上篇我们了解到并发编程的共享模型,即同一父进程下的其他子线程会共享父进程的资源,并且子线程在共享资源进行写操作时,可能导致不可预料的错误。那么为什么会导致这样的错误呢?有没有办法解决这样的问题呢?要解决这些问题,就要了解java的内存模型。在学习java内存模型之前,我们先要了解什么是内存模型。
内存模型(Memory Model)
为什么要有内存模型
我们知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。程序运行时的数据是存放在主存当中的,也就是计算机的物理内存。刚开始,大家相安无事,但是随着CPU技术的发展,CPU执行速度越来越快,而内存的技术变化不大,内存执行的速度已经远远落后于CPU,这样每次内存和CPU之间交换数据时,CPU都会耗费大量的时间来等待内存的读写操作。
为了解决CPU和内存执行速度的不同带来的资源浪费,人们想出了高速缓存的解决办法。即当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,CPU进行计算时直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。因为高速缓存的执行速度明显快于内存,这样就减少了CPU资源的浪费。
随着CPU能力的不断提升,一层缓存就慢慢的无法满足要求了,就逐渐的衍生出多级缓存。按照数据读取顺序和与CPU结合的紧密程度,CPU缓存可以分为一级缓存(L1),二级缓存(L3),部分高端CPU还具有三级缓存(L3),每一级缓存中所储存的全部数据都是下一级缓存的一部分。这三种缓存的技术难度和制造成本是相对递减的,所以其容量也是相对递增的。当CPU要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找。
为了提升计算机的执行效率,开始出现了单线程到多线程,单核CPU到多核CPU的转变。这就可能导致缓存一致性的问题,它们可能出现的情况如下:
单线程:始终只有一个线程占有CPU,一个线程执行完才会执行另一个线程,CPU与缓存之间的数据交换不会出现错误。
多线程:多个线程会竞争CPU,每个线程都会将需要的数据拷贝到缓存中,但是缓存在写回内存时,就会出现数据覆盖的情况。比如:线程1读取数据a=0,此时线程1的时间片用完,线程2也读取a=0,然后线程1把a的值修改为1,,线程2将a的值修改为-1,这时缓存中a的值并不相同,在写回内存时必然出现数据的覆盖。这就是缓存一致性问题。
处理器优化:上面提到在在CPU和主存之间增加缓存,在多线程场景下会存在缓存一致性问题。除了这种情况,还有一种硬件问题也比较重要。那就是为了使处理器内部的运算单元能够尽量的被充分利用,处理器可能会对输入代码进行乱序执行处理。这就是处理器优化。
重排序
编译器和处理器在执行程序时并不一定按照代码的顺序执行,而是为了更加符合CPU的执行特性,最大限度的发挥机器的性能,提高程序的执行效率,对指令进行了重排序。但是重排序必然不能在某些特定情况下进行,否则程序运行结果肯定会出现问题。我们根据数据的依赖性来区分这些情况,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。
数据依赖性:如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖性。
| 名称 | 代码示例 | 说明 |
| 写后读 | a = 1;b = a; | 写一个变量之后,再读这个位置。 |
| 写后写 | a = 1;a = 2; | 写一个变量之后,再写这个变量。 |
| 读后写 | a = b;b = 1; | 读一个变量之后,再写这个变量。 |
注意,这里所说的数据依赖性仅针对单个处理器中执行的指令序列和单个线程中执行的操作,不同处理器之间和不同线程之间的数据依赖性不被编译器和处理器考虑。

as-if-serial 语义:不管怎么进行指令重排序,单线程内程序的执行结果不能被改变。编译器,处理器进行指令重排序都必须要遵守as-if-serial语义规则。
为了遵守 as-if-serial 语义,编译器和处理器对存在依赖关系的操作,都不会对其进行重排序,因为这样的重排序很可能会改变执行的结果,但是对不存在依赖关系的操作,就有可能进行重排序。通过下面的程序来说明:
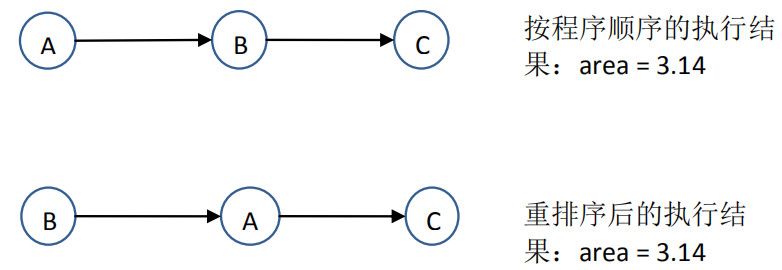
double pi = 3.14; //A double r = 1.0; //B double area = pi * r * r; //C
上面三个操作的数据依赖关系如下图

A 和 C 之间存在数据依赖关系,同时 B 和 C 之间也存在数据依赖关系。因此在最终执行的指令序列中,C 不能被重排序到 A 和 B 的前面(C 排到 A 和 B 的前面,程序的结果将会被改变)。但 A 和 B 之间没有数据依赖关系,编译器和处理器可以重排序 A 和 B 之间的执行顺序。下图是该程序的两种可能的执行顺序