动态关联,前一个接口返回的值为后一个接口请求的参数。
# 动态关联
import requests
def test_cookies():
# 以百度为例
r_baidu=requests.get('https://www.baidu.com/')
print(r_baidu.cookies)

直接获取的cookies,似乎是这个值。这个是Request Cookies
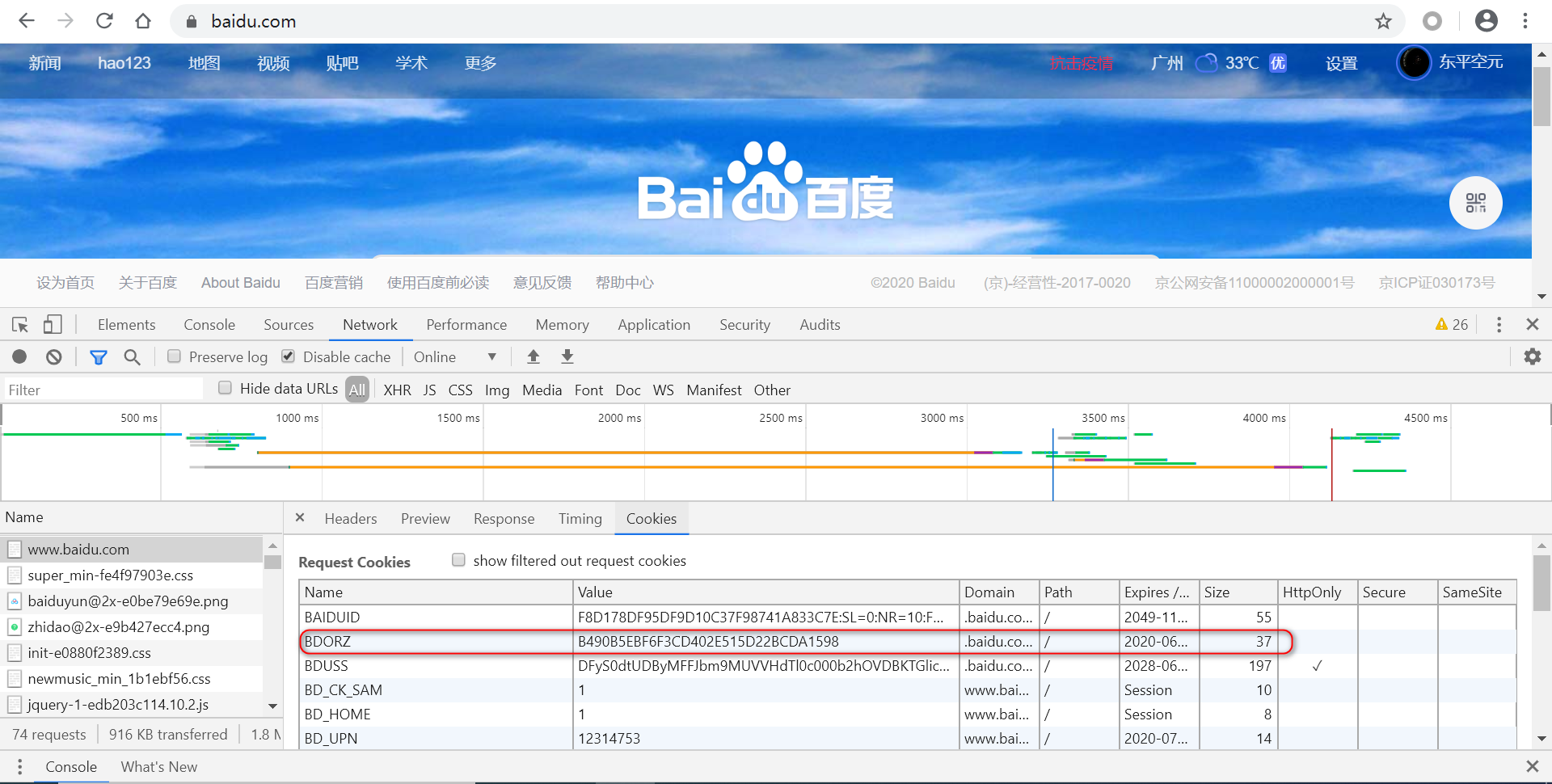
提取text格式内容
以前程无忧为例
- 查看响应返回的数据格式

- 提取url
import requests
import re # 正则表达式库,python自带的库
def test_text():
# 返回响应是text格式,使用正则表达式提取其中的值,以前程无忧为例,前程无忧搜索不需要cookies,不需要headers
url_51='https://search.51job.com/list/030200,000000,0000,00,9,99,%25E8%25BD%25AF%25E4%25BB%25B6%25E6%25B5%258B%25E8%25AF%2595%25E5%25B7%25A5%25E7%25A8%258B%25E5%25B8%2588,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare='
r_51=requests.get(url=url_51) #前程无忧搜索不需要cookies,不需要headers
r_51.encoding='gb2312' # 设置编码格式,不然会乱码
# print(r_51.text)
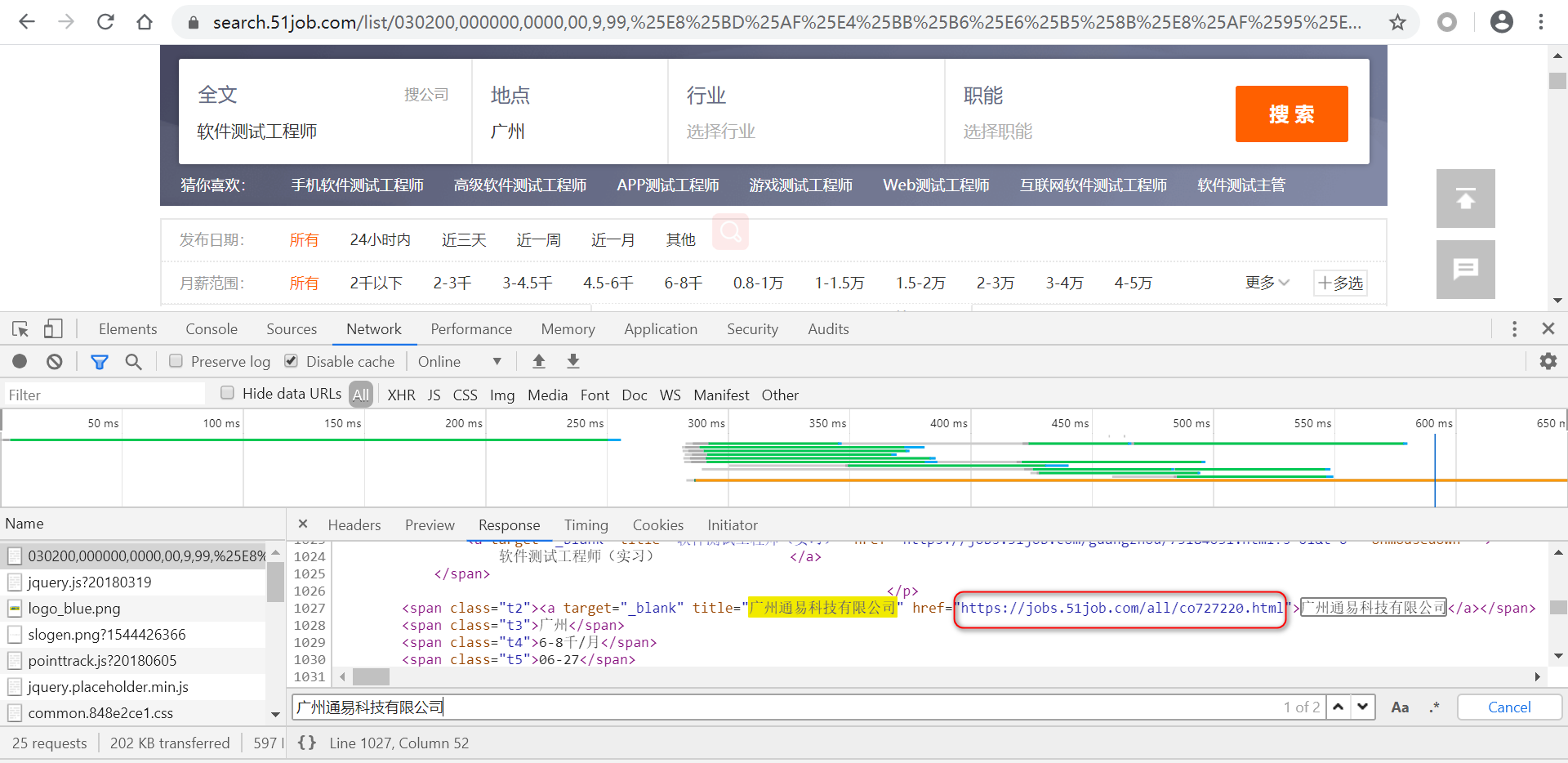
# "广州通易科技有限公司" href="https://jobs.51job.com/all/co727220.html">广州通易科技有限公司,把url提取出来
url_ty=re.findall('title="广州通易科技有限公司" href="(.+?)">广州通易科技有限公司',r_51.text)
print(url_ty[0])
# 访问新的url
r_ty=requests.get(url=url_ty[0]) # 提取出来的是列表,所以取第一个
r_ty.encoding='gb2312'
print(r_ty.text)
# requests.exceptions.ConnectionError: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
提取json格式内容
12306返回的是json格式