简介
- 这里主要介绍PaddleClas中已经开源的常用系列模型,PaddleClas的github repo:https://github.com/PaddlePaddle/PaddleClas。
- PaddleClas中包含了ResNet、HRNet、Inception、Res2Net等系列模型,这篇博客主要是介绍其主要系列模型。
- AlexNet、VGG这些网络其实都属于十分经典的网络,但是由于这些网络最近用的已经越来越少了,因此在这里也没有进行展开。
ResNet系列
- 之前的深度神经网络,比如AlexNet、VGG等等,其实已经对传统的图像分类方法形成了一次降维打击,而ResNet则是对其之前的深度神经网络再次形成了降维打击;基于一个152层的ResNet模型,它把ImageNet上的识别错误率再次降低了几乎一半。其核心结构就是右边所示的残差块,网络只需要学习残差项,这解决了之前过深的网络在训练时难以收敛的问题。

上面这张图其实也就是给出了ILSVRC图像分类数据集的top-1 error指标,resnet出来时,远超其他模型的结果。
-
下面给出了ResNet的核心结构:残差模块
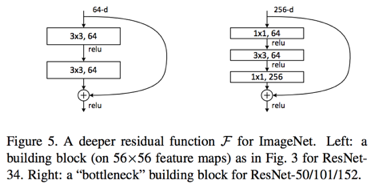
-
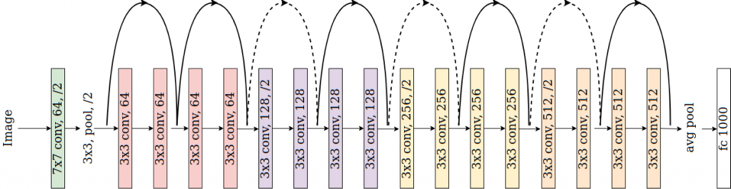
在残差结构中,一个支路经过各种卷积运行,另一个支路直接连接到输出,这两个支路相加之后得到输出,相当于卷积计算的支路只需要计算残差项,这大大降低了模型训练过程中的学习难度。下面也给出了ResNet18的结构。
- 上面是标准的ResNet结构,李沐大神及其团队在后来对ResNet做了一系列的改进。下面给出了最左边是最开始的ResNet-Va结构,Vb对这个左边的特征变换通路的降采样卷积做了调整,把降采样的步骤从最开始的第一个1x1卷积调整到中间的3x3卷积中;Vc结构则是将最开始这个7x7的卷积变成3个3x3的卷积,在感受野不变的情况下减少了存储;而Vd是修改了降采样残差模块右边的特征通路。把降采样的过程由平均池化这个操作去替代了,这一系列的改进,几乎没有带来新增的预测耗时,结合适当的训练策略,比如说标签平滑以及mixup这种数据增广方式,精度可以提升高达2.5%。

更多关于改进结构的描述,可以参考这篇论文:https://arxiv.org/abs/1812.01187
ResNet改进版-ResNeXt、SENet、Res2Net等
- 之前的残差结构中,在bottleneck计算部分,输入是全部经过一个统一的转换过程,而ResNeXt中,作者是将输入拆分为多个分支,让特征之间相互解耦,每个分支都采用相同的拓扑结构进行计算,最终聚合得到输出;而SENEt则是考虑到了不同特征点的重要程度并不相同,网络需要去学习并强化重要的特征,而弱化非重要的特征,这也就是我们常说的注意力机制。SENet中是引入了一个额外分支,去计算特征图中的每个点的重要程度,从而实现刚才说的区分重要和非重要的特征。Res2Net则是在残差结构中添加了类似残差的结构,融合多尺度的特征,增加了每个网络层的感受野,从而使得网络可以很好地处理多尺度的图像分类问题。
- 下面给出了这3个结构的核心特征:

下面这个图给出了刚才介绍的这些模型的预测速度和精度曲线,结合适当的训练策略,ResNet_vd的优势还是比较明显的,当然,在完全相同的情况下,vd结构的ResNet50比vb结构的ResNet在imagenet1k数据集上的精度高0.6%左右,而且预测耗时基本没有增加,算是比较明显的改进了。

HRNet
- 直接放图,下面给出了HRNet的结构,最主要的特点就是在网络不断变深的时候,高分辨率的特征仍然会一直保留(最上面的黄色特征通路),然后隔一段就将深层特征和高分辨率特征融合一下,这样的话,网络会一直同时带有高分辨率特征和深层特征,在一些对分辨率要求很高的任务里表现是十分出色的,可以说是网络深度和分辨率兼得的典型网络设计案例了。

- 当时这个HRNet网络出来时,在coco数据集的关键点检测、姿态估计、多人姿态估计这三项任务中,HRNet超越了所有的之前的模型,可以说是将其优势彰显得淋漓尽致了。
- 下面给出了HRNet的预测速度和精度曲线,精度比resnet稍微好一些,但是预测耗时也增加得比较明显,在一些对分辨率要求比较高的任务里,还是十分值得一是的。

EfficientNet以及ResNeXt_wsl系列
- EfficientNet是google公布的一个新的网络结构,当时这个网络出来的时候,基本上是吊打了所有其他的网络。这个EfficientNet在设计时,主要是考虑到了网络深度、宽度以及图像分辨率的这三个方面的平衡,最终衍生出了从小到大共有8个网络,满足绝大部分的应用场景。
- ResNeXt之前已经有过介绍,这个wsl指的是弱监督学习,Facebook通过弱监督学习研究了该系列网络在ImageNet上的精度上限,采用了9.4亿的弱标签图片进行训练,同时使用ImageNet1k数据进行微调,将网络宽度进一步放大,最终在224的图像输入分辨率下,精度可达85.4%,这也是目前该尺度下精度最高的分类网络。
- 这个图中的32x16d的模型精度为84.2%,同时它的计算耗时相对其他更大的模型结构来说也是可以接受的。
