks♪(・ω・)ノ
一、程序的内存布局
前面讲过Linux操作系统默认情况下会占用一部分内存,还是拿32位操作系统举例,如果32位寻址能力是4GB的话,那么操作系统就会将高地址的1GB空间分给内核使用,身下的3GB的内存空间被称为用户空间。在用户空间中也有许多地址区间有特殊的地位:
- 栈:栈用于维护函数调用的上下文,离开了栈函数调用就没法实现。通常在用户空间的最高地址出分配,通常有兆字节的大小
- 堆:堆是用来容纳应用程序动态分配的内存区域。当程序使用malloc或new分配内存时,得到的内存来自堆里。对常存在于栈的下方(低地址方向)。某些时候堆也可能没有固定统一的存储区域。堆一般比栈大很多,可以有几十至数百兆字节的容量
- 可执行文件影响:这里是由装载器在装载时将可执行文件的内存读取或映射到这里
- 保留区:保留区并不是一个单个的内存区域,而是对内存中受到保护而禁止访问的内存区域的总称,例如到多数操作系统里,极小的地址通常是不允许访问的,如NULL
二、堆与内存管理
1、什么是堆
堆是一块很大的内存空间,常常占据整个虚拟空间,举一个申请堆空间的例子:
int main(){
char *p = (char *)malloc(1000);
/*使用p作为大小为1000的数组*/
free(p);
}
在第3行使用malloc申请了1000个字节的空间之后,程序可以自由地使用这1000个字节,知道程序用free函数释放它。
那么malloc是怎么实现的呢?程序箱操作系统申请一块适当大小的堆空间,然后由程序自己管理这块空间,管理者对空间分配的往往是程序的运行库。运行库相当于向操作系统“批发”了一块较大的堆空间,然后“零售”给程序用。当全部“售完”或程序有大量的内存需求时,再根据实际需求向操作系统“进货”。当运行库向程序零售堆空间时,必须管理它批发来的堆空间,不能把同一块地址出售两次,这回导致地址冲突。于是运行库需要一个分配算法来管理堆空间。在将分配之前,先看看运行库是怎么向操作系统批发内存的
2、Linux进程堆管理
Linux下使用两个系统调用来申请堆空间:
- brk()系统调用
- mmap()
brk()的作用是设置京城数据段结束地址,即可以扩大或者缩小数据段。如果将数据段的结束地址向高地址移动,那么扩大的那部分空间就可以被拿来作为堆空间使用。Glibc中还有一个函数叫sbrk,功能和brk类似。sbrk以一个增量作为参数,需要增加(负数为减少)的空间大小,返回值是增加(或减少)后数据段结束地址,这个函数实际上是对brk系统调用的包装,也是通过brk()实现的
mmap()的作用是向操作系统申请一段虚拟地址空间,这段虚拟地址空间可以用来映射到某个文件,这也是这个系统调用的最初作用。当它不将地址空间映射到某个文件时,又称为这块空间为匿名空间。匿名空间堆空间作为声明如下
void *mmap(
void *start,
size_t length,
int prot,
int flags,
int fd,
off_t offset
);
mmap的前两个参数分别用于指定需要申请的空间的起始地址和长度,如果起始地址设置为0,那么Linux系统会自动挑选合适的起始地址。prot/flags这两个参数用于申请的空间的权限(可读、可写、可执行)以及映射类型(文件映射、匿名空间等),最后两个参数是用于文件映射时执行文件描述和文件偏移的
3、堆分配算法
3.1、空闲链表
空闲链表(Free List)的方法实际上就是把堆中各个空闲的块按照链表的方式连接起来,当用户请求一块空间时,可以遍历整个列表,知道找到合适大小的块并且将它拆分,当用户释放空间时将它合并到空闲链表中
其实挺复杂的,首先需要一个数据结构来登记堆空间里所有的空闲空间,这样才能知道请求空间的时候该分配给它哪一块内存。最简单的一种就是空闲链表
空闲链表是一种结构,在堆块的每个空闲空间的开头(或结尾)有一个头(header),头结构里记录了上一个(prev)和下一个(next)空闲块的地址,所有的空闲块形成了一个链表:
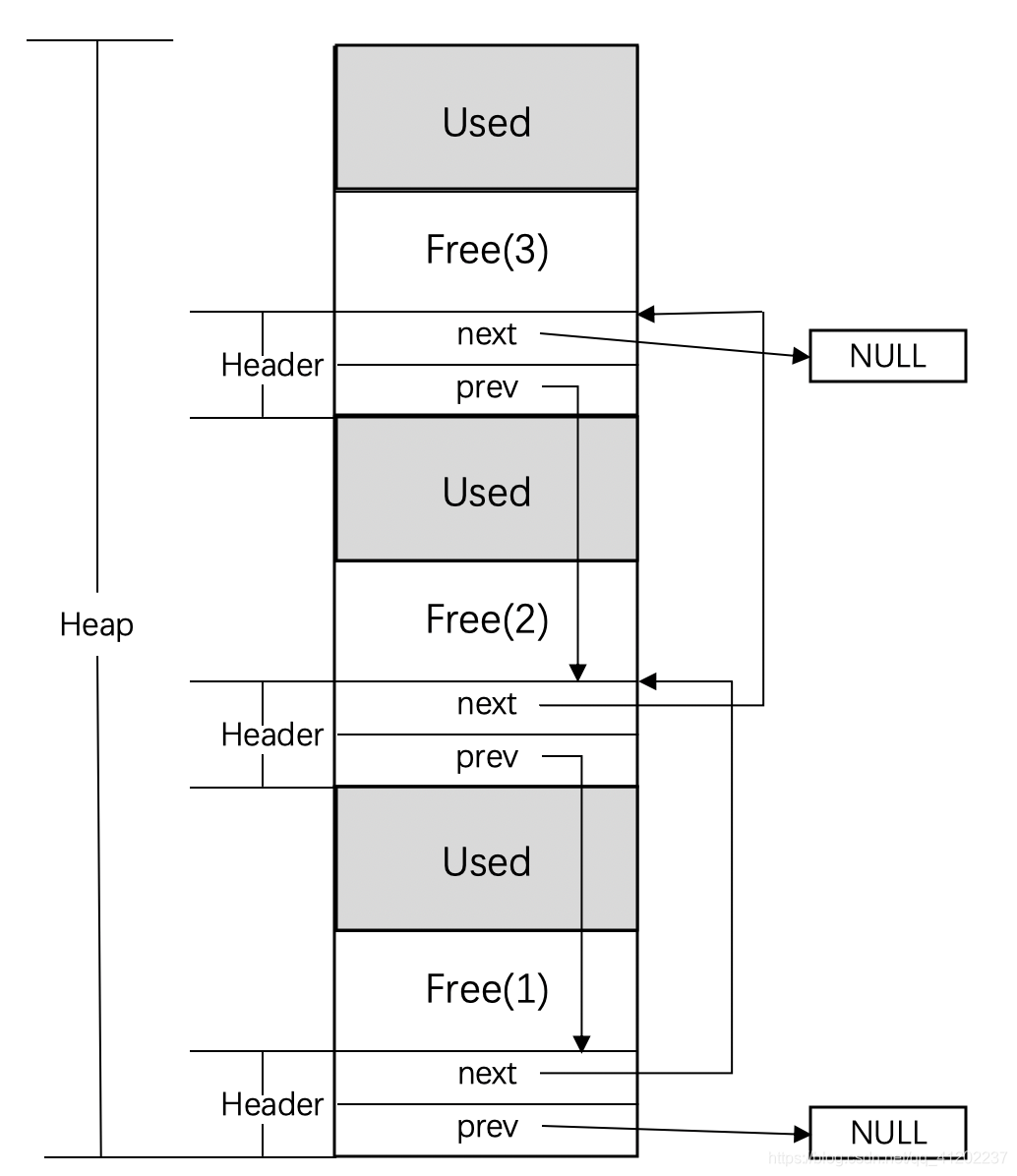
上面就是空链表的结构,在分配空间时,首先在空闲链表里查找足够容纳请求大小的一个空闲块,然后将这个块分成两部分,一部分为程序请求的空间,另一部分为剩下来的空闲空间。下面将链表里对应原来空闲块的结构更新为新的剩下的空闲块,如果剩下的空闲块大小为0,则直接将这个结构从链表里删除。下面展示请求空闲块2相等的内存空间后对的状态:
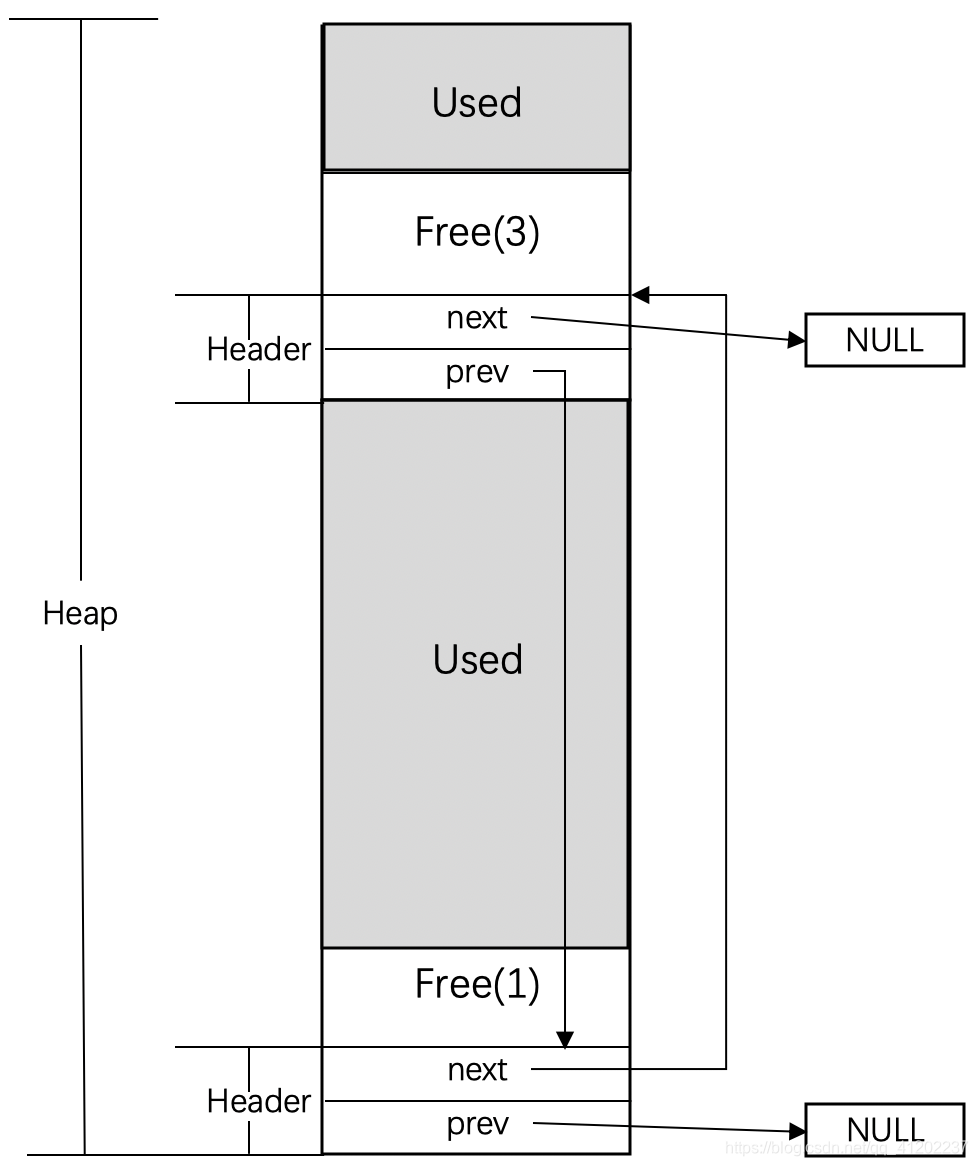
空链表实现简单,但是在释放空间时候需要给定一个已分配块的指针,当用户请求k个字节空间时候,实际分配k+4个字节,4个字节用于存储该块分配的大小,然后将其插入到空闲链表就行了
这种结构有问题,一旦链表破坏,或者记录长度的4个字节被破坏,整个对就无法正常工作,这些数据很容易被越界读写所接触到
3.2、位图
另外一种方式称之为位图(Bitmap),核心思想是将整个堆划分成大量的块(block),每个块大小相同。当用户请求内存时,总是分配整数个块的空间给用户,第一个快称为已分配区域的头(head),其余的称之为已分配区域的主体(Body)。可以使用一个整数数组来记录块的使用情况,由于每个块值有头/主题/空闲三种状态,所以只需要两位即可表示一个块
假设堆的大小为1MB,那么让一个块的大小为128字节,那么总共就有1M/128=8k个块,可以用8k/(32/2)=512个int来存储。这有512个int的数组就是一个位图,其中每两位代表一个快。当用户请求300字节的内存时,对分配给用户3个块,并将位图的相应位置标记为头或躯体:

这个堆分配了3片内存,分别由2/4/1个快,用虚线标出,其对应的位图是:
(HIGH)11 00 00 10 10 10 11 00 00 00 00 00 00 00 10 11 (low)
这样的实现方式有几个特点:
- 速度快:由于整个堆的空闲信息存储在一个数组内,因此访问该数组时cache容易命中
- 稳定性好:为了避免用户越界读写破坏数据,只需简单的备份以下位图就行,而且即使部分数据被破坏,也不会导致整个堆无法工作
- 块不需要额外信息,易于管理
位图也有一些缺点:
- 因为都是以整数倍的块进行分配,所以分配内存时容易产生碎片,浪费资源
- 如果堆很大,或者设定的一个块很小(可以减少碎片),那么位图就会很大,可能失去cache命中率高的优势,也会浪费一定的空间。针对这种情况,可以使用多级的位图
3.3、对象池
在一些场合,被分配对象的大小是较为固定的几个值,这时候就可以针对这样的特征设计一个更为高效的堆算法,称为对象池
对象池的思路是如果每一次分配的空间大小都一样,那么就可以按照这个每次请求分配的大小作为一个单位,把整个堆空间划分成大量的小块,每次请求的时候只需要找到一个小块就可以了
对象池的管理方法可以采用空闲链表,也可以采用位图,与他们的区别仅仅在于它假定了每次请求的都是固定大小,实现起来比较容易。由于每次总是之请求一个单位的内存,因此请求得到满足的速度非常快,无需查找一个足够大的空间
实际应用中,堆的分配算法会采取多种算法。比如对于glibc来说,对于小于64字节的空间申请是采用类似于对象池的方法,对于大于512字节的空间申请采用的是最佳适配算法,对于大于64字节小于512自己的,会根据情况采取上述方法的最佳折中策略,对于大于128KB的申请,会使用mmap机制直接向操作系统申请空间
