LINUX系统写速度问题解决过程
问题描述:
linux系统下写速度只有2GB/s左右,无法支持2.5G采样率连续采集,达不到预期的性能。而同样的代码在windows系统下,却可以支持2.5G采样率连续采集,因此这里需要解决Linux系统的写速度问题。
尝试一:
刚开始以为是API的问题,查看资料发现大部分说法是mmap写文件最快,实际测试下来发现效果一般,没有特别惊艳的表现。加上使用不太方便,否定了这个解决方案。
尝试二:
由于用测速软件测试时,在两个系统里硬盘的顺序读写速度都是7~8GB/s,所以一开始我在Windows系统下对硬盘做了实际的测试,没有用测速软件,而是纯用writefile函数在写,发现读写在6GB/s左右。而且打开”FILE_FLAG_NOBUFFRING”标志位后才有这样的速度,不开的话会慢。如图:

可以看出写速度约为5GB/s,读速度约为6GB/s。
然而我换到Linux系统后,也不用测速软件,纯用write函数,发现它的写速度只有2GB/s,但是读速度却在7GB/s。这让我十分怀疑是否是写操作有什么设置没有打开。一番实验查找之后,我发现Windows的raid卡的写策略是启动了写缓存,如图:

但是我在Linux系统中却没有找到这样的设置或查询。不过在查看内核打印有一句"Write cache disabled,read cache enabled",如图:

可以看出正好是说写缓存关闭而读缓存打开,跟目前测试出来的情况一致。我一度以为已经找到了问题所在,但是使用hdparm磁盘管理工具却没办法查询或设置raid卡的写缓存。
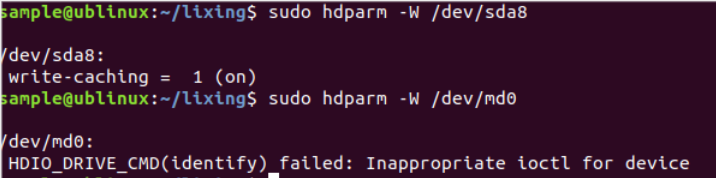
而且这句话是否是描述raid卡的也存疑,在尝试了另外一些设置硬盘写缓存的方法无效后,我放弃了这个解决办法。后来我也确定这句话描述的是另外一个硬盘,而不是我们用的raid卡。
尝试三:
于是我又回到了测试速度的工具上。linux下我用测速软件测得磁盘流盘速度为7000M左右。但是我用另一个linux下很常用的dd命令来测速时却和上个软件相差如此之大,如图:

我想是否是dd命令有一些关于写速度的参数设置,于是仔细研究了dd命令的参数设置后发现:

这些参数其中direct和nonblock跟我们在windows上采用的“FILE_FLAG_NOBUFFING”,即不使用缓冲区直接操作磁盘的方式相似。于是我对这两个做了测试之后,发现在用dd命令时,加上direct参数,跳过系统缓存,直接写到硬盘,在大量数据连续存储时可以提高性能。查资料后发现direct 模式是把写入请求直接封装成 I/O 指令发到磁盘,非 direct 模式只是把数据写入到系统缓存就认为 I/O 成功,并由操作系统决定缓存中的数据什么时候被写入磁盘。

结论:
因此我们可以得出这样一个结论,在linux系统中,IO写入的基本过程
a. 定位用户数据
b. 将用户数据拷贝至内核中(page cache)
先解释一下page cache。page cache是文件在内存中的缓存,打开文件时,先要把文件加载进pache cache,写入时也是一样,先写入page cache,再由page cache刷入磁盘。一般来说,page cache中的数据也是文件的一部分,所以如果数据写入了page cache,就可以认为io操作已安全完成。
上述的过程是一个非常简化的版本,实际的一些api比如fwrite()的实现可能是这样的
---用户层---
a. 定位用户数据
b. 将用户数据拷贝至函数的缓存中(函数调用返回)
---vfs层(即虚拟文件系统)---
c. 将函数缓存拷贝至内核缓存(page cache) (显式或隐式调用fflush() )
d. 将page cache中的脏数据写入磁盘数据区(调用硬盘驱动)
e. 将inode cache中的脏数据写入磁盘inode区(调用硬盘驱动)
---存储控制器层---
到目前为止,写入基本完成,数据被存储控制器接管,由于存储控制器自带板载电容,因此可以认为数据已固化
f. 从板载cache(比如ssd raid 卡)中读取数据
g. 将数据写入磁盘介质
对于linux的write()函数来说,调用在c步就返回了。而对于fwrite()这种经过一次封装的函数来说,它在write之上增加了一层缓冲,也就是说调用fwrite会在b步返回,为了保证数据写入文件,使用fwrite时,可以调用fflush()函数来保证调用到第c步。如果认为此时存储于操作系统的page cache仍不安全,可以继续调用fsync()来保证调用到第e步。(如果到了这里仍然觉得数据不够安全,可以将存储控制器的模式更改为write through,这样可以保证第g步完成后才返回)。
如果打开文件时采用了direct io的方式,可以绕开对于page cache的操作,就是绕过了d步,但是,e步并没有被绕过,因此,使用direct io方式时,为了保证数据的绝对安全,依旧需要调用fsync()来保证文件的元数据(inode等信息)写入磁盘(可以在open时增加O_SYNC,但这样会严重影响效率)。
因此对于写文件时要不要缓冲区这个事情,要从具体的应用角度去看。在需要频繁读取写入数据,并且数据的量不是很大时,通过缓存机制可以有效的提升读写数据的速度,因为当你要读取数据时,系统会先查看你要的数据是否在缓存里,如果在缓存中则直接提取,由于数据还没有真正的刷入硬盘中,因此这个操作是电子层面而非IO层面,速度要快的多。当缓存中的数据多到一定程度,系统才会将不常用的数据真正的写入磁盘。
而这种应用情景,大量数据需要快速的写入硬盘中,全部写完后,用户才有可能会继续回放文件等之类的操作,因此绕开缓存机制,直接以合适的block size循环的写入硬盘,则比用缓存的机制,让系统决定什么时候写入磁盘要快很多。
最后,direct方式是以扇区为单位操作磁盘,因此执行一次写入操作的最小单位是512 Bytes。而且direct方式不常用,在使用时要加一下宏定义_GNU_SOURCE或其他的,否则找不到“O_DIRECT”这个参数,它操作的内存也不能使用平常的定义数组的方式,应该要用mmap或malloc去申请内存,具体使用详情自行百度关键字。
最终的测试结果如图;

以下为测试源码:
#define _GNU_SOURCE 1
#define __USE_GNU 1
#include <stdio.h>
#include <assert.h>
#include <fcntl.h>
#include <getopt.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <time.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/time.h>
#include <sys/types.h>
#include <unistd.h>
static void *mmap_control(int fd,long mapsize)
{
void *vir_addr;
vir_addr = mmap(NULL, mapsize, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
return vir_addr;
}
void* pvAllocMemPageAligned (uint64_t qwBytes)
{
void* pvTmp;
int fd = open ("/dev/zero", O_RDONLY);
pvTmp = (void*) mmap (NULL, qwBytes, PROT_READ | PROT_WRITE, MAP_PRIVATE, fd, 0);
// set everything to zero to get memory allocated in physical mem
if (pvTmp != MAP_FAILED)
memset (pvTmp, 0, qwBytes);
else
pvTmp = NULL;
close (fd);
return (pvTmp);
}
// ***********************************************************************
void vFreeMemPageAligned (void* pvAdr, uint64_t qwBytes)
{
munmap (pvAdr, qwBytes);
}
static void timespec_sub(struct timespec *t1, const struct timespec *t2);
int main()
{
printf("CLOCKPERSEC=%ld\n",CLOCKS_PER_SEC);
char filename[64] = "/home/sample/SampleData/testspeed_rcv.bin";
int file_fd = open(filename, O_RDWR | O_CREAT | O_TRUNC|O_DIRECT, 0666);
if(file_fd<0)
{
perror("rcv file err:");
}
int rc;
int size=2*1024*1024;
//char buffer[4*1024*1024]={0};
void *buffer=NULL;
buffer=pvAllocMemPageAligned(4*1024*1024);
/*void* control_base;
control_base=mmap_control(file_fd,size);
if(control_base=NULL||control_base==(void*) -1)
{
printf("映射失败\n");
close(file_fd);
return -1;
}*/
struct timespec ts_start, ts_end;
clock_gettime(CLOCK_MONOTONIC, &ts_start);
clock_t start1,end1;
start1=clock();
printf("flag1\n");
int times=1000;
for(int i=0;i<times;i++)
{
//memcpy(control_base,buffer,size);
rc= write(file_fd, buffer, size);
if(rc!=size){
perror("write error:");
return -1;
}
}
end1=clock();
printf("flag2\n");
clock_gettime(CLOCK_MONOTONIC, &ts_end);
float dur1=(float)(end1-start1);
printf("Cost Time=%f\n",(dur1/CLOCKS_PER_SEC));
printf("rc=%d\n",rc);
timespec_sub(&ts_end, &ts_start);
printf("Cost %ld.%09ld seconds (total) for transfer \n",
ts_end.tv_sec, ts_end.tv_nsec);
printf("Write Speed=%f\n",(float)(size/1024/1024*times)/(ts_end.tv_sec+ts_end.tv_nsec/1e9));
/*if(munmap(control_base,size)==-1)
{
printf("munmap error!\n");
}*/
close(file_fd);
file_fd=open(filename,O_RDWR|O_DIRECT);
if(file_fd<0)
{
perror("rcv file err:");
}
start1=clock();
clock_gettime(CLOCK_MONOTONIC, &ts_start);
for(int i=0;i<times;i++)
{
//memcpy(control_base,buffer,size);
rc= read(file_fd, buffer, size);
if(rc!=size)
{
printf("rc=%d\n",rc);
}
}
clock_gettime(CLOCK_MONOTONIC, &ts_end);
end1=clock();
dur1=(float)(end1-start1);
printf("\n\nCost Time=%f\n",(dur1/CLOCKS_PER_SEC));
printf("rc=%d\n",rc);
timespec_sub(&ts_end, &ts_start);
printf("Cost %ld.%09ld seconds (total) for transfer \n",
ts_end.tv_sec, ts_end.tv_nsec);
printf("Read Speed=%f\n",(float)(size/1024/1024*times)/(ts_end.tv_sec+ts_end.tv_nsec/1e9));
close(file_fd);
vFreeMemPageAligned(buffer,4*1024*1024);
}
static void timespec_sub(struct timespec *t1, const struct timespec *t2)
{
assert(t1->tv_nsec >= 0);
assert(t1->tv_nsec < 1000000000);
assert(t2->tv_nsec >= 0);
assert(t2->tv_nsec < 1000000000);
t1->tv_sec -= t2->tv_sec;
t1->tv_nsec -= t2->tv_nsec;
if (t1->tv_nsec >= 1000000000)
{
t1->tv_sec++;
t1->tv_nsec -= 1000000000;
}
else if (t1->tv_nsec < 0)
{
t1->tv_sec--;
t1->tv_nsec += 1000000000;
}
}