一、前言
KMP,字符串匹配算法,由D.E.Knuth、J,H,Morris 和 V.R.Pratt三位大佬共同提出,所以叫KMP算法。该算法相对于幼稚算法来说消除了主串比较指针回溯,故而使算法效率有了提升。
二、PMT(Partial Match Table)
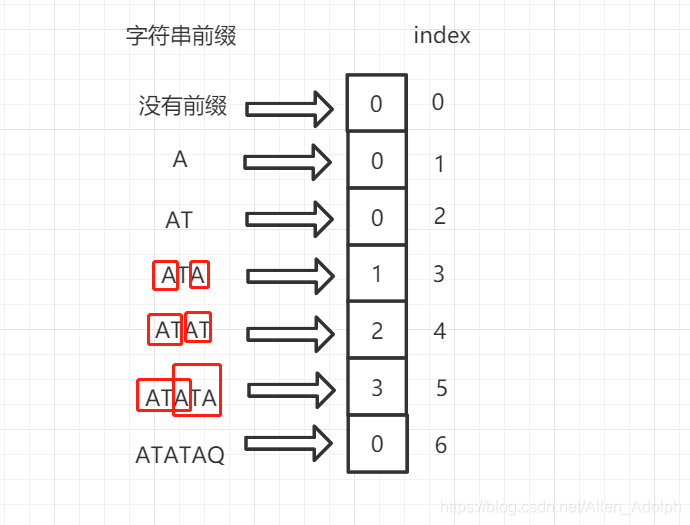
KMP算法的核心可以说是PMT,PMT全称Partial Match Table,即部分匹配表。举个例子,对于模式串 ATATAQF 有如下PMT表:

PMT中对应的值是字符串前缀集合与后缀集合中交集中的最长元素的长度。
例如对于 ABCABC 这个串来说,它有前缀集合{"A", "AB", "ABC", "ABCA", "ABCAB"},有后缀集合{"BCABC", "CABC", "ABC", "BC", "C"}。
对于这个串的前缀集合和后缀集合来说,它们间的交集就是{"ABC"},所以它所对应的PMT表中的值就是3。
现在来说上面那张对于模式串 ATATAQF 的 PMT 表,当模式串子串只有A时,它没有前缀与后缀,只有"A"一个字符,所以PMT表中的值为0;
当模式串子串为"AT"时,前缀为"A",后缀为"T",它们间没有交集,所以PMT表中对应的值为0;
当模式串子串为"ATA"时,前缀集合为{"A", "AT"},后缀集合为{"TA", "A"},它们间的交集为"A",所以PMT表中值为1;
当模式串子串为"ATAT"时,前缀集合为{"A", "AT", "ATA"},后缀集合为{"TAT", "AT", "T"},它们间交集为"AT",所以PMT表中值为2;
当模式串子串为"ATATA"时,前缀集合为{"A", "AT", "ATA", "ATAT"},后缀集合为{"TATA", "ATA", "TA", "A"},它们间交集为{"A", "ATA"},交集中最长者为"ATA",所以对应PMT表中的值为3;
…
三、KMP算法
下图是我们传统的幼稚算法的过程,主串和模式串从头开始匹配,当匹配到坏字符串时,主串的指针(下图中的i)就要回溯到上次开始匹配字符的下一位,再与模式串中的第一位数开始比较,这种行为叫做主串比较指针回溯,这样造成的影响就是效率下降。
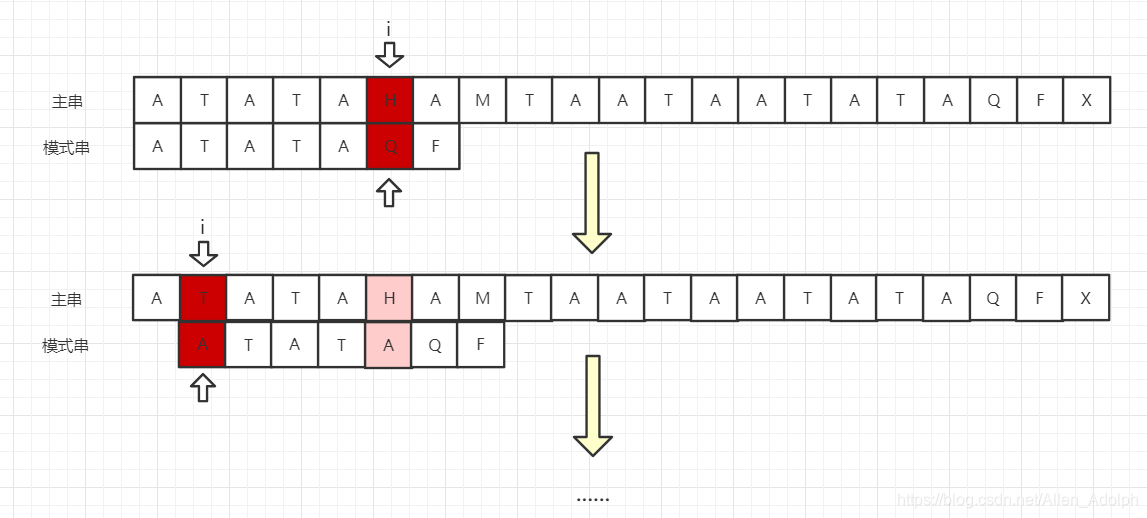
但是我们可以很清楚的了解到,主串的指针回溯后必然会回到回溯前的位置的,因为那个位置还是要比较的啊,下一次的主串的"H"还是需要和模式串中的"A"进行比较的。
既然主串中的指针必然会回到回溯前的位置,那么我们可不可以使主串中的指针不回溯呢?答案是可以的,利用我们上面所提到的PMT表即可。
我们可以发现,字符"Q"前面有最长可匹配前缀子串和最长可匹配后缀子串,两者是相同,为"ATA"。

但我们进行下一轮比较的时候,必须将这对子串对齐成功,才有可能出现匹配。所以我们下一次进行匹配的时候,就可以不需要将主串指针回溯了,直接将模式串向后移动两位,使得"ATA"直接对齐,然后才从刚刚匹配到的坏字符串处开始比较,如下图:

同样的,此时"H"和"A"比较失败,那么"T"前面有没有最长匹配前缀后缀子串呢,答案是有,即"A"。所以下次匹配,直接将模式串后移两位,使得两个"A"对齐:

然后再从坏字符串处开始比较,这就是KMP算法的整体思路:在已经匹配到的前缀子串中寻找到最长可匹配后缀子串和最长可匹配前缀子串,在下一轮把两者直接对齐,从而免去主串指针回溯,只需要模式串中指针按规律回溯,实现算法效率提升。
四、next数组的求解
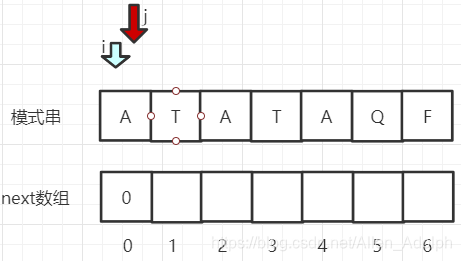
next数组是个啥,next数组用来存储最长可匹配前缀子串的下一个位置,例如前面我们第一次匹配的时候,“ATATAQF"到"Q"这里匹配失败,那么到Q这里的最长可匹配前缀子串就是"ATA”,它的下一个位置就是"3"。所以,第二次比较时i指针可以不懂,而下面模式串的指针只需要移动到模式串下标为3处即可(淦,为什么我画图的时候不给下面指针加个名字呢 QAQ)。我们用图来看一下next数组:
了解完next数组后,我们还得了解next数组是如何求出来的,我们常规的算法就是从最长的前缀子串开始,将每一种情况都做一次比较,但是这样时间复杂度就上升了,不太合适。
所以这里我们采用DP动态规划算法,首次我们易知next数组的下标为0和为1处的值为0,所以可以通过next[0]和next[1]往后推导,这个过程具体如下:
- 首先我们需要两个指针,i指针代表”已匹配前缀的下一个位置“,j指针代表”最长可匹配前缀子串的下一个位置“。
-
之后i指针一直向后移动,然后与j指针所指的元素比较,若相等则j指针也往后移动一位,不相等则j指针还是留在原地。同时给next数组赋值(下面有代码,看代码理解好不)。
就这样一直到i指针从2开始后,即第三个字符"A"的时候,开始与j指针所指的"A"匹配,然后i指针和j指针一直向后移动,继续匹配,一直匹配到i指针指向Q时,"ATA"前缀匹配到"ATA"后缀,此时j指针在第四个字符"T"上,此时的匹配是不成功的:
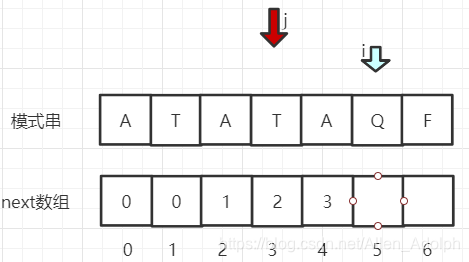
- 然后就需要让j回溯了,但是我们没必要直接将j指针回溯第一位,或者一位一位的往前回溯,因为前面已经匹配到了相同前缀字符串。我们可以将"ATATAQ"问题转换为"ATAQ"问题(相同的串你有必要匹配两次吗?当然是从中间不相同的串开始啦。),如下入所示:
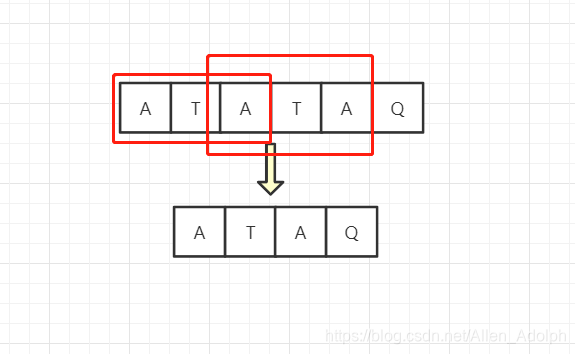
所以只需要让指针回溯到第三个字符处,具体看代码实现吧。不上图了淦,好难画,复习的时候应该能看懂吧。
代码演示:
/**
* KMP算法主体逻辑,str是主串,pattern是模式串
*
* @param str 主串
* @param pattern 模式串
* @return
*/
public static int kmp(String str, String pattern) {
// 预处理,生成next数组
int[] next = getNextArr(pattern);
int j = 0;
// 主循环,遍历主主字符串
for (int i = 0; i < str.length(); i++) {
while(j > 0 && str.charAt(i) != pattern.charAt(j)) {
// 遇到坏字符串,查询next数组并改变模式串的起点
j = next[j];
}
if (str.charAt(i) == pattern.charAt(j)) {
j ++;
}
if (j == pattern.length()) {
// 匹配成功,返回下标
return i - pattern.length() + 1;
}
}
return -1;
}
// 算法实现使用到了动态规划
private static int[] getNextArr(String pattern) {
int[] next = new int[pattern.length()];
int j = 0;
for (int i = 2; i < pattern.length(); i++) {
while(j != 0 && pattern.charAt(j) != pattern.charAt(i - 1)) {
// j 指针从 next[i + 1] 回溯到 next[j]
j = next[j];
}
if (pattern.charAt(j) == pattern.charAt(i - 1)) {
j ++;
}
next[i] = j;
}
return next;
}
public static void main(String[] args) {
String str = "";
String pattern = "";
int index = kmp(str, pattern);
System.out.println(pattern + "在" + str + "中首次出现的位置为:" + index);
}
最后算法的空间复杂度为O(m),时间复杂度为O(m+n)。