=========================================================================
前情提要
哈哈题目标题党了,其实我也是个学习的小白,这是学习记录,共勉 。
微语:慢下来,你才能走得更快。如今的我已经慢慢理解其中的道理了,好了废话不多说,直接进入主题。索引,一个高大上的名词,通俗来说就是目录,通过它能快速定位到你查找的位置。
索引常用数据结构以及B+树
常用数据结构
首先了解索引之前需要先了解哈希表、有序数组和搜索树。
-
Hash表这种数据结构底层是由数组实现的。通过Hash算法把对应的key值转化成相应的数组下标,value值则存放在数组的这个位置。Hash算法的实现很复杂,经过它的换算,Hash值一般不会相等,但数据多了之后就难以避免了,这个时候就需要解决Hash冲突。解决Hash冲突有两种方法,一种是开放寻址法,另外一种就是链表法。开放寻址法这里就不概述了,重点来看看链表法,其实就是把相同Hash值对应的value值存放到链表中。查找的时候就遍历链表得到数据。
缺点:经过Hash算法算出来的数据一般都不是递增有序的,所以在进行范围区间查询的时候,需要把每个数据都搜索一遍,这个是比较慢的。
应用场景:适合等值查询,NoSQL引擎。 -
有序数组,顾名思义就是排序的数组,这种结构在等值查询和范围查询都是十分优秀的。可以利用二分法快速查找到数据,但是数组虽然查找速度很快,但是他有个明显的缺点,就是插入数据的时候,为了保持数组有序,需要进行大量的数据搬移,这个效率就很低了。
应用场景:适合静态存储引擎,就是不怎么更新数据 -
搜索树,二叉搜索树特点是按照中序遍历可以得到从小到大的排序,因为它的左子节点小于父节点,而父节点又小于它的右子节点,二叉搜索树的搜索速度很快,但是同理,当你插入数据的时候,也需要考虑去维持这颗二叉搜索树的平衡。不过二叉树的应用场景很少,其原因就是因为它的树高,当数据很多的时候,二叉树的树高将会很高。索引不止存在内存中,还存在磁盘中,当树高很高的时候,就意味着,查询要去访问很多的数据块,这个操作是极其耗时的。为了少读磁盘,这个时候就应该使用多叉树。以InnoDB为例,这个多是1200,当树的高度为4的,差不多已经可以存储17亿的数据,一般来说数根节点都是放在内存中的,所以查找这个17亿的数据,只需要访问三次磁盘即可,这样就可以大大提高效率。
多叉树优点:读写性能快,适配磁盘访问方式,所以被广泛应用在数据库引擎中。
数据库底层的存储基本上都是基于上述的模型。
说完了数据模型,接下来进入正题。Mysql的索引是在存储引擎中实现的,所以就说明没有统一的标准,不同引擎有自己不同的工作方式。
InnoDB的索引模型
在InnoDB中,表以主键顺序为索引的形式存放的,InnoDB的数据都是存储在B+树中的。每个索引就对应一颗B+树。
B+树的特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
B+树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询。
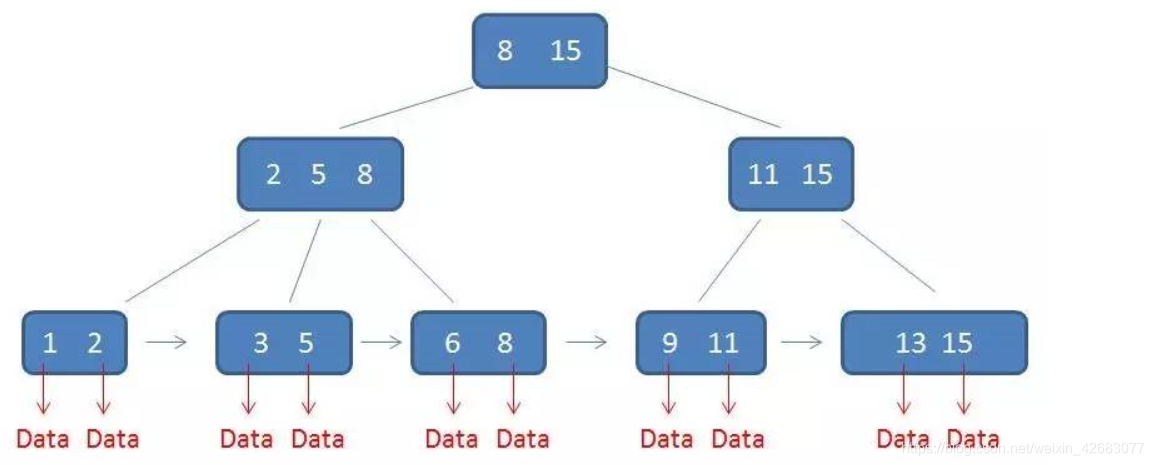
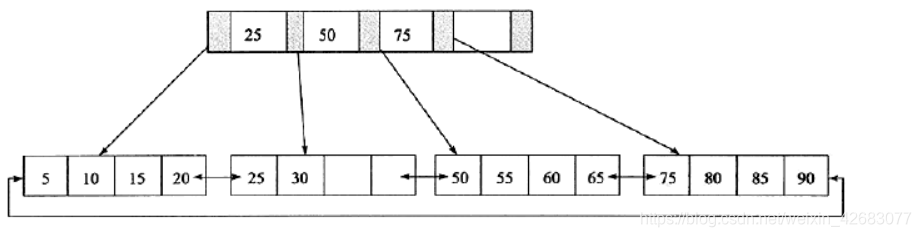
B+树和二叉树、平衡二叉树一样都是经典的数据结构。B+树中,所有记录节点都是按键值的大小顺序存放在同一层的叶子节点上,由各叶子节点指针进行连接。
如下图:
示例:以字段a为索引的建表语句
create table T(
id int primary key,
a int not null,
name varchar(16),
index(a) engine = InnoDB;
)这里又引出两个概念:
- 主键索引:主键索引的叶子节点存的是整行数据。在InnoDB中,主键索引也被称为聚簇索引
- 非主键索引:非主键索引的叶子节点存放的是主键的值,在InnoDB中,非主键索引被称为二级索引
这里举个例子来说明上述两个概念,比如一条SQL语句,SELECT * FROM T WHERE ID = 1
这种主键查询方式,则只会去搜索ID这颗B+树。如果是SELECT * FROM T WHERE a = 1;这个非主键索引,就会先根据a这个索引找到主键的值,再拿着主键的值去主键的b+树查询数据。这种方式成为回表。
索引的维护
在InnoDB中,B+树要保持索引的有序性,所以在插入新值的时候要对B+树进行维护。
维护分为以下几种情况:
- 索引值最大的时候,直接插入到末尾。
- 索引值在中间的时候,这个时候就比较麻烦,需要搬动数据。搬动数据的时候,可能会出现页数据已经满的情况,这个时候就需要申请一个新的数据页,并把数据挪过去。这种就称为页分裂。页分裂操作会引起性能的降低和数据页的利用率。有页分裂的同时就有页合并,当两个页删除了数据的时候,利用率变得很低,这个时候就会对页进行合并。
自增主键可以在一定程度避免这种数据分页情况的发生,一般来说采用自增主键是合理选择,长度小普通索引的叶子节点就越小,普通索引占用的空间也就越小。
在特定的业务场景下,只有一个索引,而且这个索引还是唯一索引,这个时候就适合用业务字段来做主键。
PS:在没有主键的表,InnoDB会默认创建一个Rowid做主键
索引的优化以及一些原则
覆盖索引
例如SELECT id FROM T WHERE k BETWEEN 1 AND 3这个语句,因为是直接查询ID,所以可以避免回表的过程,提高效率,这个就称为覆盖索引。覆盖索引可以减少树的搜索次数,显著提升查询性能,所以使用覆盖索引是一个常用的性能优化手段。
先来看看一个建立联合索引SQL语句
CREATE TABLE 'user'(
'id' int(10) NOT NULL,
'name' varchar(32) NOT NULL,
'age' varchar(32) NOT NULL,
PRIMARY KEY('id'),
KEY 'name_age'('name','age')
)基于覆盖索引,我们可以在高频请求上来建立联合索引,这样就不需要回表查询整行记录,可以大大提高性能。不过索引的维护是需要浪费资源的,所以在建立来联合索引的时候需要考虑的更多。
最左前缀原则
B+树的索引结构,可以利用最左前缀来定位记录。最左前缀:顾名思义,就是会InnoDB会根据优先根据最左边的字段来匹配索引,所以在建立联合索引的时候,要合理安排所以内字段的顺序。第一原则,看能否通过调整字段顺序,来少维护一个索引,这样的顺序一般就是优先采用的。
如果有联合索引(a,b)又有基于a,b的各自查询,像查询条件里面只有b的语句的时候,(a,b)这个联合索引就无法使用,这个时候就必须同时维护(a,b)(b)这两个索引。这个时候就要考虑空间的问题,由字段的大小来考虑。
索引下推
在MYSQL5.6之前,InnoDB并不会去看联合索引(a,b)中b的值,只是把匹配a的值取出来,找到对应的ID,并一个个去回表,因为没有匹配b的值,所以查询到的数据可能比较多,这样回表的话性能消耗也比较大。MYSQL5.6之后就引入索引下推,这样先匹配a,b的值,过滤后的数据就比较少,也就能减少回表的次数,可以提高效率。
PS:删除表的记录,可能索引还在,还是会占用很多内存,这个时候可以考虑重建索引
如果大家看的觉得有收获,可以收藏等待索引下篇