Moving Data
Objectives
After completing this lesson, you should be able to:
• Describe ways to move data
• Explain the general architecture of Oracle Data Pump
• Create and use directory objects
• Use Data Pump Export and Import to move data between Oracle databases
• Use SQL*Loader to load data from a non-Oracle database (or user files)
• Use external tables to move data via platform-independent files
目标
完成本课程后,您应该能够:
•描述移动数据的方法
•解释Oracle数据泵的总体架构
•创建和使用目录对象
•使用数据泵导出和导入在Oracle数据库之间移动数据
•使用SQL*加载程序从非Oracle数据库(或用户文件)加载数据
•使用外部表通过独立于平台的文件移动数据
Moving Data: General Architecture 移动数据:通用体系结构

Oracle Data Pump: Overview
As a server-based facility for high-speed data and metadata movement, Oracle Data Pump:
• Is callable via DBMS_DATAPUMP
• Provides the following tools:
– expdp
– impdp
– GUI interface in Enterprise Manager Cloud Control
• Provides four data movement methods:
– Data file copying
– Direct path
– External tables
– Network link support
• Detaches from and re-attaches to long-running jobs
• Restarts Data Pump jobs
Oracle数据泵:概述
作为基于服务器的高速数据和元数据移动工具,Oracle data Pump:
•可通过DBMS U数据泵调用
•提供以下工具:
–出口产品开发计划
–impdp公司
–Enterprise Manager云控制中的图形用户界面
•提供四种数据移动方法:
–数据文件复制
–直接路径
–外部表格
–网络链接支持
•脱离并重新连接到长时间运行的作业
•重新启动数据泵作业
Oracle Data Pump: Benefits
Data Pump offers many benefits and many features, such as:
• Fine-grained object and data selection
• Explicit specification of database version
• Parallel execution
• Estimation of export job space consumption
• Network mode in a distributed environment
• Remapping capabilities
• Data sampling and metadata compression
• Compression of data during a Data Pump export
• Security through encryption
• Ability to export XMLType data as CLOBs
• Legacy mode to support old import and export files
Oracle数据泵:好处
数据泵提供许多优点和功能,例如:
•细粒度对象和数据选择
•明确说明数据库版本
•并行执行
•估算出口工作空间消耗
•分布式环境中的网络模式
•重新映射功能
•数据采样和元数据压缩
•数据泵导出期间的数据压缩
•通过加密实现安全性
•能够将XMLType数据导出为clob
•支持旧导入和导出文件的传统模式
Directory Objects for Data Pump 数据泵的目录对象
Creating Directory Objects 创建目录对象
SQL> create directory exp_dump as '/u01/'; 创建目录
Directory created.
Data Pump Export and Import Clients: Overview 数据泵导出和导入客户端:概述 (可通过此方式完成数据库升级操作,比如从11g升级到12c)
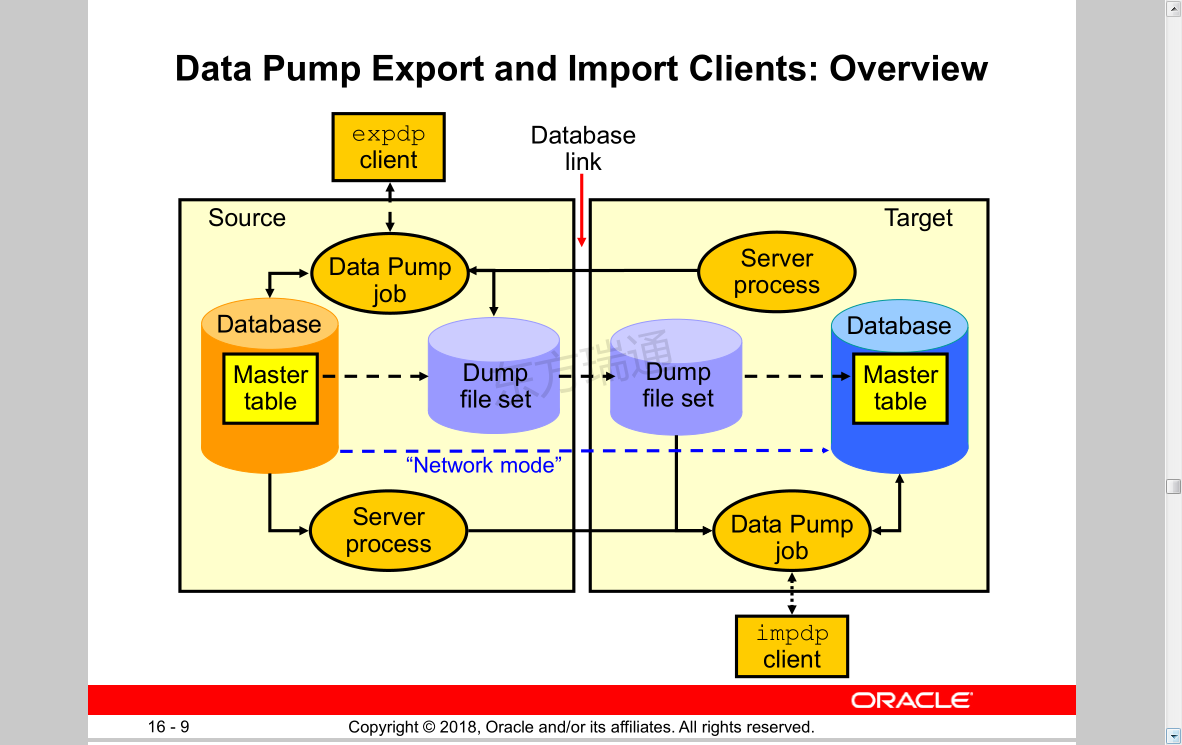
Data Pump Utility: Interfaces and Modes
• Data Pump Export and Import interfaces:
– Command line
– Parameter file
– Interactive command line
– Enterprise Manager Cloud Control
• Data Pump Export and Import modes:
– Full
– Schema
– Table
– Tablespace
– Transportable tablespace
– Transportable database
数据泵实用程序:接口和模式
•数据泵导出和导入接口:
–命令行
–参数文件
–交互式命令行
–Enterprise Manager云控制
•数据泵导出和导入模式:
–已满
–架构
–桌子
–表空间
–可传输表空间
–可移植数据库
Performing a Data Pump Export by Using Enterprise Manager Cloud Control 使用Enterprise Manager云控制执行数据泵导出 (可用schema方式导出)
SQL> select * from job_history; 查看表是否存在
[oracle@yf u01]$ expdp system directory=exp_dump dumpfile=exp_hr.dmp logfile=hr_exp.log schemas=hr
[oracle@yf u01]$ expdp数据库导出导入工具 system用户名 directory目录对象=exp_dump刚才创建的目录对象 dumpfile=exp_hr.dmp指定dmp文件的名称 logfile=hr_exp.log指定日志文件名称 schemas=hr指定导出的方式和名称
Export: Release 18.0.0.0.0 - Production on Sat Jun 27 21:24:03 2020
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Password: 输入用户口令
[oracle@yf u01]$ cd /u01
[oracle@yf u01]$ ls *.log
hr_exp.log
[oracle@yf u01]$ more hr_exp.log 查看新生成的log文件
[oracle@yf u01]$ ls *.dmp
[oracle@yf u01]$ sqlplus hr/hr
SQL> drop table job_history purge; 模拟表被误删除
Table dropped.
SQL> select * from job_history;
select * from job_history 表已经不在了
*
ERROR at line 1:
ORA-00942: table or view does not exist
[oracle@yf ~]$ impdp system directory=exp_dump dumpfile=exp_hr.dmp logfile=imp_hr.log tables=hr.job_history
[oracle@yf ~]$ impdp导入工具 system用户名 directory=exp_dump目录对象名称 dumpfile=exp_hr.dmp文件名 logfile=imp_hr.log日志文件名 tables=hr.job_history需要导入的表
Import: Release 18.0.0.0.0 - Production on Sat Jun 27 21:53:26 2020
Version 18.3.0.0.0
Copyright (c) 1982, 2018, Oracle and/or its affiliates. All rights reserved.
Password:
Connected to: Oracle Database 18c Enterprise Edition Release 18.0.0.0.0 - Production
Master table "SYSTEM"."SYS_IMPORT_TABLE_01" successfully loaded/unloaded
Starting "SYSTEM"."SYS_IMPORT_TABLE_01": system/******** directory=exp_dump dumpfile=exp_hr.dmp logfile=imp_hr.log tables=hr.job_history
Processing object type SCHEMA_EXPORT/TABLE/TABLE
Processing object type SCHEMA_EXPORT/TABLE/TABLE_DATA
. . imported "HR"."JOB_HISTORY" 7.187 KB 10 rows 导入成功
Processing object type SCHEMA_EXPORT/TABLE/GRANT/OWNER_GRANT/OBJECT_GRANT
Processing object type SCHEMA_EXPORT/TABLE/COMMENT
Processing object type SCHEMA_EXPORT/TABLE/INDEX/INDEX
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/INDEX/STATISTICS/INDEX_STATISTICS
Processing object type SCHEMA_EXPORT/TABLE/CONSTRAINT/REF_CONSTRAINT
Processing object type SCHEMA_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS
Processing object type SCHEMA_EXPORT/STATISTICS/MARKER
Job "SYSTEM"."SYS_IMPORT_TABLE_01" successfully completed at Sat Jun 27 21:53:54 2020 elapsed 0 00:00:22
Performing a Data Pump Import
Data Pump can be invoked on the command line:
执行数据泵导入
可以在命令行上调用数据泵:
$ impdp hr DIRECTORY=DATA_PUMP_DIR \
DUMPFILE=HR_SCHEMA.DMP \
PARALLEL=1 \
CONTENT=ALL \
TABLES="EMPLOYEES" \
LOGFILE=DATA_PUMP_DIR:import_hr_employees.log \
JOB_NAME=importHR \
TRANSFORM=STORAGE:n
Data Pump Import: Transformations
You can remap:
• Data files by using REMAP_DATAFILE
• Tablespaces by using REMAP_TABLESPACE
• Schemas by using REMAP_SCHEMA
• Tables by using REMAP_TABLE
• Data by using REMAP_DATA
数据泵导入:转换
您可以重新映射:
•使用REMAP_DATAFILE的数据文件
•使用REMAP_表空间的表空间
•使用重新映射模式的模式
•使用REMAP_TABLE的表
•使用重新映射数据的数据
REMAP_TABLE = 'EMPLOYEES':'EMP'
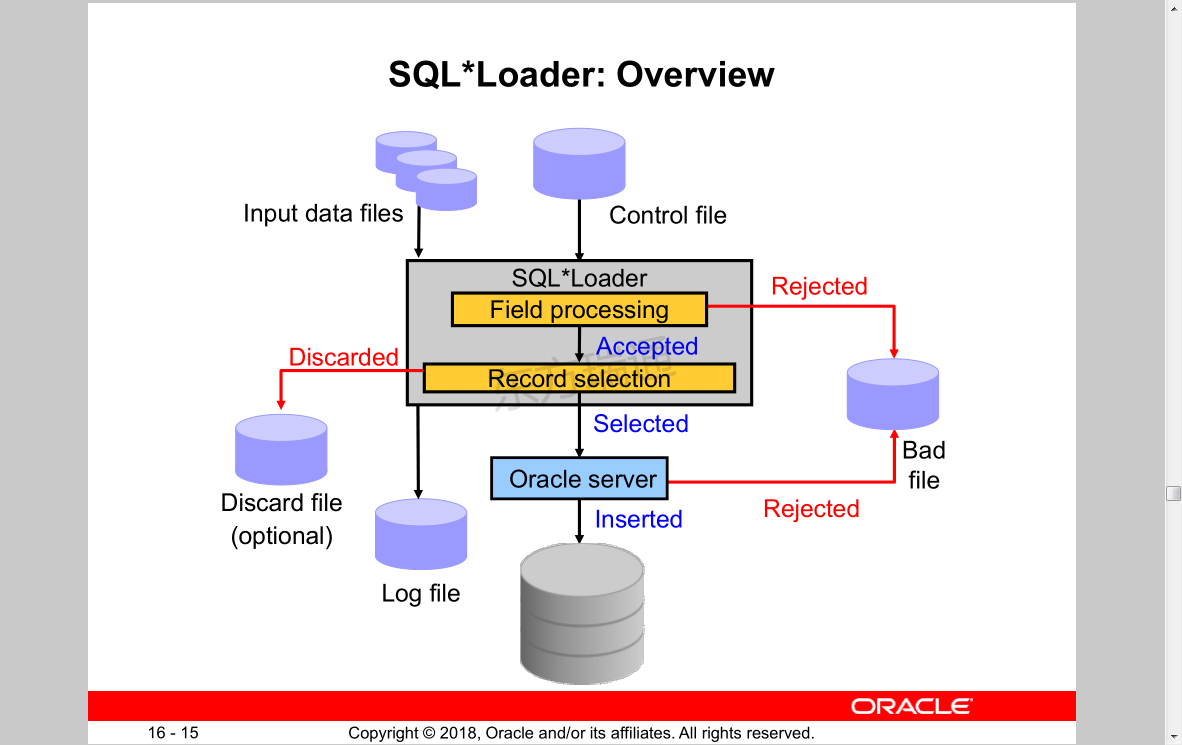
SQL*Loader: Overview