1 数据类型
1.1 基本数据类型
| Hive数据类型 |
Java数据类型 |
长 |
例子 |
| TINYINT |
byte |
1byte有符号整数 |
20 |
| SMALINT |
short |
2byte有符号整数 |
20 |
| INT |
int |
4byte有符号整数 |
20 |
| BIGINT |
long |
8byte有符号整数 |
20 |
| BOOLEAN |
boolean |
布尔类型,true或者false |
TRUE FALSE |
| FLOAT |
float |
单精度浮点数 |
3.14159 |
| DOUBLE |
double |
双精度浮点数 |
3.14159 |
| STRING |
string |
字符系列。可以指定字符集。可以使用单引号或者双引号 |
‘now is the time’ “for all good men” |
| TIMESTAMP |
时间类型 |
||
| BINARY |
字节数组 |
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
1.2 集合数据类型
| 数据类型 |
描述 |
语法示例 |
| STRUCT(结构体)对象 |
和c语言中的struct类似,都可以通过“点”符号访问元素内容。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过字段.first来引用。 |
struct() |
| MAP 映射 |
MAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过字段名[‘last’]获取最后一个元素 |
map() |
| ARRAY 数组 |
数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过数组名[1]进行引用。 |
Array() |
Hive有三种复杂数据类型ARRAY、MAP 和 STRUCT。ARRAY和MAP与Java中的Array和Map类似,而STRUCT与C语言中的Struct类似,它封装了一个命名字段集合,复杂数据类型允许任意层次的嵌套。
2 建表
2.1 基本语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区
[CLUSTERED BY (col_name, col_name, ...) 分桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] row format delimited fields terminated by “分隔符”
[STORED AS file_format]
[LOCATION hdfs_path]字段说明
(1)CREATE TABLE
创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
(2)EXTERNAL
关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
(3)COMMENT:为表和列添加注释。
(4)PARTITIONED BY创建分区表
(5)CLUSTERED BY创建分桶表
(6)SORTED BY不常用
(7)ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。
SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。
(8)STORED AS指定存储文件类型
常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
(9)LOCATION :指定表在HDFS上的存储位置。
(10)LIKE允许用户复制现有的表结构,但是不复制数据。
2.2 实操案例
注意hive是一个数仓工具,为了分离处理数据的,所以一般在建表的时候都是根据数据的结构特点来进行创建表的!!
数据
1001,联想笔记本,4500,电脑,100,还行
1002,苹果笔记本,14500,电脑,3000,凑合
1003,IBM笔记本,9500,电脑,10,不好用.散热不好,声卡不好
1004,戴尔笔记本,8500,电脑,120,散热不好
1005,小米手机,1500,手机,300,卡顿
1006,华为手机,4500,手机,100,散热不好
1007,苹果手机,5500,手机,110,不能支付
1008,oppo手机,2500,手机,98,没用过
1009,诺基亚手机,500,手机,100,神机
建表语法
create table if not exists tb_product(
id int ,
name string ,
price double ,
cate string COMMENT '类别',
pnum int ,
description string
)
row format delimited fields terminated by "," ;展示数据库中所有的表 show tables ;
0: jdbc:hive2://linux01:10000> show tables ;
+---------------+
| tab_name |
+---------------+
| tb_product |
+---------------+查看表结构 desc tb_product ;
0: jdbc:hive2://linux01:10000> desc tb_product ;
+--------------+------------+----------+
| col_name | data_type | comment |
+--------------+------------+----------+
| id | int | |
| name | string | |
| price | double | |
| cate | string | ?? |
| pnum | int | |
| description | string | |
+--------------+------------+----------+查看表的详细信息 desc formatted tb_product ;
desc formatted tb_product ;
+-------------------------------+----------------------------------------------------+-----------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------------+
| # col_name | data_type | comment |
| | NULL | NULL |
| id | int | |
| name | string | |
| price | double | |
| cate | string | ?? |
| pnum | int | |
| description | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | db_doit15 | NULL |
| Owner: | root | NULL |
| CreateTime: | Wed Jun 17 14:15:29 CST 2020 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://linux01:9000/user/hive/warehouse/db_doit15.db/tb_product | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {\"BASIC_STATS\":\"true\"} |
| | numFiles | 0 |
| | numRows | 0 |
| | rawDataSize | 0 |
| | totalSize | 0 |
| | transient_lastDdlTime | 1592374529 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | , |
| | serialization.format | , |
+-------------------------------+----------------------------------------------------+-----------------------------+3 加载数据
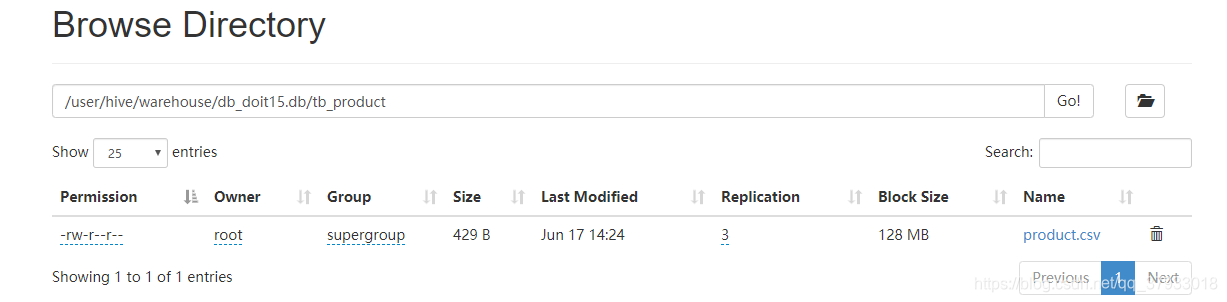
3.1 直接将数据文件上传到对应的表的目录下
在建表的时候没有使用location关键字 ,name表的默认目录在HDFS上的位置如图

直接将文件数据上传到指定的表目录下即可
hdfs dfs -put /hive/product.csv /user/hive/warehouse/db_doit15.db/tb_product/
查询数据
select * from tb_product ;
+----------------+------------------+-------------------+------------------+------------------+-------------------------+
| tb_product.id | tb_product.name | tb_product.price | tb_product.cate | tb_product.pnum | tb_product.description |
+----------------+------------------+-------------------+------------------+------------------+-------------------------+
| 1001 | 联想笔记本 | 4500.0 | 电脑 | 100 | 还行 |
| 1002 | 苹果笔记本 | 14500.0 | 电脑 | 3000 | 凑合 |
| 1003 | IBM笔记本 | 9500.0 | 电脑 | 10 | 不好用.散热不好;声卡不好 |
| 1004 | 戴尔笔记本 | 8500.0 | 电脑 | 120 | 散热不好 |
| 1005 | 小米手机 | 1500.0 | 手机 | 300 | 卡顿 |
| 1006 | 华为手机 | 4500.0 | 手机 | 100 | 散热不好 |
| 1007 | 苹果手机 | 5500.0 | 手机 | 110 | 不能支付 |
| 1008 | oppo手机 | 2500.0 | 手机 | 98 | 没用过 |
| 1009 | 诺基亚手机 | 500.0 | 手机 | 100 | 神机 |
+----------------+------------------+-------------------+------------------+------------------+-------------------------+3.2 使用命令导入本地文件
load data local inpath "本地结构化文件的路径" into table tb_name ;3.3 使用命令导入HDFS文件到表中
load data inpath "本地结构化文件的路径" into table tb_name ;3.4 建表的时候指定表的位置
create table tb_teacher(
name string,
friends array<string>,
children map<string, int>,
address struct<street:string, city:string>
)
row format delimited fields terminated by ','
location "HDFS的路径" ;3.5 覆盖导入
load data local inpath ""overwrite into table tb_name ;3.6 insert 方式
3.6.1 insert into table values ()
0: jdbc:hive2://linux01:10000> insert into tb_insert values(1,'zss') ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (7.525 seconds)
0: jdbc:hive2://linux01:10000> select * from tb_insert ;
+---------------+-----------------+
| tb_insert.id | tb_insert.name |
+---------------+-----------------+
| 1 | zss |
+---------------+-----------------+
1 row selected (0.271 seconds)
0: jdbc:hive2://linux01:10000> insert into tb_insert values(2,'lss') ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (3.023 seconds)
0: jdbc:hive2://linux01:10000> select * from tb_insert ;
+---------------+-----------------+
| tb_insert.id | tb_insert.name |
+---------------+-----------------+
| 1 | zss |
| 2 | lss |
+---------------+-----------------+- insert 语法 不要一条一条数据的insert 因为一次insert在HDFS中生成一个小文件
- insert into tb_name valeus () , () ,() ,()
3.6.2 nsert into tb_name select .... 将后面的select运算结果保存到某个表中
insert into tb_insert2 select id+10 , name from tb_insert ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (3.3 seconds)
0: jdbc:hive2://linux01:10000> select * from tb_insert2 ;
+----------------+------------------+
| tb_insert2.id | tb_insert2.name |
+----------------+------------------+
| 11 | zss |
| 12 | lss |
| 13 | hgy |
| 14 | hgy2 |
| 15 | xiaohu |
+----------------+------------------+3.6.3 insert overwrite table
insert overwrite table tb_insert2 select id+10 , name from tb_insert ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (2.505 seconds)
0: jdbc:hive2://linux01:10000> select * from tb_insert2 ;
+----------------+------------------+
| tb_insert2.id | tb_insert2.name |
+----------------+------------------+
| 11 | zss |
| 12 | lss |
| 13 | hgy |
| 14 | hgy2 |
| 15 | xiaohu |
+----------------+------------------+3.7 create as 将结果数据直接保存在一个新的表中
create table if not exists tb_phone
as select * from tb_product where cate = '手机' ;练习
统计商品表中 每种类别商品的平均价格保存到结果表中
create table tb_prd_avg_pr_bcg
as
select
cate ,
avg(price) as avg_price
from
tb_product
group by cate ;3.8 import 一定是导出的数据才能导入
导出数据到HDFS中
export table tb_product to
'/user/hive/warehouse/export/product';
导入数据方式
import table tb_product2 from
'/user/hive/warehouse/export/product';
4 导出数据
4.1 将数据导出到本地的文件夹中
1) 没有指定数据的分隔符
insert overwrite local directory '/hive/p/'
select * from tb_product;
2) 指定分割符
insert overwrite local directory '/hive/p2/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from tb_product;
4.2 将数据导出到HDFS文件夹中
1) 没有指定数据的分隔符
insert overwrite directory '/hive/p/'
select * from tb_product;
2) 指定分割符
insert overwrite directory '/hive/p2/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from tb_product;
4.3 使用HDFS 提供的命令
1) hdfs dfs -get
2) hive命令行中 dfs -get
hive> dfs -get /user/hive/warehouse/db_doit15.db/tb_phone/000000_0 /hive/phone
4.4 使用 hive命令行
1) hive -e "sql语句"
2) hive -f 文件
使用域shell脚本调度SQL任务的时候使用
可以使用 >> 或者 > 将执行命令的结果保存到指定的文件中
4.5 export 导出数据
(defahiveult)> export table default.student to
'/user/hive/warehouse/export/student';
4.6 数据迁移工具
Sqoop、dataX、Kettle、Canal、StreamSets