目录
一. 概述
随着微服务的兴起,我司也逐渐加入了微服务的改造浪潮中。但是,随着微服务体系的发展壮大,越来越多的问题暴露出来。其中,测试环境治理,一直是实施微服务的痛点之一,它的痛主要体现在环境管理困难,应用部署困难,技术方案配合等。最终,基于我司的实际情况,基于注册中心nacos实现的智能路由有效地解决了这个问题。本文主要介绍我司在测试环境治理方面遇到的难题与对应的解决方案。
二. 遇到的问题
1. 困难的环境管理与应用部署
随着公司业务发展,业务逐渐复杂化。这在微服务下带来的一个问题就是服务的不断激增,且增速越来越快。而在这种情况下,不同业务团队如果想并行开发的话,都需要一个环境。假设一套完整环境需要部署1k个服务,那么n个团队就需要部署n*1k个服务,这显然是不能接受的。
2. 缺失的技术方案
从上面的分析可以看出,一个环境部署全量的服务显然是灾难性的。那么就需要有一种技术方案,来解决应用部署的难题。最直接的一个想法就是,每个环境只部署修改的服务,然后通过某种方式,实现该环境的正常使用。当然,这也是我们最终的解决方案。下面会做一个介绍。
3. 研发问题
除了这两个大的问题,还有一些其他的问题也急需解决。包括后端多版本并行联调和前后端联调的难题。下面以实际的例子来说明这两个问题。
<1> 后端多版本并行联调难
某一个微服务,有多个版本并行开发时,后端联调时调用容易错乱。例如这个例子,1.1版本的服务A需要调用1.1版本的服务B,但实际上能调用到吗???
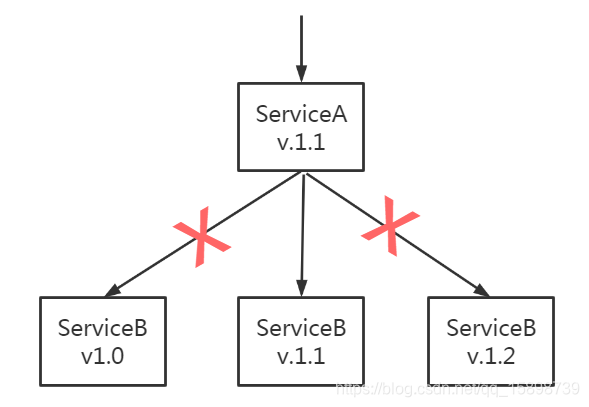
目前使用的配置注册中心是nacos,nacos自身有一套自己的服务发现体系,但这是基于namespace和group的同频服务发现,对于跨namespace的服务,它就不管用了。
<2> 前后端联调难
前端和后端的联调困难,这个问题也是经常遇到的。主要体现在,后端联调往往需要启动多个微服务(因为服务的依赖性)。而前端要对应到某一个后端,也需要特殊配置(比如指定ip等)。下面这个例子,后端人员开发服务A,但却要启动4个服务才能联调。因为服务A依赖于服务B,C,D。
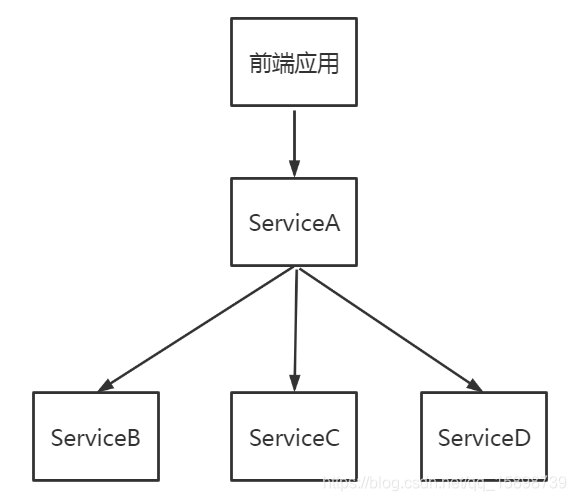
4. 其他问题
除了以上的问题外,还有一些小的问题也可以关注下:
<1> 测试环境排查问题
这个问题不算棘手,登录服务器查看日志即可。但是能否再灵活点,比如让开发人员debug或者在本地调试问题呢?
<2> 本地开发
本地开发,后端往往也依赖多个服务,能不能只启动待开发的服务,而不启动其他旁路服务呢?
三. 智能路由的实现
基于这些需求,智能路由应运而生。它正是为了解决这个问题。最终,我们通过它解决了测试环境治理的难题。
智能路由,能根据不同环境,不同用户,甚至不同机器进行精确路由。下面以一个例子说明。
三个团队,team1,team2和team3各负责不同的业务需求。其中team1只需要改动A服务,team2只需要改动B服务,team3需要在qa环境上验证。通过智能路由,team1,team2只在自己的环境上部署了增量应用,然后在访问该环境的时候,当找不到对应环境的服务时,就从基准环境上访问。而team3只做qa,因此直接访问基准环境即可。可以看到,基准环境上部署了全量服务,除此之外,其他小环境都是增量服务。
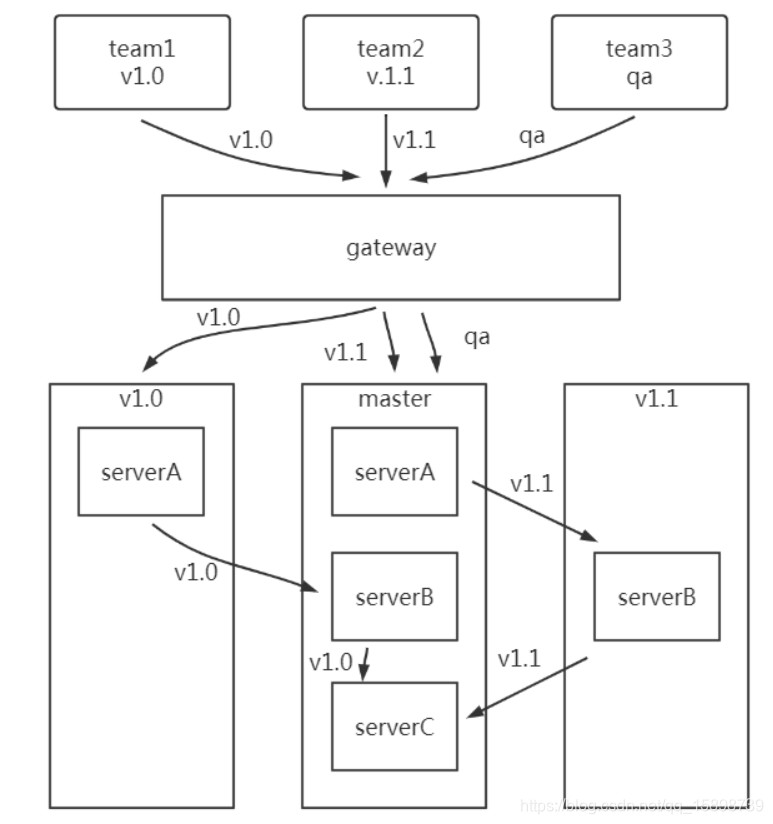
下面介绍智能路由的具体实现方案。
1. 原理
通过上图,可以看到,智能路由其实就是流量染色加上服务发现。
流量染色:将不同团队的流量进行染色,然后透传到整个链路中。
服务发现:注册中心提供正确的服务发现,当在本环境发现不到待调用的服务时,自动访问基准环境的服务。
通过流量染色,区分出哪些流量是哪些团队的,从而在服务发现时,能正确调用到正确的服务。
另外,我司使用的注册中心是nacos,因此本文将主要介绍基于nacos的智能路由实现,其他注册中心同理,做相应改造即可。
2. 具体实现
<1> 流量染色
智能路由的第一步,就是要做流量的染色,将流量能够沿着链路一直透传下去。那么就需要找到流量的入口,然后在入口处进行染色。下图是网站的内部调用情况,可以看到,流量从Nginx进来,最终打到服务集群,因此需要对Nginx进行染色。
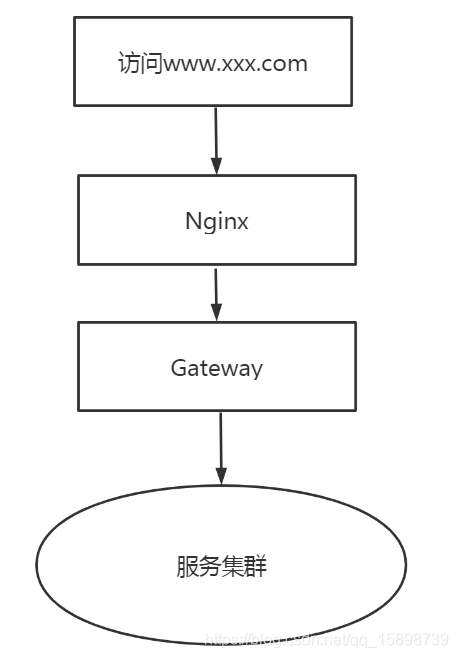
流量染色主要是在流量的头部加上一些标记,以便识别。这里利用了Nginx的proxy_set_header,我们通过下列方式来设置头部。
## nginx的匹配规则设置header
proxy_set_header req_context "{'version': '1.0'}"这样子,我们就为版本是1.0的流量设置了头部,其中的参数可以任意添加,这里仅列举最重要的一个参数。
另外,还有一个问题,流量只有从Nginx进来,才会带上这个头部。如果是在内部直接访问某个中间的服务,那么这个时候流量是没有头部的。对此,我们的解决方案是filter,通过filter可以动态地拦截请求,修改请求头部,为其初始化一个默认值。
public class FlowDyeFilter implements Filter {
@Override
public void doFilter(ServletRequest servletRequest, ServletResponse servletResponse, FilterChain filterChain) throws IOException, ServletException {
//1. 获取servletrequest
HttpServletRequest request = (HttpServletRequest)servletRequest;
//2. 获取请求头部
String context = request.getHeader(ContextUtil.REQUEST_CONTEXT);
//3. 初始化请求上下文,如果没有,就进行初始化
initContext(context);
try {
filterChain.doFilter(servletRequest, servletResponse);
} finally {
ContextUtil.clear();
}
}
public void initContext(String contextStr) {
//json转object
Context context = JSONObject.parseObject(contextStr, GlobalContext.class);
//避免假初始化
if (context == null) {
context = new Context();
}
//这里进行初始化,如果没值,设置一个默认值
if (StringUtils.isEmpty(context.getVersion())) {
context.setVersion("master");
}
...
//存储到上下文中
ContextUtil.setCurrentContext(context);
}
}
通过这个filter,保证了在中间环节访问时,流量仍然被染色。
<2> 流量透传
流量在入口被染色后,需要透传到整个链路,因此需要对服务做一些处理,下面分几种情形分别处理。
1~ Spring Cloud Gateway
对于Gateway,保证请求在转发过程中的header不丢,这个是必要的。这里通过Gateway自带的GlobalFilter来实现,代码如下:
public class WebfluxFlowDyeFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1. 获取请求上下文
String context = exchange.getRequest().getHeaders().getFirst(ContextUtil.REQUEST_CONTEXT);
//2. 构造ServerHttpRequest
ServerHttpRequest serverHttpRequest = exchange.getRequest().mutate().header(ContextUtil.REQUEST_CONTEXT, context).build();
//3. 构造ServerWebExchange
ServerWebExchange serverWebExchange = exchange.mutate().request(serverHttpRequest).build();
return chain.filter(serverWebExchange).then(
Mono.fromRunnable( () -> {
ContextUtil.clear();
})
);
}
}
2~ SpringCloud:Feign
这一类也是最常用的,SC的服务集群都通过Feign进行交互,因此只需要配置Feign透传即可。在这里,我们利用了Feign自带的RequestInterceptor,实现请求拦截。代码如下:
@Configuration
public class FeignAutoConfiguration {
@Bean
public RequestInterceptor headerInterceptor() {
return requestTemplate -> {
setRequestContext(requestTemplate);
};
}
private void setRequestContext(RequestTemplate requestTemplate) {
Context context = ContextUtil.getCurrentContext();
if (context != null) {
requestTemplate.header(ContextUtil.REQUEST_CONTEXT, JSON.toJSONString(ContextUtil.getCurrentContext()));
}
}
}3~ HTTP
最后一类,也是用得最少的一类,即直接通过HTTP发送请求。比如CloseableHttpClient,RestTemplate。解决方案直接见代码:
//RestTemplate
HttpHeaders headers = new HttpHeaders();
headers.set(ContextUtil.REQUEST_CONTEXT,JSONObject.toJSONString(ContextUtil.getCurrentContext()));
//CloseableHttpClient
HttpGet httpGet = new HttpGet(uri);
httpGet.setHeader(ContextUtil.REQUEST_CONTEXT,JSONObject.toJSONString(ContextUtil.getCurrentContext()));只需要粗暴地在发送头部中增加header即可,而其请求上下文直接通过当前线程上下文获取即可。
<3> 配置负载规则
完成了流量染色,下面就差服务发现了。服务发现基于注册中心nacos,因此需要修改负载规则。在这里,我们配置Ribbon的负载规则,修改为自定义负载均衡器NacosWeightLoadBalancerRule。
@Bean
@Scope("prototype")
public IRule getRibbonRule() {
return new NacosWeightLoadBalancerRule();
}public class NacosWeightLoadBalancerRule extends AbstractLoadBalancerRule {
@Override
public Server choose(Object o) {
DynamicServerListLoadBalancer loadBalancer = (DynamicServerListLoadBalancer) getLoadBalancer();
String name = loadBalancer.getName();
try {
Instance instance = nacosNamingService.getInstance(name);
return new NacosServer(instance);
} catch (NacosException ee) {
log.error("请求服务异常!异常信息:{}", ee);
} catch (Exception e) {
log.error("请求服务异常!异常信息:{}", e);
}
return null;
}
}从代码中可以看到,最终通过nacosNamingService.getInstance()方法获取实例。
<4> 配置智能路由规则
上面的负载规则,最终调用的是nacosNamingService.getInstance()方法,该方法里面定义了智能路由规则,主要功能是根据流量进行服务精准匹配。
规则如下:
1~开关判断:是否开启路由功能,没有则走nacos默认路由。
2~获取实例:根据流量,获取对应实例。其中,路由匹配按照一定的优先级进行匹配。
路由规则:IP优先 > 环境 + 组 > 环境 + 默认组
解释一下这个规则,首先是获取实例,需要先获取nacos上面的所有可用实例,然后遍历,从中选出一个最合适的实例。
然后IP优先的含义是,如果在本地调试服务,那么从本地直接访问网站,请求就会优先访问本地服务,那么就便于开发人员调试了,debug,本地开发都不是问题了!
其实是,环境 + 组,这个规则代表了如果存在对应的环境和组都相同的服务,那作为最符合的实例肯定优先返回,其实是环境 + 默认组,最后如果都没有,就访问基准环境(master)。
注:环境和组的概念对应nacos上的namespace和group,如有不懂,请自行查看nacos官方文档。
最终代码如下:
public class NacosNamingService {
public Instance getInstance(String serviceName, String groupName) throws NacosException {
//1. 判断智能路由开关是否开启,没有走默认路由
if (!isEnable()) {
return discoveryProperties.namingServiceInstance().selectOneHealthyInstance(serviceName, groupName);
}
Context context = ContextUtil.getCurrentContext();
if (Context == null) {
return NacosNamingFactory.getNamingService(CommonConstant.Env.MASTER).selectOneHealthyInstance(serviceName);
}
//2. 获取实例
return getInstance(serviceName, context);
}
public Instance getInstance(String serviceName, Context context) throws NacosException {
Instance envAndGroupInstance = null;
Instance envDefGroupInstance = null;
Instance defaultInstance = null;
//2.1 获取所有可以调用的命名空间
List<Namespace> namespaces = NacosNamingFactory.getNamespaces();
for (Namespace namespace : namespaces) {
String thisEnvName = namespace.getNamespace();
NamingService namingService = NacosNamingFactory.getNamingService(thisEnvName);
List<Instance> instances = new ArrayList<>();
List<Instance> instances1 = namingService.selectInstances(serviceName, true);
List<Instance> instances2 = namingService.selectInstances(serviceName, groupName, true);
instances.addAll(instances1);
instances.addAll(instances2);
//2.2 路由匹配
for (Instance instance : instances) {
// 优先本机匹配
if (instance.getIp().equals(clientIp)) {
return instance;
}
String thisGroupName = null;
String thisServiceName = instance.getServiceName();
if (thisServiceName != null && thisServiceName.split("@@") != null) {
thisGroupName = thisServiceName.split("@@")[0];
}
if (thisEnvName.equals(envName) && thisGroupName.equals(groupName)) {
envAndGroupInstance = instance;
}
if (thisEnvName.equals(envName) && thisGroupName.equals(CommonConstant.DEFAULT_GROUP)) {
envDefGroupInstance = instance;
}
if (thisEnvName.equals(CommonConstant.Env.MASTER) && thisGroupName.equals(CommonConstant.DEFAULT_GROUP)) {
defaultInstance = instance;
}
}
}
if (envAndGroupInstance != null) {
return envAndGroupInstance;
}
if (envDefGroupInstance != null) {
return envDefGroupInstance;
}
return defaultInstance;
}
@Autowired
private NacosDiscoveryProperties discoveryProperties;
}<5> 配置智能路由定时任务
刚才在介绍智能路由的匹配规则时,提到“获取所有可以调用的命名空间”。这是因为,nacos上可能有很多个命名空间namespace,而我们需要把所有namespace上的所有可用服务都获取到,而nacos源码中,一个namespace对应一个NamingService。因此我们需要定时获取nacos上所有的NamingService,存储到本地,再通过NamingService去获取实例。因此我们的做法是,配置一个监听器,定期监听nacos上的namespace变化,然后定期更新,维护到服务的内部缓存中。代码如下:
Slf4j
@Configuration
@ConditionalOnRouteEnabled
public class RouteAutoConfiguration {
@Autowired(required = false)
private RouteProperties routeProperties;
@PostConstruct
public void init() {
log.info("初始化智能路由!");
NacosNamingFactory.initNamespace();
addListener();
}
private void addListener() {
int period = routeProperties.getPeriod();
NacosExecutorService nacosExecutorService = new NacosExecutorService("namespace-listener");
nacosExecutorService.execute(period);
}
}
public static void initNamespace() {
ApplicationContext applicationContext = SpringContextUtil.getContext();
if (applicationContext == null) {
return;
}
String serverAddr = applicationContext.getEnvironment().getProperty("spring.cloud.nacos.discovery.server-addr");
if (serverAddr == null) {
throw new RuntimeException("nacos地址为空!");
}
String url = serverAddr + "/nacos/v1/console/namespaces?namespaceId=";
RestResult<String> restResult = HttpUtil.doGetJson(url, RestResult.class);
List<Namespace> namespaces = JSON.parseArray(JSONObject.toJSONString(restResult.getData()), Namespace.class);;
NacosNamingFactory.setNamespaces(namespaces);
}public class NacosExecutorService {
public void execute(int period) {
executorService.scheduleWithFixedDelay(new NacosWorker(), 5, period, TimeUnit.SECONDS);
}
public NacosExecutorService(String name) {
executorService = Executors.newScheduledThreadPool(Runtime.getRuntime().availableProcessors(), new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread t = new Thread(r);
t.setName("jdh-system-" + name);
t.setDaemon(true);
return t;
}
});
}
final ScheduledExecutorService executorService;
}四. 遇到的难点
下面是智能路由实现过程,遇到的一些问题及解决方案。
问题1:namespace启动了太多线程,导致线程数过大?
因为服务需要维护过多的namespace,每个namespace内部又启动多个线程维护服务实例信息,导致服务总线程数过大。
解决方案:每个namespace设置只启动2个线程,通过下列参数设置:
properties.setProperty(PropertyKeyConst.NAMING_CLIENT_BEAT_THREAD_COUNT, "1");
properties.setProperty(PropertyKeyConst.NAMING_POLLING_THREAD_COUNT, "1");问题2:支持一个线程调用多个服务?
每个请求都会创建一个线程,这个线程可能会调用多次其他服务。
解决方案:既然调用多次,那就创建上下文,并保持上下文,调用结束后再清除。见代码:
try {
filterChain.doFilter(servletRequest, servletResponse);
} finally {
ContextUtil.clear();
}问题3:多应用支持:Tomcat,Springboot,Gateway?
我们内部有多种框架,如何保证这些不同框架服务的支持?
解决方案:针对不同应用,开发不同的starter包。
问题4:SpringBoot版本兼容问题
解决方案:针对1.x和2.x单独开发starter包。
五. 带来的收益
1. 经济价值
同样的资源,多部署了n套环境,极大提高资源利用率。(毕竟增量环境和全量环境的代价还是相差很大的)
2. 研发价值
本地开发排查测试问题方便,极大提高研发效率。前面提到的IP优先规则,保证了这一点。本地请求总是最优先打到本地上。
3. 测试价值
多部署n套环境,支持更多版本,提高测试效率。同时只需要部署增量应用,也提高部署效率。
六. 总结
通过智能路由,我司实现了部署成本大幅减少,部署效率大幅提高,研发测试效率大幅提高。
最后总结下智能路由的主要功能:
1. 多环境管理:支持多环境路由,除了基准环境外,其他环境只部署增量应用。
2. 多用户支持:支持多用户公用一套环境,避免开发不同版本造成的冲突。
3. 前端研发路由:对前端研发人员,可以方便快捷地同一个任意后端人员对接。
4. 后端研发路由:对后端研发人员,无论什么环境都可以快速调试,快速发现问题。
5. 友好且兼容:对微服务无侵入性,且支持 Web、WebFlux、Tomcat等应用。