文章目录
Kafka
在流式计算中,kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。kafka是一个分布式消息队列,kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实力组成,每个实例(sever)称为broker。
- 无论kafka集群,还是consumer都依赖与Zookeeper集群保存的一些元数据信息,来保证系统可用性。
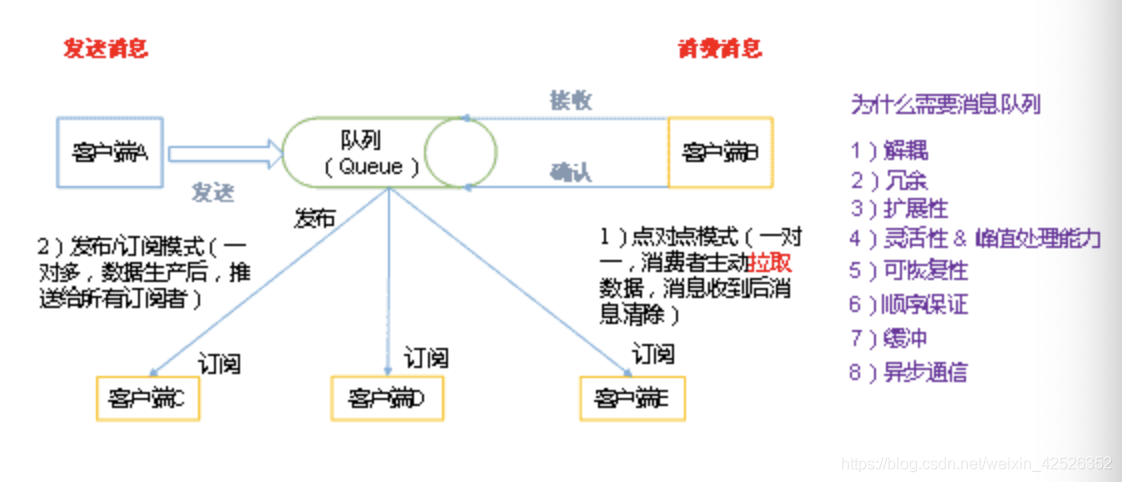
1. 消息队列
-
点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型这种消息从队列中请求信息,而不是将信息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接收者接收处理,即使有多个消息监听者也是如此。 -
发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型,发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
2. Kafka架构
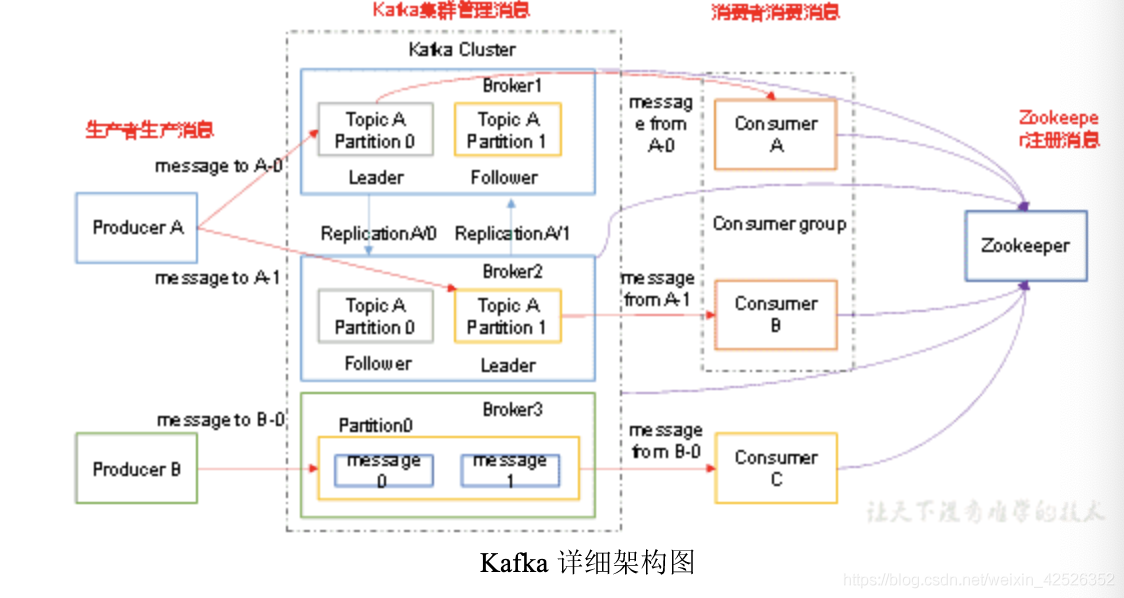
- producer:消息生产者,就是向kafka broker发消息的客户端;
- consumer:消息消费者,向kafka beoker取消息的客户端;
- topic:可以理解为一个队列;
- consumer group(CG):kafka用来实现一个topic消息的广播,和单播的手段,一个topic可以有多个CG。topic的消息会复制到所有的CG。topic的消息会复制到所有的CG,但每个partion只会把信息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
- broker:一台kafka服务器就是一个broker,一个集群由多个broker组成。一个broker可以容纳多个topic。
- partition:为了实现扩展性,一个非常大的topic可以分布到多个broker上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset),kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体的顺序。
- offset:kafka的存储文件都是按照offset。kafka来命名,用offset来做名字的好处是方便查找。
3. kafka 高吞吐量的原因
- 顺序读写
kafka的消息是不断追加到文件中的,这个特性使kafka可以充分利用磁盘的顺序读写性能。
- 顺序读写不需要硬盘磁头的寻道时间,只需很少的扇区旋转时间,所以速度远快于随机读写。
- 零拷贝
- "零拷贝(zero-copy)"系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存的直接映射,数据不再复制到“用户态缓冲区”
- 分区
- kafka中的topic中的内容可以被分为多分partition存在,每个partition又分为多个段segment,所以每次操作都是针对一小部分做操作,很轻便,并且增加并行操作的能力。
- 批量发送
- kafka允许进行批量发送消息,producter发送消息的时候,可以将消息缓存在本地,等到了固定条件发送到kafka。
- 等消息条数到固定条数
- 一段时间发送一次
- 数据压缩
- Kafka还支持对消息集合进行压缩,Producer可以通过GZIP或Snappy格式对消息集合进行压缩。压缩的好处就是减少传输的数据量,减轻对网络传输的压力
批量发送和数据压缩一起使用,单条做数据压缩的话,效果不明显
4. Kafka监控
开源的监控器:KafkaCenter
github:https://github.com/xaecbd/KafkaCenter

Home ->查看kafka群集列表和监视信息
Topic ->用户可以在此模块中查看他们自己的主题,申请新主题,模拟和消费数据。
Monitor ->用户可以在此模块中查看主题的生产和使用情况,并为使用延迟设置警告信息。
Kafka Connect- >用户能够快速创建自己的Connect作业并维护自己的Connect。
KSQL- >用户能够快速创建自己的KSQL作业并维护其作业。
Approve ->此模块主要用作创建主题,操作管理员以供批准的通用用户应用程序。
Setting ->管理员维护用户,团队。
Kafka Manager->维护kafka集群信息。
5. Kafka丢不丢数据?
- Ack=0,相当于异步发送,消息发送完毕即offset增加,继续生产。
- Ack=1,leader收到leader replica 对一个消息的接受ack才增加offset,然后继续生产。
- Ack=-1,leader收到所有replica 对一个消息的接受ack才增加offset,然后继续生产。
6. Kafka幂等性
Producer的幂等性指的是当发送同一条消息时,数据在Server端只会被持久化一次,数据不丟不重,但是这里的幂等性是有条件的:
- 只能保证Producer在单个会话内不丟不重,如果Producer出现意外挂掉再重启是无法保证的(幂等性情况下,是无法获取之前的状态信息,因此是无法做到跨会话级别的不丢不重)。
- 幂等性不能跨多个Topic-Partition,只能保证单个Partition内的幂等性,当涉及多个 Topic-Partition时,这中间的状态并没有同步。
7. Kafka消息数据积压,Kafka消费能力不足怎么处理?
- 如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
- 如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。所以就涉及spark背压相关知识点。