一、前言
在正式讲解这三种异常时,我们先话两分钟来回顾一下,redis缓存或者说一般缓存的基本流程,老习惯,开局一张图,剩下全靠编,啊呸,剩下全靠理解。
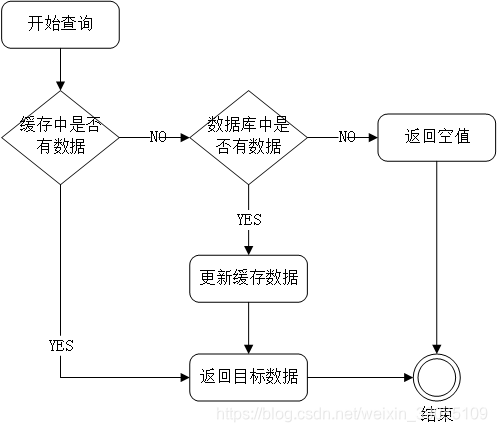
二、缓存击穿以及应对策略
1、定义
假设有一个热点新闻K-V在缓存数据库中,比如说微博热搜,但是当微博热搜的K-V过期,则会透过缓存数据库,直接打到数据库中,造成一瞬间有大量用户访问,给数据库带来很大的压力。
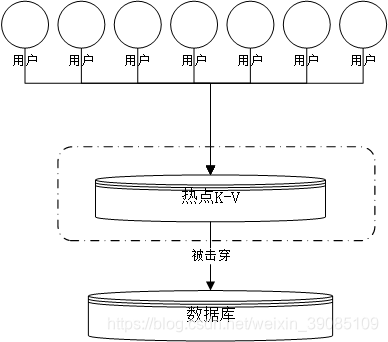
2、应对策略
2.1使用互斥锁
并发量不大的时候可以使用以下方法实现:
简单思路分析:由于缓存击穿是由于用户访问同一个热点K-V,如果刚好该热点失效,则让一个用户即单线程去数据库中获取,然后再更新缓存,未获取到线程的用户进行排队,再从缓存中进行读取热点K-V,如果缓存更新,则不用再读数据库,如果未更新,则等待一会,循环上述步骤。
static Lock reenLock = new ReentrantLock();
public List<String> getData() throws InterruptedException {
List<String> result = new ArrayList<String>();
// 从缓存读取数据
result = getDataFromCache();
if (result.isEmpty()) {
if (reenLock.tryLock()) {
try {
System.out.println("拿到锁,从数据库中读取数据!");
// 从数据库查询数据
result = getDataFromDB();
// 将查询到的数据写入缓存
setDataToCache(result);
} finally {
reenLock.unlock();// 释放锁
}
} else {
// 再查一下缓存是否有
result = getDataFromCache();
if (result.isEmpty()) {
System.out.println("未拿到锁,等待一会");
Thread.sleep(100);
// 重试
return getData();
}
}
}
return result;
}
并发量较大时,可以用redis分布式锁操作:
public String get(String key){
String value = redis.get(key);
//如果查询不到目标值
if(StringUtils.isNullOrEmpty(value)) {
//其实这是一个加锁的过程
if (redis.setnx(key_mutex,1)==1) {
//从数据库中获取数值
value = getDataFromDB(key);
//再放入缓存中
redis.set(key,value);
//释放锁
redis.del(key_mutex);
} else {
value = redis.get(key);
if(StringUtils.isNullOrEmpty(value)) {
Thread.sleep(100);
return get(key);
}
}
}
return value;
}
2.2 设置永不过期
在商城里面,对于一些爆款,可以设置该产品K-V用不过期,防止出现击穿现象。
总结: 具体使用哪种方式进行处理,还是需要根据具体的业务场景进行设置,并非绝对的。
三、缓存穿透及应对策略
1、定义
缓存穿透是指用户访问缓存时,携带一个缓存中不存在的key,比如说ID为-1.此时在缓存无法找到对应的K-V,则会去数据库中查找。如果此时刚好有大量用户都查找这个key,则相当于穿过或者绕过缓存直接访问数据库,给数据库造成压力。
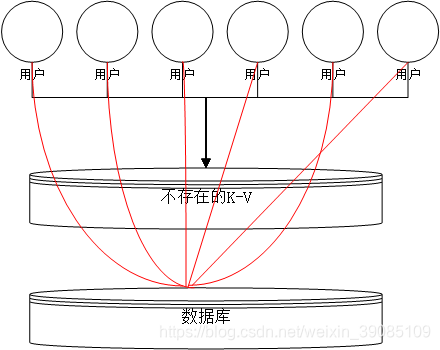
2、应对策略
缓存空对象
简单说,就是当查询的key不存在对应值时,返回一个空值,但是在高并发量时,会存在大量的空值,占用内存空间,此时,我们可以对空值设置过期时间,但是该做法依然存在弊端,在有效期内数据很可能不一致。
布隆过滤器:
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
涉及到具体原理就不讲了,能力有限,自行观看。
数学之美:布隆过滤器
布隆过滤器牛逼地方在于非常高效同时占空间非常少,它判断一个元素不存在那肯定就是不存在,它判断存在的时候有一定误差,是有可能不存在的。比如服务端收到请求之后,可以首先用布隆过滤器判断下用户名是否存在,如果不存在就直接返回,就不用再去查DB了,非常完美的解决方案!
布隆过滤器的具体使用方法就放到其他博客文章进行详细讲解了。
四、雪崩及应对场景
1、定义
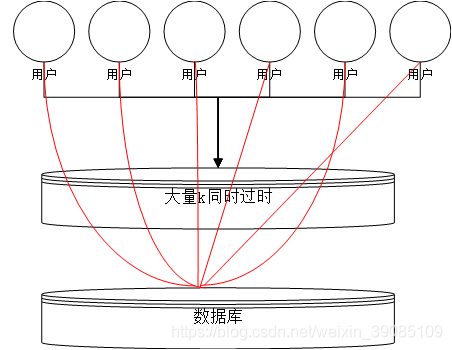
还是可以借鉴之前那个图,但是不同之处就是,在缓存中,同一时刻,存在大量的K-V过期,导致用户直接访问到数据中去了。从而给数据库造成很大的压力,甚至宕机。
2、解决方法
1.缓存数据的过期时间设置为随机
2.针对不同的业务场景设置不同的过期时间加随机时间,比如热点永不过期。