1.虚拟存储器
作用
1.为了给每个进程提供一致的地址空间(都从0开始),方便内存管理。
2.保护每个进程的数据不会因为其它进程而被破坏。
基于以上的原因,有了虚拟存储器,虚拟存储器是在硬盘上的一个文件,例如我们申请20G内存,其实只是在硬盘上创建了一个20g的文件,内存中只会有我们频繁读写的数据,换句话说内存是这个文件的缓存。
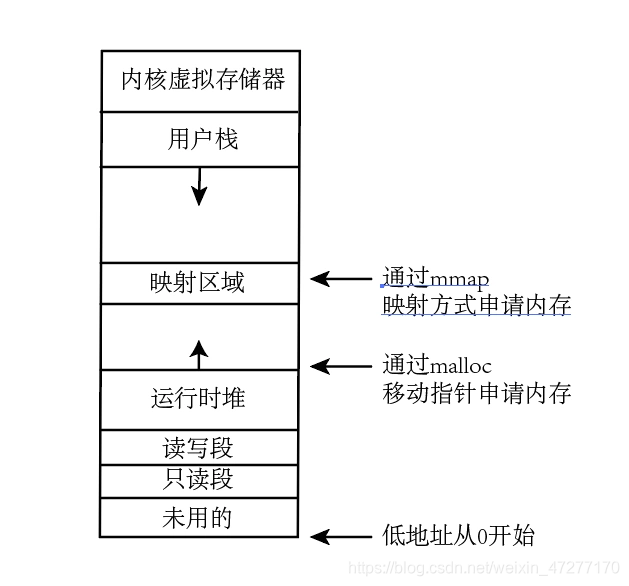
这是一个32操作系统的虚拟存储器图
结构
为了对所有进程一致,下方是低地址从0开始。
堆指针从低地址为向高地址为移动,通过malloc申请内存,通过free释放。一般适合零散内存的申请。
映射区域可以把外部的文件映射到虚拟存储器中,可以实现不同进程的内存共享,但调用成本高,适合大块内存的申请。
管理
1.硬盘到物理内存
内存管理
其实虚拟存储器的内存管理还是要依赖cpu的支持,在上一篇文章中我们提到,cpu为了实现虚拟地址到物理地址的映射,提供了mmu单元,支持多级页表,这就是他支持页式管理的基础。现在高端的cpu一般提供3种内存管理方式,页式管理、段式管理、段页式管理。
页式管理的内存页大小固定(4k),管理简单、没有碎片,但大小不能兼容程序需求。
段式管理大小不固定,可以保证程序一次需要的数据完整加载到物理内存。
段页式管理是页式和段氏管理的结合,段由多个页组成,但查询时需要多次映射才能找到。
linux使用了段页式的管理方式,但对段氏依赖较少,方便兼容不同的cpu,简化管理逻辑。
内存页置换算法
物理内存作为虚拟内存的缓存,肯定需要一个过期策略,常用的策略有FIFO先进先出,LRU最近未使用,LFU最不常用,但这些方法不是效果不好、就是实现成本高所以并未使用到虚拟内存的管理中。
时钟置换算法,每页都会有两个标记,表示最近是否有修改和使用。
每次需要淘汰页时,都会轮训所有页。如果完成一步后淘汰页不够,则继续执行下一步。
第一步,淘汰,未访问、未修改的页。
第二步,有访问、未修改。并把所有页的被访问标记清除。
第三步,未访问、有修改。清除修改标记。
第四步,有访问、有修改。
内存页被淘汰后,如果有修改则需要把数据写回到硬盘,所以叫置换算法。
2.物理内存
内存页因为大小固定、每页有4k大小,我们申请内存不能保证大小一致,所以为了解决这种情况下的内存碎片问题,常用的物理内存管理算法有2种。
1.伙伴算法
负责大块连续内存的分配,以页为最小单位,避免了页外部的碎片。伙伴算法会维护11个链表,对应单个页、连续2个页、连续4个页、连续8个页以此类推。
假设我们申请一个3页大小的内存,伙伴算法会给我分配一个4页大小的块。但当4页的链表中没有空闲时,会从上层8个页中拆成2个4页,然后一个分配给我们使用,一个维护到4页的链表中。
当释放一块内存时,他会和附近的相同大小的内存尝试合并,例如我释放了一个2页的块,相邻的块也是2页大小,也空闲中,就会合并成一个4页的块,然后继续向上合并,直到无法合并。
1.SLAB
slab适合频繁申请释放的小块内存,一个slab分配器对应1页或多页。slab会把内存分成几类大小相同的块,大体可以理解为大中小三类,我们申请内存时分配合适大小的块,释放时也不会像伙伴算法时合并,有些类似内存的缓存池。
3.高速缓存
相比主存的以页为单元的管理方式,高速缓存也采用了类似的方式,但因为高速缓存大小有限,所以我们一般称为行或块,通常64个字节。
高速缓存作为主存的缓存同样需要缓存的加载和淘汰策略,但复杂的淘汰策略成本太高,所以高速缓存和主存之间采用映射的方式。
映射方式

高速缓存由很多行组成,几行为一组,每组映射到物理内存中的一块。从高速缓存中查询数据分为三步,选择组、选择行、选择字。
1.直相连映射
主存的一块只能映象到Cache中指定的一块中,即每组只有1行。
通过简单的取模运算选择组,然后通过比较行标识确定是否命中,命中则再选择所要的字。
例如缓存中是2组每组1行,主存中10块,主存中1-5块只能映射到缓存中第1组,6-10块只能映射到缓存第2组。
直相连每组只有1行,所以就是直接替换,但有个问题,当我们频繁访问同一块内存的不同2行时,会不断的切换高速缓存中行,造成抖动问题。
2.组相连映射
主存的一块只能映象到Cache中指定的一块中,即每组只有多行。
通过直相连的方式选择组,循环行比较行标识确定是否命中。命中则选择字。
组相连一般采用LRU的替换算法。
3.全相连映射
主存中每块都能映射到缓存中的任意一块,即只有1个组。
只有1组无需选择,循环匹配所有行,命中再选择字。
全相连一般也采用LRU的替换算法。
一般L3和主存之间是组相连,L1与L2、L2与L3为直相连、TLB和PTE之间为全相连。
缓存行一致协议
高速缓存中L1、L2为每个核自有,为了保证运算器读取到准确的数据,CPU要维护缓存与主存、每个核的L1和L2之间的一致性。
高速缓存更新
1.写回法
更新缓存中的数据时,并不立刻更新主存,而是等待缓存被替换时再写回主存。
2.全写法
更新缓存中的数据时,同时更新主存。
3.第一次写
第一次更新缓存时写回主存。
MESI协议
高速缓存中每个行都有2bit的标识位
