前言
《图解HTTP》这本书对互联网基础—— HTTP 协议进行了全面系统的介绍。这段时间已经读了一些日系科普图书,发现它们大多数的特点就是细致周全。

作为日系科普丛书的一员,《图解HTTP》也完美继承了这个特点。
作者从 HTTP 发展史开始,严谨地剖析了 HTTP 协议的结构,列举很多常见通信场景及实战案例,特别是对HTTP首部各种字段以及新增的协议进行了全面的介绍。最后延伸到Web安全、最新技术动向等方面。通过书中大量生动形象的通信图例,我们能够更全面地理解 HTTP 通信过程中客户端与服务器之间的交互情况。相比于《HTTP权威指南》这种圣经,这本更适合你我小白阅读。

HTTP协议
HTTP协议和TCP/IP协议族内的其他众多的协议相同,用于客户端和服务器之间的通信。是一个简单的请求-响应协议,它通常运行在TCP之上。请求访问文本或图像等资源的一端称为客户端,而提供资源响应的一端称为服务器端。
其基本思路非常简单,首先,客户端会向服务器发送请求消息。请求消息中包含的内容是“对什么”和“进行怎样的操作”两个部分。
其中相当于“对什么”的部分称为URI。一般来说,URI的内容是一个存放网页数据的文件名或者是一个CGI程序(对Web服务器程序调用其他程序的规则所做的定义就是CGI,按照CGI规范来工作的程序就称为CGI程序)的文件名,例如“/dir1/file1.html”。不过,URI不仅限于此,也可以直接使用”http:”开头的URL来作为URI。换句话说就是,这里可以写各种访问目标,而这些访问目标统称为URI。
“进行怎样的操作”的部分被称为方法。方法表示需要让Web服务器完成怎样的工作,其中典型的例子包括读取URI表示的数据、将客户端输入的数据发送给URI表示的程序等。
HTTP协议规定,请求从客户端发出,最后服务器端响应该请求并返回。换句话说,肯定是先从客户端开始建立通信的,服务器端在没有接收到请求之前不会发送响应。
HTTP报文大致可分为报文首部和报文主体两块,两者由最初出现的空行(CR+LF)来划分。在请求中,HTTP 报文由请求方法,URI,HTTP版本,HTTP 首部字段组成的报文首部和报文主体构成。在响应中,HTTP 的报文有HTTP 版本,状态码,HTTP首部字段组成的报文首部和报文主体构成。通常,并非必须要有报文主体。
首部信息尤为重要,我们可以通过首部字段的设置来传递请求信息,类比于缓存控制,报文创建时间,是否压缩编码,是否支持跨域等。请求报文和响应报文的首部信息也可以按照请求行、状态行、首部字段进行划分。
请求行:包含用于请求的方法,请求URI和HTTP版本。
状态行:包含表明响应结果的状态码,原因短语和HTTP版本。
首部字段包含请求和响应的各种条件和属性的各类首部。
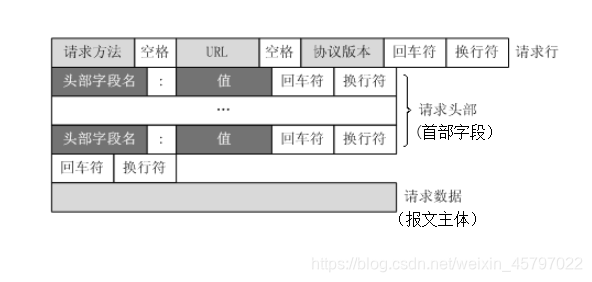
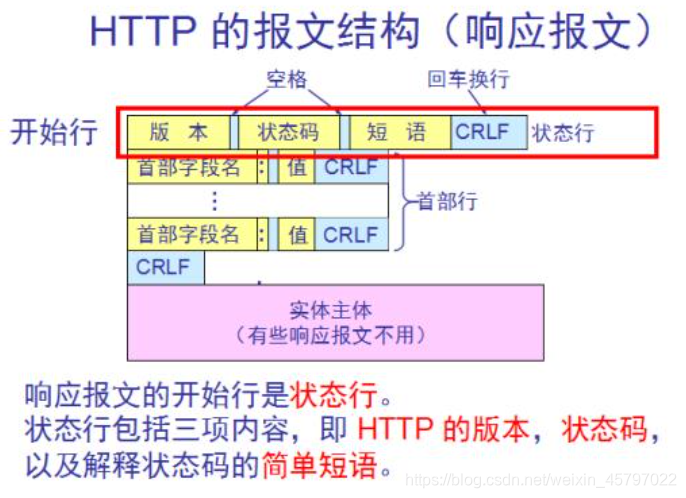
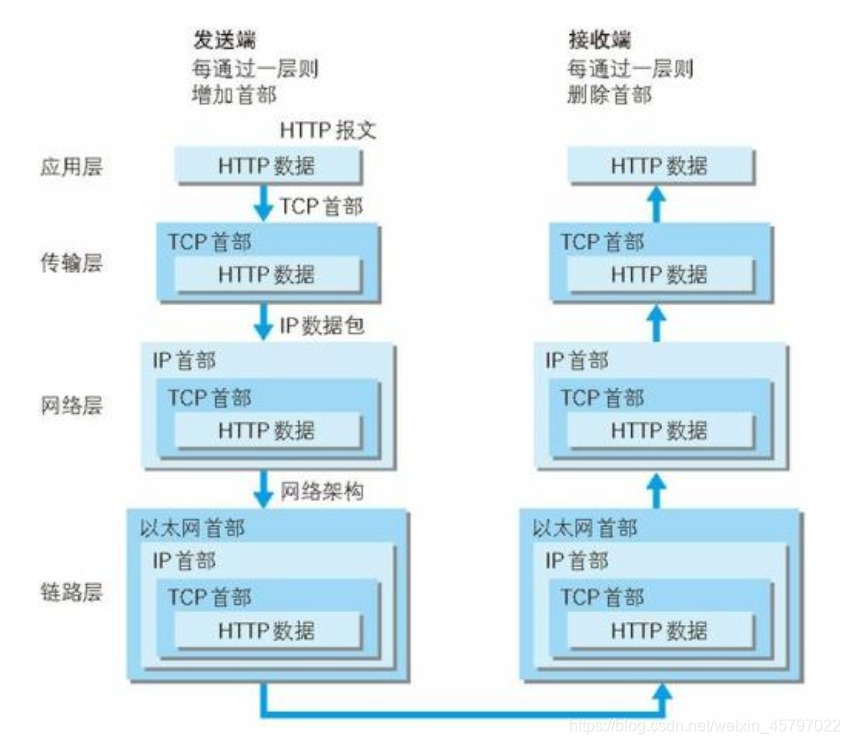
请求报文在网络中的传输过程如下图:
HTTP是不保存状态的协议
HTTP 协议是一种无状态(stateless)协议,不会去记录上一次访问状态,自身不对请求和响应之间的通信状态进行保存。使用HTTP协议,每当有新的请求发送时,就会有对应的新响应产生。协议本身并不保留之前一切的请求或响应报文的内容。这是为更快地处理大量事务,确保协议地可伸缩性,而特意把HTTP协议设计成如此简单的。这使得当我们要做类似于登录这样的功能的时候,需要通过 cookie技术来进行状态的管理。
HTTP协议中所支持的方法
向请求URI指定的资源发送请求报文时,采用称为方法的命令。方法的作用在于,可以指定请求的 资源按照期望产生某种行为。HTTP协议所支持的方法中比较常用的有GET、POST、HEAD等。
下表列出了HTTP/1.0和HTTP/1.1支持的方法。注意:方法名区分大小写,要用大写字母。
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINK | 断开连接关系 | 1.0 |
下面来针对HTTP/1.1协议版本的常用方法进行详细介绍
GET
GET方法用来请求访问已被URI识别的资源。指定的资源经服务器端解析后返回响应内容。也就是说,如果请求的资源是文本,那就保持原样返回;如果是向CGI那样的程序,则返回经过执行后的输出结果

POST
POST方法用来传输实体的主体,虽然用GET方法也可以传输实体的主体,但一般不用GET方法进行传输。虽说POST的功能与GET很相似,但POST的主要目的并不是获取响应的主体内容。

PUT
用来传输文件。就像FTP协议的文件上传一样,要求在请求报文的主体中包含文件内容,然后保存到请求URI指定的位置。但是鉴于HTTP/1.1的PUT方法自身不带验证机制,任何人都可以上传文件,存在安全性问题,因此一般的Web网站不适用该方法。若配合Web应用程序的验证机制,或架构设计采用REST(表征状态转移)标准的同类Web网站,就会开放PUT方法。
HEAD
HEAD方法和GET方法一样,只是不返回报文主体部分,返回报文首部。用于确认URI的有效性和资源更新的日期时间等。
DELETE
就是字面意思,与PUT方法作用相反,删除文件。但是HTTP/1.1的DELETE方法和PUT方法一样本身不带验证机制。所以也需要配合Web应用程序的验证机制,或架构设计采用REST标准。
TRACE
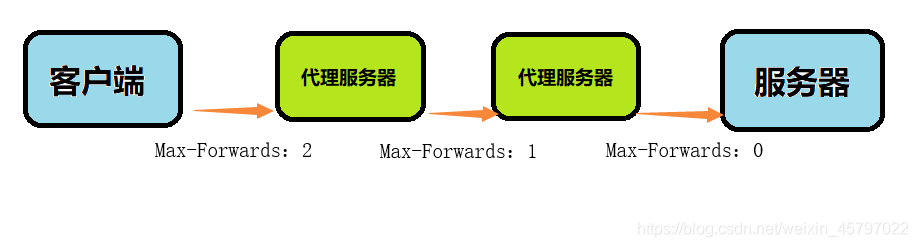
TRACE方法是让Web服务器端将之前的请求通信返回给客户端。客户端通过该方法可以查询发送出去的请求是怎样被加工修改/篡改的。这是因为,请求想要连接到源目标服务器可能会通过代理中转,TRACE方法就是用来确认连接过程中发生的一系列操作。
发送请求时,在Max-Forwards首部字段中填入数值,每经过一个服务器端就将该数字减1,当数值刚好减到0时,就停止继续传输,最后接收到请求的服务器端则返回状态码200 OK的响应。
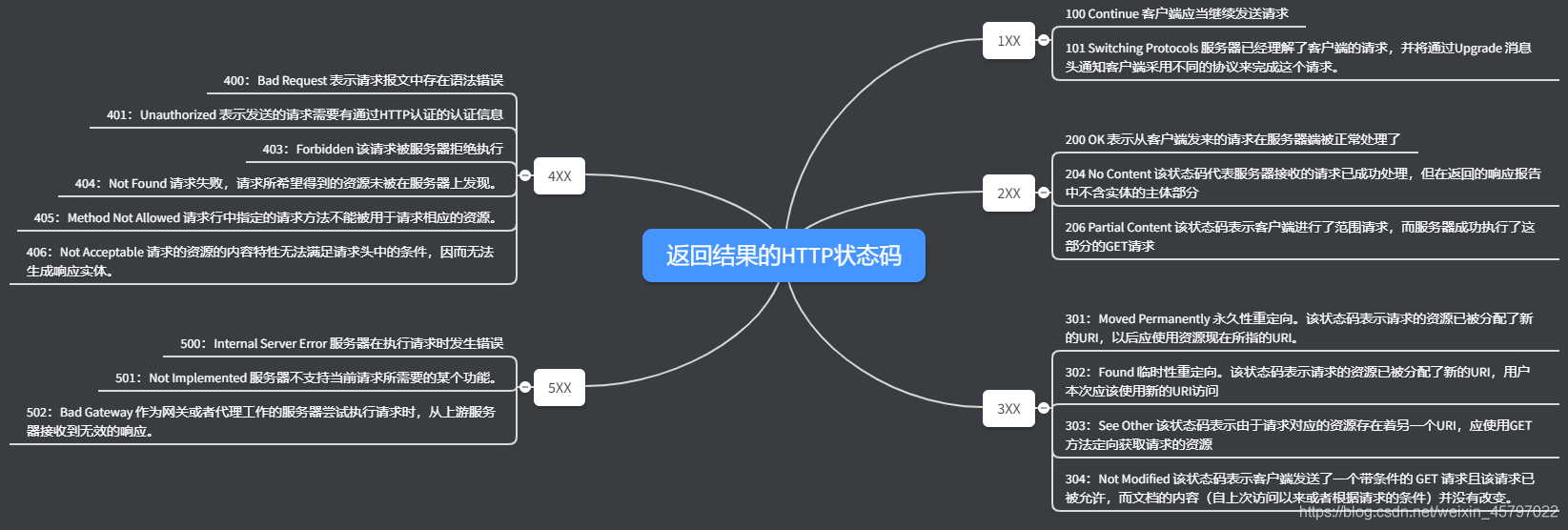
返回结果的HTTP状态码总结
HTTP状态码(HTTP Status Code)是用以表示网页服务器超文本传输协议响应状态的3位数字代码。其职责是当客户端向服务器发送请求时,描述返回的请求结果。借助状态码,用户可以知道服务器端是正常处理了请求,还是出现了错误。它由 RFC 2616 规范定义的,并得到 RFC 2518、RFC 2817、RFC 2295、RFC 2774 与 RFC 4918 等规范扩展。所有状态码的第一个数字代表了响应的五种类别后两位无分类,状态码是HTTP / 1.1标准(RFC 7231)的一部分。
微软互联网信息服务 (Microsoft Internet Information Services)有时会使用额外的十进制子代码来获取更多具体信息,但是这些子代码仅出现在响应有效内容和文档中,而不是代替实际的HTTP状态代码。
1开头的状态码表示消息
这一类型的状态码,代表请求已被接受,需要继续处理。这类响应是临时响应,只包含状态行和某些可选的响应头信息,并以空行结束。由于 HTTP/1.0 协议中没有定义任何 1xx 状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送 1xx 响应。
2开头的状态码表示成功
这一类型的状态码,代表请求已成功被服务器接收、理解、并接受。
3开头的状态码表示重定向
这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的 Location 域中指明。
4开头的是客户端错误状态码
这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。我们经常碰到的404 Not Found就属于这一种代码。除非响应的是一个 HEAD 请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容。
5、6开头的状态码表示服务器错误
这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。除非这是一个HEAD 请求,否则服务器应当包含一个解释当前错误状态以及这个状况是临时的还是永久的解释信息实体。浏览器应当向用户展示任何在当前响应中被包含的实体,这些状态码适用于任何响应方法。
除了600 Unparseable Response Headers表示源站没有返回响应头部,只返回实体内容,这一个状态码以外,其它都是5开头的状态码。
下图是我用一张思维导图将一些常见的状态码记录了下来。