项目概述
本项目案例根据某法律咨询服务网站的用户浏览记录,把用户划分为训练集的用户和测试集的用户,再根据找出相应用户的浏览记录划分为训练集数据和测试集数据。训练集用于后续构建用户物品矩阵,再根据用户物品矩阵构建物品相似度矩阵(根据杰卡德相似系数公式计算物品相似度);测试集用于根据用户浏览记录给用户推荐用户可能感兴趣的网页,在计算推荐结果准确度的时候需要根据测试集构建用户浏览字典(键:ip,值:url(列表))
案例的代码已经托管到码云仓库,可自行进行下载:https://gitee.com/atuo-200/recommend_code
案例用的的数据文件已经上传至百度云(单个文件超过100m push不上码云):
链接:https://pan.baidu.com/s/1S4W1Xu3kTOC8_90Yj-fqvw
提取码:v7ht
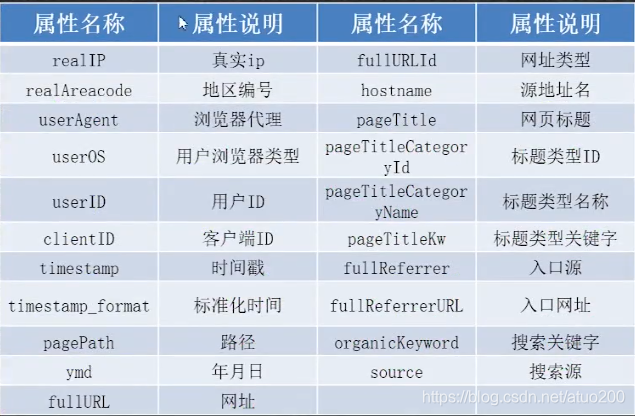
案例用到的数据文件中的字段含义如下:
案例代码
案例代码如下,代码上已经附上相应的注释
data_explore.py(用于数据探索,独立的一个模块)
import pandas as pd
import re
"""数据探索模块"""
data = pd.read_csv("data/all_gzdata.csv",encoding="gb18030")
#查看前5条数据
print(data.head())
#查看数据有哪些列
print(data.columns)
#查看有多少条数据
print(data.shape)
#查看网址类型
print(data["fullURLId"])
#网址类型统计:统计每种网址类型的数量
print("-----------------------")
urlId=['101','199','107','301','102','106','103']
count=[]
for pattern in urlId:
index=[sum(re.search(pattern,i)!=None for i in data.loc[:,'fullURLId'].apply(str))][0]
count.append(index)
urlId_count={'urlId':urlId,'count':count}
urlId_count=pd.DataFrame(urlId_count)
print(urlId_count)
print("-----------------------")
# 用户点击次数统计
# pd.value_counts() 属于高级方法,返回一个 Series ,其索引值为唯一值,其值为频率,按其计数的降序排列
res = data.loc[:, 'realIP'].value_counts() # 对 IP 进行统计:每个 IP 点击了多少次
res1 = res.value_counts() # 对点击次数的 IP 统计:例如点击了 2 次的 ip 有多少个
IP_count = pd.DataFrame({'a_IP': list(res1.index), 'count': list(res1)})
IP_total = sum(IP_count.iloc[:, 1])
#IP_count.ix[:, 'pers'] = [index / IP_total for index in IP_count.ix[:, 1]]
IP_count['pers'] = IP_count.iloc[:, 1] / sum(IP_count.iloc[:, 1])
print(IP_count.head())
print("-----------------------")
#统计网页点击率的排名情况
res2=data.loc[:,'fullURL'].value_counts()
URL_Frame=pd.DataFrame({'a_URL':list(res2.index),'count':list(res2)})
print(URL_Frame.head())
print("-----------------------")
#对网页的点击次数进行统计
res3=data.loc[:,'fullURL'].value_counts()
res4=res3.value_counts()
URL_count=pd.DataFrame({'a_URL':list(res4.index),'count':list(res4)})
URL_total=sum(URL_count.iloc[:,1])
URL_count.loc[:,'pers']=[index/URL_total for index in URL_count.iloc[:,1]]
print(URL_count.head())
data_process.py(用于数据预处理,对数据进行相应的抽取、删减、转换,构建用户物品列表)
import pandas as pd
def data_process(file='data/all_gzdata.csv', encoding='GB18030'):
data = pd.read_csv(file, encoding=encoding)
# 去除非html网址;
data = data.loc[data['fullURL'].str.contains('\.html'), :]
# 去除咨询发布成功页面
data = data[data['pageTitle'].str.contains('咨询发布成功')==False]
# 去除中间类型网页(带有midques_关键字);
data[~data['fullURL'].str.contains('midques_')]
# 对带?的网址进行截取还原
index1 = data['fullURL'].str.contains('\?')
data.loc[index1, 'fullURL'] = data.loc[index1, 'fullURL'].str.replace('\?.*', '')
# 去除律师的行为记录(通过法律快车-律师助手判断);
data = data[data['pageTitle'].str.contains('法律快车-律师助手')==False]
# 去除不是本网址的数据(网址不包含lawtime关键字)
data = data[data['fullURL'].str.contains('lawtime')]
# 去除重复数据(同一时间同一用户,访问相同网页)。
data.drop_duplicates(inplace=True)
# 对翻页网址进行还原
index2 = data['fullURL'].str.contains('\d_\d+\.html')
data.loc[index2, 'fullURL'] = data.loc[index2, 'fullURL'].str.replace('_\d+\.html', '.html')
# 取出婚姻类型数据,取其中的ip和url字段
index3 = data['fullURL'].str.contains('hunyin')
data_hunyin = data.loc[index3, ['realIP', 'fullURL']]
#再去重,有必要(翻页网址还原后又出现了重复数据)
data_hunyin.drop_duplicates(inplace=True)
#类型转换
data_hunyin.loc[:, "realIP"] = data_hunyin.loc[:,"realIP"].apply(str)
return data_hunyin
data_split.py(导入数据预处理后的数据(用户物品列表),用于数据集的划分)
from data_process import data_process
from random import sample
data = data_process() # 导入经过清洗后的婚姻数据集
def trainTestSplit(data=data, n=2):
ipCount = data['realIP'].value_counts() # 统计每个用户的网页浏览数
# 找出浏览网页数在2次以上的用户IP
# 为什么要删除只有一次浏览记录的用户记录?因为该用户如果用于测试集不能验证推荐准确度,用于训练集无意义,这是增大计算成本
reaIP = ipCount[ipCount > n].index
ipTrain = sample(list(reaIP), int(len(reaIP)*0.8)) # 训练集用户(80%的ip用作训练训练集)
ipTest = [i for i in list(reaIP) if i not in ipTrain] # 测试集用户(20%的ip用作训练训练集)
index_tr = [i in ipTrain for i in data['realIP']] # 训练用户浏览记录索引,返回True或False
index_te = [i in ipTest for i in data['realIP']] # 测试用户浏览记录索引,返回True或False
print(index_tr)
dataTrain = data[index_tr] # 训练集数据(后续用于构建用户物品矩阵)
dataTest = data[index_te] # 测试集数据(后续用于推荐)
return dataTrain, dataTest
jaccard.py(计算杰卡德相似系数的公式封装)
import numpy as np
def jaccard_func(data=None):
te = -(data-1) # 将用户物品矩阵的值反转
dot1 = np.dot(data.T, data) # 任意两网址同时被浏览次数(交集)
dot2 = np.dot(te.T, data) # 任意两个网址中只有一个被浏览的次数
dot3 = dot2.T+dot2 # 任意两个网址中至少一个被浏览的次数(并集)
cor = dot1/(dot1+dot3) # 根据杰卡德相似系数公式,计算杰卡德相似系数
for i in range(len(cor)): # 将对角线值处理为零
cor[i, i] = 0
return cor
main.py(程序的主入口)
from data_split import trainTestSplit
import pandas as pd
from jaccard import jaccard_func
data_tr, data_te = trainTestSplit()
def main():
# 取出训练集用户的IP与浏览网址
ipTrain = list(set(data_tr['realIP']))
urlTrain = list(set(data_tr['fullURL']))
#构建用户物品矩阵构建
te = pd.DataFrame(0, index=ipTrain, columns=urlTrain)
for i in data_tr.index:
te.loc[data_tr.loc[i, 'realIP'], data_tr.loc[i, 'fullURL']] = 1
#构建物品相似度矩阵
cor = jaccard_func(te)
cor = pd.DataFrame(cor, index=urlTrain, columns=urlTrain)
#构建测试集用户网址浏览字典
ipTest = list(set(data_te['realIP']))
print(len(ipTest))
dic_te = {ip: list(data_te.loc[data_te['realIP'] == ip, 'fullURL']) for ip in ipTest}
print(len(dic_te))
#构建推荐矩阵
#开始推荐,rem第一列为测试集用户IP,第二列为已浏览过网址,第三列为相应推荐网址,第四列为推荐是否有效
rem = pd.DataFrame(index=range(len(data_te)), columns=['IP', 'url', 'rec', 'T/F'])
rem['IP'] = list(data_te['realIP'])
rem['url'] = list(data_te['fullURL'])
for i in rem.index:
if rem.loc[i, 'url'] in urlTrain:
rem.loc[i, 'rec'] = urlTrain[cor.loc[rem.loc[i, 'url'], :].argmax()] # 推荐的网址
rem.loc[i, 'T/F'] = rem.loc[i, 'rec'] in dic_te[rem.loc[i, 'IP']] # 判定推荐是否准确
#计算推荐准确度,根据测试集用户网址浏览字典
p_rec = sum(rem['T/F'] == True)/(len(rem) - sum(rem['T/F'] == 'NAN'))
return p_rec
p_rec = main()
print(p_rec)
运行结果如下