项目背景介绍
根据淘宝 2016 年的数据分析,淘宝卖家已经达到 900 多万,有上十亿的商品。每一个商品有包括 大量的图片和文字(平均:15k),粗略估计下,数据所占的存储空间在 1PB 以上,如果使用单块容 量为 1T 容量的磁盘来保存数据,那么也需要 1024x1024 块磁盘来保存.
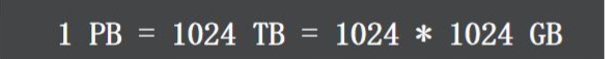
注意
并不是把一块一块的硬盘放在一起就可以组成容量大的内存的,小型机做处理,了解一下 EMC.一般TB级别以上的都要百万级别的小型级的。
思考?
这么大的数据量,应该怎么保存呢?就保存在普通的单个文件中或单台服务器中吗?显然 是不可行。
设计思路
以 block 文件的形式存放数据文件(一般 64M 一个 block),以下简称为“块”,每个块都有唯一的一个 整数编号,块在使用之前所用到的存储空间都会预先分配和初始化。(通过一个脚本实现)
每一个块由一个索引文件、一个主块文件和若干个扩展块组成,“小文件”主要存放在主块中,扩 展块主要用来存放溢出的数据。
每个索引文件存放对应的块信息和“小文件”索引信息,索引文件会在服务启动是映射(mmap)到 内存,以便极大的提高文件检索速度。“小文件”索引信息采用在索引文件中的数据结构哈希链表 来实现。
可以通过提高哈希桶的数量来提高算法的执行效率。
每个文件有对应的文件编号,文件编号从 1 开始编号,依次递增,同时作为哈希查找算法的 Key 来 定位“小文件”在主块和扩展块中的偏移量。文件编号+块编号 按某种算法可得到“小文件”对应的文件名
 这里的哈希表索引块的数据结构,我们已经在上一篇的博客中模拟的实现了 这里 我们就不在探讨了
这里的哈希表索引块的数据结构,我们已经在上一篇的博客中模拟的实现了 这里 我们就不在探讨了