文章目录
在上一期中,我们主要探寻了 话题分割的任务定义和主要的评估方法,这一期,我们主要介绍常用的语料库和常用的方法。
话题分割常用的语料库
话题分割与两个领域息息相关,一个是TDT(话题跟踪与检测),另一个就是对话系统里的话题分割。英文的话题分割起源较早,在1997年Choi语料库后,一系列语料库得以建立,而且后续有了大量的研究;中文上的专门研究话题分割的较少。
Choi语料库(句子级别)
最出名的要数Choi的语料库了。这个诞生自2000年的语料库发行于Advances in domain independent linear text segmentation,被广泛用于话题分割的实验中。神奇的是这篇文章并没有直接给出资源链接(原谅它来自20年前)。它有两个版本,一个是700篇的版本,一个是920篇的版本,但是其格式都是一样的,
它毕竟是话题分割语料库的先驱,确实存在着一些缺陷,例如,最大的缺陷在于,它的每个样例并不是一个真实的文章,而是从若干个文章中抽取出K个句子重组出来的(124篇来自于布朗语料库)。这就表明其实每个子话题之间的关联度并没有真实的文章中关联的那么紧密。
Wiki727语料库(句子级别)
这个语料库规模大了很多,是从Wiki百科中抽取出的,来自于2018年的Text Segmentation as a Supervised Learning Task,它包含了727,746篇文章,是一个相当大的语料库,如果是在英文中的话,可以使用这个语料库进行实验。值得注意的是,这个语料不同于其他语料,由于它将文本分割看作是一个有监督的任务,因此它是拥有训练集、验证集和测试集的。
clinical 语料库(句子级别)
这个语料库来源于书籍,主要是医学相关的,包含了227篇文章,同样是句子级别的。这个语料库是由Bayesian unsupervised topic segmentation.引入的。
Cities 和Elements 语料库(段落级别)
这两个语料库同样来源于Wiki百科,只不过规模要小一些(Cities 100篇,Elements 118篇),在2009年的Global Models of Document Structure Using Latent Permutations中被创建。
常用模型
在本章中,我们主要介绍关于文本分割的相关模型,按照模型划分可以分为基于语言学特征的、基于机器学习的、基于外部知识的和基于深度学习的模型四个类别,我们重点介绍基于深度学习的模型。早期有一个总述《文本主题分割技术的研究进展》,也可以参考。
基于语言学的模型
没有使用任何机器学习,仅仅依靠语言学上的概念(如词共现、线索词、词的转移与变换等)进行文本分割的我们都在此部分介绍,这些工作大多都在20年前了,因此我们只进行一些简单的介绍,针对一些较为出名的进行罗列。
最为注明的是Texttilling,后面很多工作,即使是2017年的工作都会跟这个20年前(1997年)的工作进行比较,而且最重要的是它已经成为NLTK的官方自建库了。
2001年UI A Statistical Model for Domain-Independent Text Segmentation
2002年的动态规划
2003年的LCSeg使用的是词汇链
2006年的最小割方法
基于机器学习的模型
机器学习模型分为两种,一种是无监督的以LDA和LSA等为代表的依靠主题聚类而形成最终的结果。另一种则是有监督的学习。
无监督模型
在2002年第一个使用PLSA进行文本分割的工作后,基本上就进入了机器学习的时代。
2008年的Bayesian unsupervised topic segmentation.应该是无监督模型中较好的一个。
2009年的Text Segmentation via Topic Modeling: An Analytical Study和2012年的TopicTiling(Code)都是使用了LDA模型,取得了更好的结果。
2016年的SegGraph模型是完全不需要主题模型的无监督模型,它相比较需要主题的模型,也表现出差不多的性能。
有监督模型
2010年使用CRF在篇章EDU切分的工作。
2015年Text Segmentation based on Semantic Word Embeddings使用词向量进行了简单的实验。
融入外部知识的模型
融入外部知识的模型会比较受约束,当然也具有更好的性能。例如2018年进行层次化主题划分的工作。
基于深度学习的模型
2016年使用的是CNN+Bilstm进行文本分割,而且是在中文语料中进行的,但是遗憾的是其语料库还没有公开。
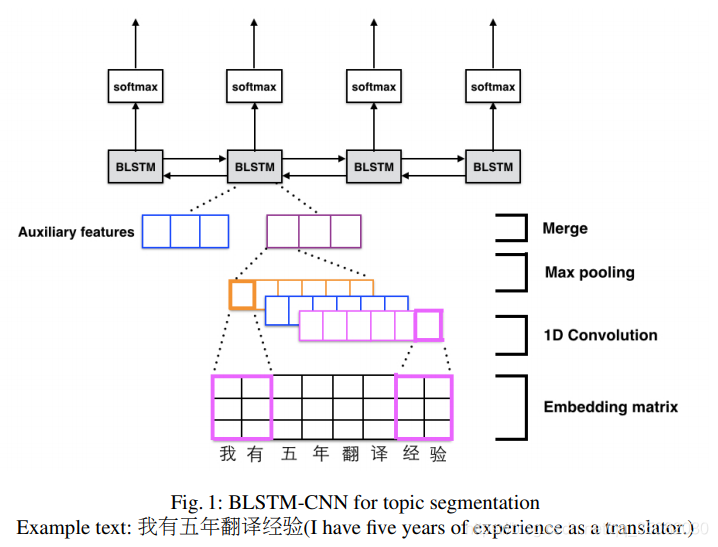
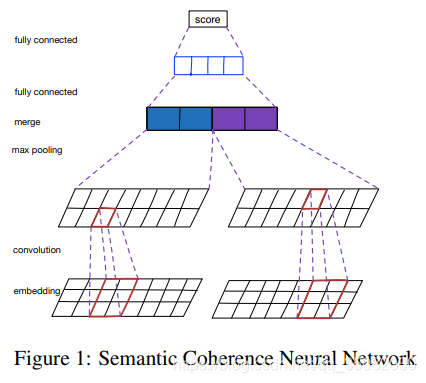
2018年的一个比较传统的方法就是语义匹配方法进行实验:
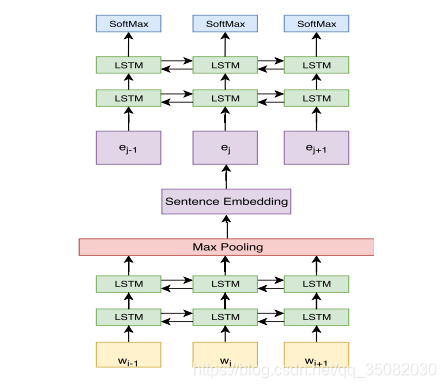
2018年的使用句子向量表示进行文本分割的文章主要贡献在于提供了刚才所讲的Wiki727语料库,也构建了一个基于句子向量的分类模型。
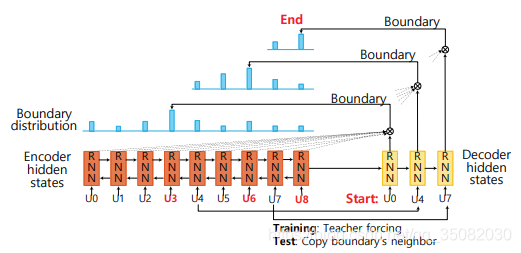
2018年的Segbot采用的是PointerNetwork的框架进行的句子级别的文本分割,并且在实验中表明其显著优越于TopicTilling 和BiLSTM+CRF。而且,它没有使用其他手工特征,就已经能够取得0.11Pk值在Choi语料库中。它只给出了一个在线展示的网站,但是并没有给出开源的源码。
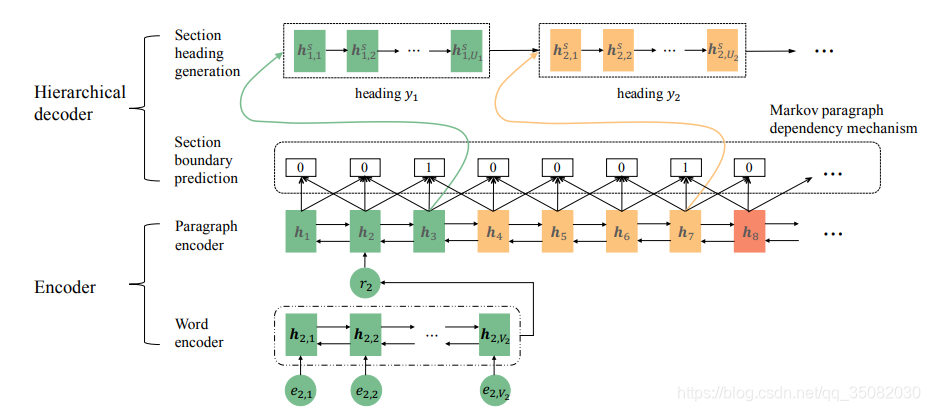
在2019年的OG任务中,Outline Generation: Understanding the Inherent Content Structure of Documents也进行了文本分割任务,它主要使用双向GRU编码并结合马尔科夫段落依存机制进行文本分割,其分割颗粒度为段落级别。
小结
从上可以看出,尽管有一些主流的文本分割语料库,但是由于其评估方法的不同以及并没有非常规范的语料划分,因此各个模型之间相互比较较为困难。总的来说,就如同时代车轮发展一样,深度学习模型优于机器学习模型,机器学习模型优于基于语言学的模型。
这里还有一个关于文本分割的小汇总。