网络协议分析与仿真课程设计报告
题 目:网络流量分析与协议模拟
专业名称: 网络工程
班 级:
学生姓名: 阿吉
学号(8位):
指导教师:
设计起止时间:
网络协议分析与仿真课程设计报告
一、课程设计目的
- 加深对IP、DNS 、TCP、UDP、HTTP等协议的理解;
- 掌握流量分析工具的使用,学习基本的流量分析方法。
- 掌握网络模拟工具NS2的使用,学习基本的网络模拟方法。
二、课程设计内容
- 一、协议及流量分析
- 工具:Wireshark(Windows或Linux),tcpdump(Linux)
- 要求:建立包含DNS解析的Web服务网络环境,使用过滤器捕获特定分组,观察PDU;用脚本分析大流量数据(建议用perl);
- 内容:Web流量分析
搭建Web服务器和DNS服务器,要求Web服务器IP地址为“xx.xx.xx.学号的后三位”,要求DNS服务器IP地址为“xx.xx. 学号的后三位. xx”;用Web服务器、DNS服务器及1台客户机构建网络环境;清除客户机DNS缓存,访问Web服务器,捕获访问过程中的所有分组,分析并回答下列问题(以下除1、3、8、11外,要求配合截图回答):
简述访问web页面的过程。
- 在自建的网络环境中用客户机浏览器访问DNS服务器,使用Wireshark捕获数据包,找出DNS解析请求、应答相关分组,传输层使用了何种协议,端口号是多少?所请求域名的IP地址是什么? (可以用终端的NSlookup 命令,如果使用自建的DNS服务器解析Web服务器,可以加分)
- 针对(1)中的DNS访问过程,观察UDP协议的报文格式。
- 在自建的网络环境中用客户机浏览器访问Web服务器,统计访问主页共有多少请求IP分组,多少响应IP分组?(要求编程实现)
- 找到TCP连接建立的三次握手过程,绘出TCP连接建立的时空图,注明每个TCP报文段的序号、确认号、以及SYN\ACK的设置。给出该TCP连接的四元组,双方协商的起始序号;TCP连接建立的过程中,第三次握手是否携带数据,是否消耗序号。
- 在TCP连接的数据传输过程中,找出每一个(客户)发送的报文段与其ACK报文段的对应关系,画出时空图。
- 找到TCP四次挥手释放连接的过程,绘出TCP连接释放的时空图,注明每个TCP报文段的序号、确认号、以及FIN\ACK的设置,说明释放请求由服务器还是客户发起,FIN报文是否携带数据,是否消耗序号,FIN报文段的序号是什么,为什么是这个值。
- 将(3)得到的数据流保存为txt文件,通过编程计算这该TCP通信过程中数据报文段的往返时延RTT(即RTT样本值)。根据《计算机网络》课程课本227-228页相关RTT计算方法,估算每一个数据报文段超时时间RTO。
- 分别找出一个HTTP请求和响应分组,分析其报文格式。参照《计算机网络》课程课本276页图6-11,在截图中标明各个字段。
- 访问同一网站的不同网页,本次访问中的TCP连接是否和上次访问相同?(提示:与上次页面访问时间间隔不能过长,可连续访问、分别分析。)
- 描述HTTP协议的持续连接的两种工作方式。访问这些页面(同一网站的不同页面)的过程中,采用了哪种方式?
- 设计主页和HTTP协议版本,观察IP分片过程。(选作加分项)
- 二、协议模拟
- 工具:NS2,awk,shell,perl等;
- 要求:掌握NS2网络模拟的基本流程;
- 内容:NS2网络模拟基本流程
在ubuntu环境下,通过学习示例文件编写TCL脚本,搭建如下图所示的一个网络,共6个节点,其中2、3节点用做ftp服务器和客户端,4、5节点用做cbr流量的源和目的,而0、1节点用做转发设备。各节点间的链路属性见图。

图1-1
模拟时间设为13秒钟,在0.1秒开始产生cbr流量,在1.0秒开始发送ftp流量;8.0秒ftp流量结束,12.0秒cbr流量结束。编写脚本(可用shell,awk,或perl等)分析模拟日志文件,统计每0.5s内0、1节点间链路通过的分组数以及字节数。
三、 设计与实现过程
- 一、协议及流量分析
(1)在自建的网络环境中用客户机浏览器访问DNS服务器,使用Wireshark捕获数据包,找出DNS解析请求、应答相关分组,传输层使用了何种协议,端口号是多少?所请求域名的IP地址是什么? (可以用终端的NSlookup 命令,如果使用自建的DNS服务器解析Web服务器,可以加分)
Wireshark捕获数据DNS解析请求、应答相关分组:
请求分组:

应答分组:
![]()
传输层使用UDP协议进行传输:
请求端口号为:源端口:51728
目的端口:53
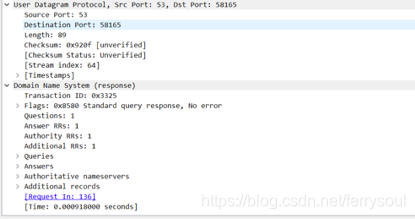
响应端口号为:源端口为:53
目的端口:51728

所请求的域名IP为:192.168.66.66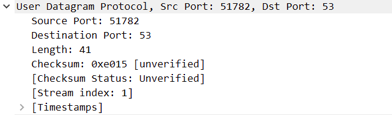

浏览器通过DNS服务器解析IP并访问Web服务器:
(2)针对(1)中的DNS访问过程,观察UDP协议的报文格式。
UDP请求时的UDP报文:
(3)在自建的网络环境中用客户机浏览器访问Web服务器,统计访问主页共有多少请求IP分组,多少响应IP分组?(要求编程实现)
统计python源代码:
import pyshark
i=0
j=0
k=0
a='192.168.128.1'#主机
b='192.168.128.128'#web
c='192.168.128.48'#dns
cap=pyshark.FileCapture("D:/io1/test.pcapng",only_summaries=True)
for pkt in cap:
if pkt.protocol !='ARP':
if pkt.source ==a:
if pkt.destination==b or c:
i=i+1
print( '%s %s ------>%s' %(pkt.protocol,pkt.source ,pkt.destination))
print('从主机发送的IP包个数:')
print(i)
for pkt in cap:
if pkt.protocol !='ARP':
if pkt.source ==b:
j=j+1
print( '%s %s ------>%s' %(pkt.protocol,pkt.source ,pkt.destination))
print('主机接受web服务器发送的IP包个数:')
print(j)
for pkt in cap:
if pkt.protocol !='ARP':
if pkt.source ==c:
if pkt.destination==a:
k=k+1
print( '%s %s ------>%s' %(pkt.protocol,pkt.source ,pkt.destination))
print('主机接受dns服务器发送的IP包个数:')
print(k)
运行结果图:
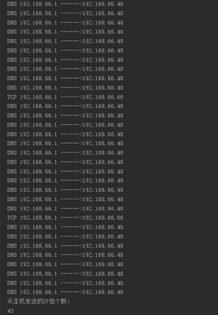
(4)找到TCP连接建立的三次握手过程,绘出TCP连接建立的时空图,注明每个TCP报文段的序号、确认号、以及SYN\ACK的设置。给出该TCP连接的四元组,双方协商的起始序号;TCP连接建立的过程中,第三次握手是否携带数据,是否消耗序号。
三次握手第一次握手的四元组:
三次握手第二次握手的四元组:
看灰色的这一行
![]()
三次握手第三次握手的四元组:
看第三行的灰色行
双方协商的启示序号为sql=0。
第三次握手有携带数据,有消耗序号。
(5)在TCP连接的数据传输过程中,找出每一个(客户)发送的报文段与其ACK报文段的对应关系,画出时空图。
(6)找到TCP四次挥手释放连接的过程,绘出TCP连接释放的时空图,注明每个TCP报文段的序号、确认号、以及FIN\ACK的设置,说明释放请求由服务器还是客户发起,FIN报文是否携带数据,是否消耗序号,FIN报文段的序号是什么,为什么是这个值。

 释放请求是由服务器发起的
释放请求是由服务器发起的
FIN报文携带数据,消耗序号
FIN报文段的序号为180
因为在上一次的客户端TCP报文中的ACK确认号时180
(7)将(3)得到的数据流保存为txt文件,通过编程计算这该TCP通信过程中数据报文段的往返时延RTT(即RTT样本值)。根据《计算机网络》课程课本227-228页相关RTT计算方法,估算每一个数据报文段超时时间RTO。
将Wireshark抓取的数据中的每个RTT数据项字段取出的python代码为:
import pyshark
import re
i=0
j=0
k=0
a='192.168.128.1'#主机
b='192.168.128.128'#web
c='192.168.128.48'#dns
cap=pyshark.FileCapture("D:/io1/test.pcapng",display_filter="tcp")
for pkt in cap:
print("$$$$$$$$$$$$$")
print(pkt)
pkt = str(pkt)
m = re.findall(r'The RTT to ACK the segment was: 0.{1,100} seconds', pkt)
m = str(m)
if m != '[]':
m = re.findall(r'0.{1,10}', m)
m=str(m)
m = re.sub(r'[\[\]\']','',m)
print(m)
f = open('RTT.txt', 'a')
f.write(m+'\n')
f.close()
解析后存储的TXT文件:
RTO的计算公式为
RTO = RTTS+4*RTTD
RTTS=0.875*RTTS+0.125*rtt
RTTD = 0.75*RTTD+0.25*(abs(RTTS-rtt))
根据此公式计算的python代码为:
my_open = open('RTT.txt', 'r')
i=1
j=0
RTTS = 0.0
RTTD = 0.0
for eachline in my_open:
m=eachline.split()
rtt = m[0]
rtt = float(rtt)
if i==1:
RTTS = rtt
RTTD = rtt/2
RTO = RTTS+4*RTTD
RTO = str(RTO)
f = open('RTO.txt', 'a')
f.write(RTO + '\n')
f.close()
else:
RTTS=0.875*RTTS+0.125*rtt
RTTD = 0.75*RTTD+0.25*(abs(RTTS-rtt))
RTO = RTTS + 4 * RTTD
RTO = str(RTO)
f = open('RTO.txt', 'a')
f.write(RTO + '\n')
f.close()
print(m)
print(j)
my_open.close()
计算后得到各个RTO值存为的TXT文件:
(8)分别找出一个HTTP请求和响应分组,分析其报文格式。参照《计算机网络》课程课本276页图6-11,在截图中标明各个字段。
HTTP请求分组截图:
HTTP响应分组截图:
(9)访问同一网站的不同网页,本次访问中的TCP连接是否和上次访问相同?(提示:与上次页面访问时间间隔不能过长,可连续访问、分别分析。)
TCP第一次连接:
TCP第二次连接:
两次时空图比较可得知:
访问同一网站的不同网页其三次握手的大体过程一样。
(10)描述HTTP协议的持续连接的两种工作方式。访问这些页面(同一网站的不同页面)的过程中,采用了哪种方式?
1.非流水线方式:客户在收到前一个响应之后才能发出下一个请求
2.流水线方式:客户在收到HTTP响应报文之前就能够接着发送新的报文请求
流水线工作方式使TCP连接中的空闲时间减少,提高了传输效率
访问这些页面(同一网站的不同页面)的过程中,采用了流水线的方式,在同一网站上的不同引用对象,可以进行连续的请求,不一定非要等到确认报文。
如图是非连续请求截图:
- 二、协议模拟
- 仿真脚本代码与详细注解
#创建模拟器对象
#模拟器对象赋值给变量ns
set ns [new Simulator]
#给NAM定义不同的数据流,颜色的选择随意,易于区分就可以
$ns color 1 Blue
$ns color 2 Red
#打开out.nam文件,一般都是在执行程序时自动生成
set nf [open out.nam w]
$ns namtrace-all $nf
#打开out.tr文件,也是自动生成
set tf [open out.tr w]
$ns trace-all $tf
#两个文件主要都是用来记录封包传输过程的
#定义finish程序,在后面执行时可以用到
proc finish {} {
global ns nf tf
$ns flush-trace
#关闭nam文件
close $nf
#关闭trace文件在后面调用的时候,是在程序结束的时候所以前面生成的两个文件必须要关
close $tf
exec nam out.nam &
exit 0
}
#创建8个节点
set n0 [$ns node]
set n1 [$ns node]
set n2 [$ns node]
set n3 [$ns node]
set n4 [$ns node]
set n5 [$ns node]
set n6 [$ns node]
set n7 [$ns node]

#基于题目要求的基础之上,创建结点之间的链路
$ns duplex-link $n2 $n6 1.5Mb 10ms DropTail
$ns duplex-link $n0 $n2 1.5Mb 10ms DropTail
$ns duplex-link $n0 $n4 1.5Mb 10ms DropTail
$ns duplex-link $n1 $n3 1.5Mb 10ms DropTail
$ns duplex-link $n1 $n5 1.5Mb 10ms DropTail
$ns duplex-link $n5 $n7 1.5Mb 10ms DropTail
$ns duplex-link $n1 $n0 2Mb 20ms DropTail
#给NAM创建节点位置
$ns duplex-link-op $n6 $n2 orient down
$ns duplex-link-op $n2 $n0 orient right-down
$ns duplex-link-op $n4 $n0 orient right-up
$ns duplex-link-op $n0 $n1 orient right
$ns duplex-link-op $n0 $n1 orient right
$ns duplex-link-op $n1 $n3 orient right-up
$ns duplex-link-op $n1 $n5 orient right-down
$ns duplex-link-op $n5 $n7 orient down
#设置n0到n1之间的列长度
$ns queue-limit $n1 $n0 10
# TCP与UDP的建立中,agent是一个代理,用来作为网络层的传输与接收
#建立TCP连接
set tcp [new Agent/TCP]
$tcp set class_ 2
$ns attach-agent $n6 $tcp
set sink [new Agent/TCPSink]
$ns attach-agent $n3 $sink
$ns connect $tcp $sink
$tcp set fid_ 1
#TCP的连接用红色的数据流表示
#建立UDP连接
set udp [new Agent/UDP]
$ns attach-agent $n4 $udp
set null [new Agent/Null]
$ns attach-agent $n3 $null
set null [new Agent/Null]
$ns attach-agent $n7 $null
$ns connect $udp $null
$udp set fid_ 2
#NAM中,UDP的连接用蓝色的数据流表示

#在TCP连接上建立FTP
set ftp [new Application/FTP]
$ftp attach-agent $tcp
$ftp set type_ FTP
 #在UDP连接上建立CBR
#在UDP连接上建立CBR
#设置了cbr流量的包类型,字节大小,以及传输速率
set cbr [new Application/Traffic/CBR]
$cbr attach-agent $udp
$cbr set type_ CBR
$cbr set packet_size_ 2000
$cbr set rate_ 1mb
$cbr set random_ false
#设置FTP和CBR起止时间
#0.1秒产生cbr流量
$ns at 0.1 "$cbr start"
#1.0秒发送ftp流量
$ns at 1.0 "$ftp start"
#8.0秒ftp流量结束
$ns at 8.0 "$ftp stop"
#12.0秒cbr流量结束
$ns at 12.0 "$cbr stop"
#13秒后调用前面写出的finish程序
$ns at 13.0 "finish"
#执行模拟器程序
$ns run
- 仿真过程示意(动画截图1个)
刚开始的时候如图2-1所示,在0.1s的时候发送cbr,cbr基于UDP协议,在1s的时候发送ftp,ftp基于TCP,如图2-2所示,在8s的时候,ftp结束,在12s的时候cbr结束,如图2-3所示。
图2-1
图2-2
图2-3
3.日志分析脚本设计(设计思路与代码、注解)
使用perl命令运行日志分析脚本
设计思路:
首先取出每行的时间、分组大小;
若时间大于当前的时间段,变量加1,开始统计下一时间段信息;
数组count1记录分组的数目
数组count2记录每个时间段通过的分组的总字节数
代码运行结束后的统计结果如图3-1所示:(数据包的折线图在图4-1.4-2)
图3-1
#!/usr/bin/perl
#定义变量i
$i=0;
#定义三个数组
@info;
@count1;
@count2;
#读out.tr文件的内容
while(<>){
#以空格为分字符读取每一行的内容
@info = split(/ +/,$_);
#封包事件发生原因 (r代表封包被接收,+ 表示进入队列,- 表示离开队列)
$reason = $info[0];
#时间,表示流量传输的开始时间
$time = $info[1];
#封包的起始节点
$src = $info[2];
#封包的终止节点
$dst = $info[3];
#包的字节长度
$length = $info[5];
#包被某个节点所接受,而且链路传输是在从0到1的链路上,判断语句
if($reason==‘r’ && ($src==0 && $dst==1) || ($src==1 && $dst==0)){
if($time > $i*0.5){ /时间段超过0.5秒,执行下一行内容
$i++;
}
$count1[$i]++; /这个数组用于统计包的个数
$count2[$i]+=$length; /这个数组用于统计字节数
}
}
#显示语句,显示内容为:时间间隔,包,还有字节数
printf("intervals(s)\t\tpackets\t\tbytes\n");
$i=1.0;
#显示统计出来的每个时间段的信息
while($count1[$i]){
printf("%4.1f~%4.1f\t\t$count1[$i]\t\t$count2[$i]\n",($i-1)*0.5,$i*0.5,);
$i++;
}
- 分析结果展示(通过自绘图来说明)
代码的数据截图在图3-1
图4-1
刚开始的时候,在0.1s的时候发送cbr,cbr基于UDP协议,在1s的时候发送ftp,ftp基于TCP,在8s的时候,ftp结束,在12s的时候cbr结束,12.5秒的时候程序已经结束了。
四、 设计技巧及体会
1、对自己设计进行评价,指出合理和不足之处,提出改进的方案。
这次实验因为之前有一定的计算机网络实验课的基础,所以整体感觉不是很难,但是东西很多,比较繁琐,需要耐心弄一下。
本次进行实验的过程中,由于使用的是Linux虚拟机,因此经常会出一些虚拟机常见的问题,总体来说,还是解决了问题,并且完成了实验,但是,我接下来会尝试改进一下,使用PC机上的Linux操作系统来进行一次实验,看一下和虚拟机有什么不同。
在进行wireshark抓包时,由于访问的网页的数据量较小,没有好好的进行网页的设计和数据量的增大,因此没有观察到IP的分片操作,改进之处:可以尝试加大数据量,使一次IP无法传输,必须使用IP分片,因此来观察IP分片操作。
在进行协议模拟时,代码编写不是太规范,因此可以改进一下代码的编写规范,使其变的更加完美。+
2、在设计过程中的感受。
在进行流量分析时,当时需要自己在Linux操作系统中搭建一个web和一个dns服务器,在当时搭建时,遇到了很多问题,但最后全部解决掉了,也因此让我学会了使用CentOS来进行WEB站点的搭建,并且在CentOS中使用Bind来进行DNS服务器的搭建,了解了在Linux操作系统中web和dns服务器在其中的文件位置和两个服务器的工作流程以及dns服务器的文件配置格式,和在Windows中使用nslookup来进行dns服务器的测试。
在协议模拟中,学会了使用仿真工具在其中进行编程来进行协议的仿真,不但学会了如何使用仿真工具,而且也学会了在其中编程,并运行自己编写的程序,最后还学到了对自己编写的仿真程序进行测试。
第二个实验感觉还是挺难的,尤其是自己写代码的时候,一直在百度各种坑,然后不断改,现在回首一下的话,感觉还是比较简单了。同时,自己掌握了一项新技能,还是很开心的。老师帮助着指点着这次实验中出现的问题,提出一个解决的方向,然后我去更改代码。最终比较完美的完成了实验。