HBase是一个高可靠性,高性能,面向列、可伸缩的分布式存储系统,利用HBase技术可以在廉价的PC Sever上搭建起大规模结构化存储集群。
1. 特点
海量存储,适合存储PB级别的海量数据,在PB级别的数据以及采用廉价pc存储的情况下,能在几十到百毫秒内返回数据。
列式存储,HBase是根据列族拉开存储数据的,列族下面可以有非常多的列,列族在创建表的时候就必须制定。
极易扩展,其扩展性主要表现在两个方面,一个是基础上层处理能力的扩展,一个是基于存储的扩展。
高并发,由于采用廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百个MS之间,这里说是在并发情况下,Hbase的单个IO延迟下降并不多。
稀疏,主要是针对Hbase列的灵活性,在列族中,可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
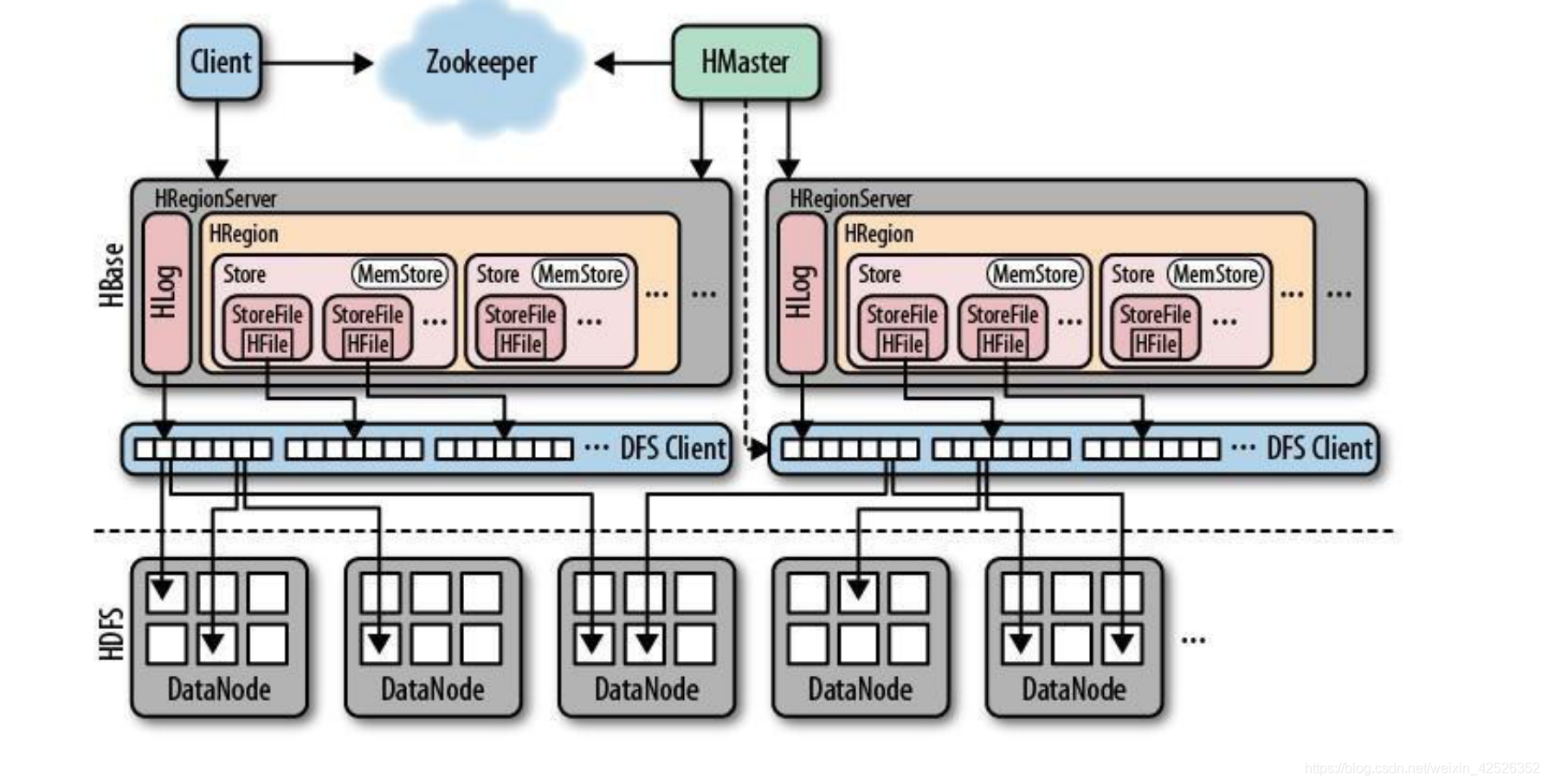
2. Hbase 的存储格式
Hbase中的所有数据文件都存储在HDFS文件系统上,格式主要有两种:
-
HFile,HBase中Key-Value数据的存储格式,HFile是Hadoop的二进制格式文件,实际上StoreFile就是对HFile做了轻量级包装,即StoreFile底层就是HFile。
-
HLog File,HBase中WAL(Write Ahead Log)的存储格式,物理上是Hadoop的Sequence File
3. Hbase数据读取与数据写入
3.1 数据读取
- 客户端通过 zookeeper 以及-root-表和.meta.表找到目标数据所在的 regionserver(就是数据所在的 region 的主机地址)
(0.98版本以前,0.98及以后没有-ROOT-表) - 联系 regionserver 查询目标数据
- regionserver 定位到目标数据所在的 region,发出查询请求
- region 先在 memstore 中查找,命中则返回
- 如果在 memstore 中找不到,则在storefile 中扫描 (可能会扫描到很多的storefile----BloomFilter)
3.2 数据写入

-
client 先根据 rowkey 找到对应的 region 所在的 regionserver
-
client 向 regionserver 提交写请求
-
regionserver 找到目标 region
-
region 检查数据是否与 schema 一致
扫描二维码关注公众号,回复: 11350322 查看本文章
-
如果客户端没有指定版本,则获取当前系统时间作为数据版本
-
将更新写入 WAL log
-
将更新写入 Memstore
-
当memstore写入的值变多,触发溢写操作(flush),进行文件的溢写,成为一个StoreFile
-
当溢写的文件过多时,会触发文件的合并(Compact)操作,合并有两种方式(major,minor),多个StoreFile合并成一个StoreFile,同时进行版本合并和数据删除
- minor compaction:小范围合并,默认是3-10个文件进行合并,不会删除其他版本的数据。
- major compaction:将当前目录下的所有文件全部合并,一般手动触发,会删除其他版本的数据(不同时间戳的)
-
当region中的数据逐渐变大之后,达到某一个阈值,会进行裂变(一个region等分为两个region,并分配到不同的regionserver),原本的Region会下线,新Split出来的两个Region会被HMaster分配到相应的HRegionServer上,使得原先1个Region的压力得以分流到2个Region上。