参考课程:Numpy & Pandas (莫烦 Python 数据处理教程) 和 Python数据分析和数据可视化
Pandas基本介绍
- Pandas像是字典形式的Numpy,它给Numpy的不同行和列都进行了命名。
Pandas数据结构及其创建
- 数据结构有两种:Series和DataFrame。而DataFrame可以看作是共享了所有行索引的由Series组成的字典。
- Series对象的创建:pd.Series(list) 和 pd.date_range(‘20160101’,periods =6) ---- 时间序列的创建。
DatetimeIndex(['2016-01-01', '2016-01-02', '2016-01-03', '2016-01-04',
'2016-01-05', '2016-01-06'],
dtype='datetime64[ns]', freq='D')
- DataFrame对象的创建方式1:指定数据元素、行索引index和列索引columns ---- pd.DataFrame(np.random.randn(6,4),index = date,columns=[1,3,4,5]) ---- 默认地,行、列索引是01234567…
- DataFrame对象的创建方式2:输入字典[键是单值,值是列表] ---- pd.DataFrame({‘A’:1,
‘B’:pd.Timestamp(‘20130102’),
‘C’:pd.Series(1,index = list(range(4)),dtype=‘int64’),
‘D’:np.array([3]*4,dtype=‘int32’),
‘E’:pd.Categorical([‘test’,‘train’,‘test’,‘tram’]),
‘F’:‘foo’}) ---- 行索引默认为01234… - DataFrame对象讲解的两个名字介绍:
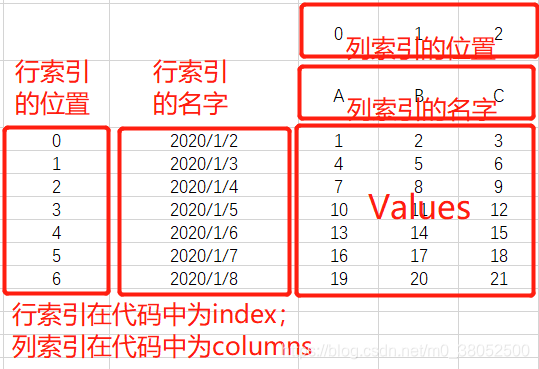
Pandas数据结构的属性和常用统计方法
- Series对象的属性:dtype、index、values、
- DataFrame对象的属性:dtypes、index、columns 和 values 、T、info(每列的数据类型及非空值的个数等)
- DataFrame对象的方法
- object.describe ---- 仅限于数字型的column。
- object.[sum| mean| idmax] ---- 得到垂直方向上每一列的最大值的索引位置。
- object.value_counts ---- 统计每个元素出现的频率,且按照频率高低进行排序展示。
- object.pct_change ---- 计算垂直方向上,相邻两个元素的变化百分比,常见于股票的变化统计。
- df.corr ---- 返回每一列之间的相关系数!!!!!
- df.cov ---- 返回每一列之间的协方差。
10.df.corrwith(series) ---- 返回df对象与某一列之间的相关系数。
琐碎知识点;
- pandas对象调用方法提倡使用对象点出方法的方式。
Pandas排序
- df.sort_index(axis,ascending) ---- 按行索引排序
- df.sort_values(by,ascending) ---- 按列名排序 而 按多列排序时用列表传参。
- df|series.rank() ---- 知晓序列中对应的元素值在整个序列中的排名,且从大到小。
- df.reindex([行|列索引顺序],axis) — 人为地指定索引顺序进行排序,且如果添加了不存在地列或者行,会自动填充nan,顺利进行。
Pandas选择数据与赋值数据
- df.column | df[“column”] | df[[“column1”,“column2”] | 列索引名不能用切片] ---- 索引为一个值,表示对单列的选择,索引为多个值(非切片)表示对多列的选择。
- df[ “index1”:“index2” ] ---- 切片表示对行索引的位置进行切片选择。
- df.loc[“index”] | df.loc[:,[“column1”,“column2”]] | df.loc[“index_name1”:“index_name2”,“column1”:“column2”] ---- 对某一行进行选择、对指定的多列进行选择。loc的规则是,第一个参数为index值或者index值的切片又或者逗号式的多值列表,第二个参数同第一个参数。
- df.iloc[单个索引号 | 索引号的切片 | 多个用逗号构成的索引号形成的列表:同左] ---- iloc的规则是,单值的位置、切片和逗号式的多值列表均可以,但是值必须是索引位置,而不是索引的名字。
- df[] 、df.loc 、df.iloc 的选择规则总结梳理
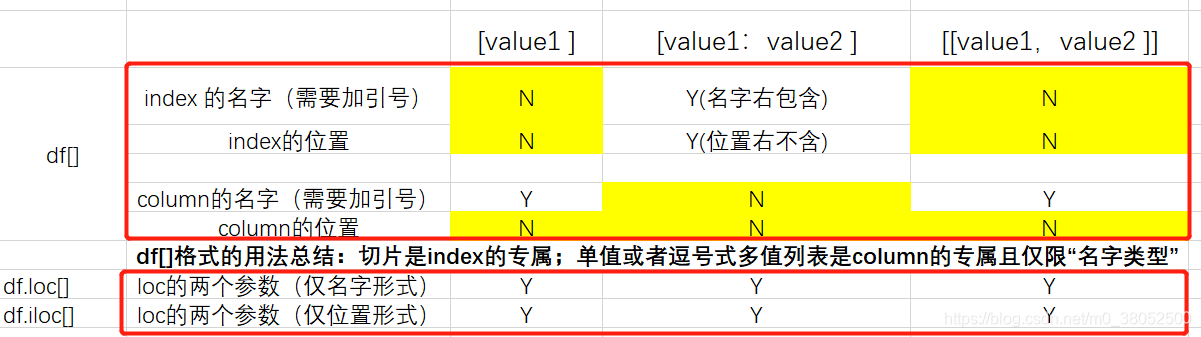
- bool式选择数据 ---- df[df.A > 8],虽然只对比A大,但是BCD也显示。
- 赋值的内容可以是单值、np.nan、Series列表。
print(df)
print(df[df.A>8])
###### 输出内容 ###########
A B C D
2013-01-01 0 1 2 3
2013-01-02 4 5 6 7
2013-01-03 8 9 10 11
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
A B C D
2013-01-04 12 13 14 15
2013-01-05 16 17 18 19
2013-01-06 20 21 22 23
琐碎知识点:
- loc 和 iloc 均可以支持 名字和位置 的单值、切片和逗号式的多值列表。
- “a” in Series ,本质上是判断是否处于Series.index中;如果判断是否是
Series.values中的值,需要指定:”a“ in Series.values。
Pandas的基础运算
- Series对象间的相加减乘除 ---- 规则是必须index索引相对齐才能使得对应值进行运算。
- DataFrame对象与Series的相加减乘除 ---- 规则是列标签对齐,进行广播且不匹配列填充nan值。
- DataFrame对象与DataFrame的相加减乘除 ---- 规则是 行列标签均对齐,未对齐的地方填充nan。
DataFrame对象的增加删除列
- 通过df[“column”] | data.loc[:,“column”] 的方式选择并不赋值,但不可选择df.column 和 iloc。
- del column 删除一列
- df.drop(“column”|[“column1”,“column2”] ,axis) ---- 删除行或列
- df.loc[“index_name”] ---- 增加行
- df.assign(new_column = list) ---- 增加列。
- pd.concat(df1,df2) ---- 增加行,以同属性对齐的方式。
Pandas丢失值处理方法
- df.dropna(axis,how) ---- how=any则只要指定轴上存在nan,就删除相应的行或列;how=all 则需要指定轴上全部为nan,才可以删除相应的行或列。
- df.fillna(value = 0) ---- 填充0值。
- df.isna|isnull---- 判断矩阵或者矩阵的某列是否存在缺失值。
- df.fillna({‘a’:1,“b”:10,“c”:30,“d”:1000}) ---- 不同列对应的nan值采取不同的填充值。
- Series.fillna(data.a.mean()) ---- 为某一列的nan填充该列的平均值。
琐碎知识点:
- isna() 的另一个用法:当矩阵太大时,但是又想知道是否某一列或者整个矩阵是否存在nan值。则用(df.A.isna()).sum() 或者 np.any(df.isna()==True)
Pandas重复值处理方法
- df.duplicated() ---- 检查是否存在重复行,并返回一维bool矩阵。
- df[df.duplicated()] ---- bool式数据选择,取出重复的行。
- df[~df.duplicated()] ---- 取出不重复的行。
- df.drop_duplicates([“column1”,“column2”],axis) ---- 去除在column1和2上重复的行,且可以指定轴。
Series替换处理方式
- Series.replace(3,np.nan) ---- 单个情况。
- Series.replace({3:np.nan,2:100}) ---- 多种情况
字符串处理
- 字符串处理的方法大多经由str方法点出!
- df.k1.str.replace(“beijing”,“shanggai”) ---- 将某一列中的A字符串替换为B字符串。
- df.k1.str.contains(“chushou”) ---- 判断某一列的元素是否包含**是(不是含)**字符串。
- df[df.k1.str.contains(“chushou”)] ---- 选择出 包含某个字符串的行的整体内容。
- df.k1.str.upper() ---- 将某一列的字符串大写。
- data.k1.str.split(’,’) ---- 将某一列的字符串处理成一列的列表。
应用函数处理数据
- Series.map ---- map 仅可用于Series对象,且接受一个函数,或是一个字典,元素级别
- df.apply ---- apply 可以应用在df的行或列之上,且指定轴方向。
- df.applymap – applymap 应用在 元素级别。
数据离散化
- pd.cut(Series,bins) ---- 按照bins区间,返回一个value对应的bin的一维列表。
- pd.cut(data.k1,bins).value_counts() ---- 辅助进行组内数目排序,更加直观。
- pd.cut(data,4) ---- 指定对范围进行均等分割
- pd.qcut(data,4) ---- 指定对个数进行均等分割
Pandas合并
- pd.concat([df对象列表],axis,ignore_index,join) ---- 指定轴方向上合并df对象,且注意join默认为outer。
- df.append(df2|[df2,df3]) ---- 对象竖向合并。
- pd.merge(df1,df2,on=“column_name”|[“column_name1”,“column_name2”],how=”inner|outer|right|left“,indicator=True) ---- 基于一列或多列的列名进行左右融合。
- pd.merge(df1,df2,left_index=True,right_index=True,how=”inner|outer|right|left“) ---- 基于行索引进行左右融合。
- df.join(df2) ---- merge的以index融合的快捷方式。
琐碎知识点:
- merge,默认当两个df对象的属性名相同时,会默认将同名的属性作为融合的键,避免的方式是,借用on关键词来指定某一列或多列作为融合的键,除此之外,还可以指定left_on与right_on。
- merge还允许指定用左边的索引和右边的列作为融合的键left_index 和 right_on
Pandas数据聚合与分组运算
- df.groupby(df[“animal”])[“weight”].mean() ---- 根据单列进行分组后,对单列进行运算。
- df.groupby([“size”,“adult”]).size() ---- 根据多列进行分组,返回一个多层索引Series。
- df.groupby([“size”,“adult”]).size().unstack() ---- 将内层索引转化为列索引,最后返回一个DF。
- df.groupby([“size”,“adult”]).size().unstack().stack() ---- 将df的columns转化为一个多层索引。
Pandas透视表
- data.pivot_table(“cjzongjia”,index=“xingming”,columns= “congyenianxian”,aggfunc=“sum”)
Pandas时间序列
- pd.to_datetime([“2017/12/01”,“2017/12/02”]) ---- 识别多种日期格式为统一的日期格式。
- pd.date_range(“首日期”,“末日期”,freq=“B”) ---- 自行生成时间序列
- pd.date_range(start = “20171201”,periods=20) ---- 自行生成时间序列
- ts.resample(“M”)
Pandas绘图
- Series.plot() ---- 索引作为横坐标,值作为纵坐标的线图。
- DataFrame.plot() ---- 行索引作为横坐标,每一个列作为一个线图。
- plot.bar | hist| box| kde| area| sactter| hexbin (x[可选],y,rot,color,label)---- 更加丰富的图。
- plt.style.use(“ggplot”) ---- 设置显示类型
琐碎知识点:
- concat的规则:上下合并,关注列名对齐,即使列名冲突也不会出错;左右合并,关注行索引对齐,但行索引仅局部对齐会出错。
Pandas数据加载和存储
- pd.read_csv(“file.csv”,sep=",",header = None,names= np.arange(14),index_col=“location”,nrows=30) ---- 加载数据
- pd.to_csv() ---- 存储数据。
=============================== T H E E N D ! ===============================